如何计算两个文档的相似度(二)
上一节我们介绍了一些背景知识以及gensim , 相信很多同学已经尝试过了。这一节将从gensim最基本的安装讲起,然后举一个非常简单的例子用以说明如何使用gensim,下一节再介绍其在课程图谱上的应用。
二、gensim的安装和使用
1、安装
gensim依赖NumPy和SciPy这两大Python科学计算工具包,一种简单的安装方法是pip install,但是国内因为网络的缘故常常失败。所以我是下载了gensim的源代码包安装的。gensim的这个官方安装页面很详细的列举了兼容的Python和NumPy, SciPy的版本号以及安装步骤,感兴趣的同学可以直接参考。下面我仅仅说明在Ubuntu和Mac OS下的安装:
1)我的VPS是64位的Ubuntu 12.04,所以安装numpy和scipy比较简单”sudo apt-get install python-numpy python-scipy”, 之后解压gensim的安装包,直接“sudo python setup.py install”即可;
2)我的本是macbook pro,在mac os上安装numpy和scipy的源码包废了一下周折,特别是后者,一直提示fortran相关的东西没有,google了一下,发现很多人在mac上安装scipy的时候都遇到了这个问题,最后通过homebrew安装了gfortran才搞定:“brew install gfortran”,之后仍然是“sudo python setpy.py install” numpy 和 scipy即可;
2、使用
gensim的官方tutorial非常详细,英文ok的同学可以直接参考。以下我会按自己的理解举一个例子说明如何使用gensim,这个例子不同于gensim官方的例子,可以作为一个补充。上一节提到了一个文档:Latent Semantic Indexing (LSI) A Fast Track Tutorial , 这个例子的来源就是这个文档所举的3个一句话doc。首先让我们在命令行中打开python,做一些准备工作:
>>> from gensim import corpora, models, similarities
>>> import logging
>>> logging.basicConfig(format=’%(asctime)s : %(levelname)s : %(message)s’, level=logging.INFO)
然后将上面那个文档中的例子作为文档输入,在Python中用document list表示:
>>> documents = ["Shipment of gold damaged in a fire",
... "Delivery of silver arrived in a silver truck",
... "Shipment of gold arrived in a truck"]
正常情况下,需要对英文文本做一些预处理工作,譬如去停用词,对文本进行tokenize,stemming以及过滤掉低频的词,但是为了说明问题,也是为了和这篇”LSI Fast Track Tutorial”保持一致,以下的预处理仅仅是将英文单词小写化:
>>> texts = [[word for word in document.lower().split()] for document in documents]
>>> print texts
[['shipment', 'of', 'gold', 'damaged', 'in', 'a', 'fire'], ['delivery', 'of', 'silver', 'arrived', 'in', 'a', 'silver', 'truck'], ['shipment', 'of', 'gold', 'arrived', 'in', 'a', 'truck']]
我们可以通过这些文档抽取一个“词袋(bag-of-words)“,将文档的token映射为id:
>>> dictionary = corpora.Dictionary(texts)
>>> print dictionary
Dictionary(11 unique tokens)
>>> print dictionary.token2id
{‘a’: 0, ‘damaged’: 1, ‘gold’: 3, ‘fire’: 2, ‘of’: 5, ‘delivery’: 8, ‘arrived’: 7, ‘shipment’: 6, ‘in’: 4, ‘truck’: 10, ‘silver’: 9}
然后就可以将用字符串表示的文档转换为用id表示的文档向量:
>>> corpus = [dictionary.doc2bow(text) for text in texts]
>>> print corpus
[[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)], [(0, 1), (4, 1), (5, 1), (7, 1), (8, 1), (9, 2), (10, 1)], [(0, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (10, 1)]]
例如(9,2)这个元素代表第二篇文档中id为9的单词“silver”出现了2次。
有了这些信息,我们就可以基于这些“训练文档”计算一个TF-IDF“模型”:
>>> tfidf = models.TfidfModel(corpus)
2013-05-27 18:58:15,831 : INFO : collecting document frequencies
2013-05-27 18:58:15,881 : INFO : PROGRESS: processing document #0
2013-05-27 18:58:15,881 : INFO : calculating IDF weights for 3 documents and 11 features (21 matrix non-zeros)
基于这个TF-IDF模型,我们可以将上述用词频表示文档向量表示为一个用tf-idf值表示的文档向量:
>>> corpus_tfidf = tfidf[corpus]
>>> for doc in corpus_tfidf:
… print doc
…
[(1, 0.6633689723434505), (2, 0.6633689723434505), (3, 0.2448297500958463), (6, 0.2448297500958463)]
[(7, 0.16073253746956623), (8, 0.4355066251613605), (9, 0.871013250322721), (10, 0.16073253746956623)]
[(3, 0.5), (6, 0.5), (7, 0.5), (10, 0.5)]
发现一些token貌似丢失了,我们打印一下tfidf模型中的信息:
>>> print tfidf.dfs
{0: 3, 1: 1, 2: 1, 3: 2, 4: 3, 5: 3, 6: 2, 7: 2, 8: 1, 9: 1, 10: 2}
>>> print tfidf.idfs
{0: 0.0, 1: 1.5849625007211563, 2: 1.5849625007211563, 3: 0.5849625007211562, 4: 0.0, 5: 0.0, 6: 0.5849625007211562, 7: 0.5849625007211562, 8: 1.5849625007211563, 9: 1.5849625007211563, 10: 0.5849625007211562}
我们发现由于包含id为0, 4, 5这3个单词的文档数(df)为3,而文档总数也为3,所以idf被计算为0了,看来gensim没有对分子加1,做一个平滑。不过我们同时也发现这3个单词分别为a, in, of这样的介词,完全可以在预处理时作为停用词干掉,这也从另一个方面说明TF-IDF的有效性。
有了tf-idf值表示的文档向量,我们就可以训练一个LSI模型,和Latent Semantic Indexing (LSI) A Fast Track Tutorial中的例子相似,我们设置topic数为2:
>>> lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
>>> lsi.print_topics(2)
2013-05-27 19:15:26,467 : INFO : topic #0(1.137): 0.438*”gold” + 0.438*”shipment” + 0.366*”truck” + 0.366*”arrived” + 0.345*”damaged” + 0.345*”fire” + 0.297*”silver” + 0.149*”delivery” + 0.000*”in” + 0.000*”a”
2013-05-27 19:15:26,468 : INFO : topic #1(1.000): 0.728*”silver” + 0.364*”delivery” + -0.364*”fire” + -0.364*”damaged” + 0.134*”truck” + 0.134*”arrived” + -0.134*”shipment” + -0.134*”gold” + -0.000*”a” + -0.000*”in”
lsi的物理意义不太好解释,不过最核心的意义是将训练文档向量组成的矩阵SVD分解,并做了一个秩为2的近似SVD分解,可以参考那篇英文tutorail。有了这个lsi模型,我们就可以将文档映射到一个二维的topic空间中:
>>> corpus_lsi = lsi[corpus_tfidf]
>>> for doc in corpus_lsi:
… print doc
…
[(0, 0.67211468809878649), (1, -0.54880682119355917)]
[(0, 0.44124825208697727), (1, 0.83594920480339041)]
[(0, 0.80401378963792647)]
可以看出,文档1,3和topic1更相关,文档2和topic2更相关;
我们也可以顺手跑一个LDA模型:
>>> lda = models.LdaModel(copurs_tfidf, id2word=dictionary, num_topics=2)
>>> lda.print_topics(2)
2013-05-27 19:44:40,026 : INFO : topic #0: 0.119*silver + 0.107*shipment + 0.104*truck + 0.103*gold + 0.102*fire + 0.101*arrived + 0.097*damaged + 0.085*delivery + 0.061*of + 0.061*in
2013-05-27 19:44:40,026 : INFO : topic #1: 0.110*gold + 0.109*silver + 0.105*shipment + 0.105*damaged + 0.101*arrived + 0.101*fire + 0.098*truck + 0.090*delivery + 0.061*of + 0.061*in
lda模型中的每个主题单词都有概率意义,其加和为1,值越大权重越大,物理意义比较明确,不过反过来再看这三篇文档训练的2个主题的LDA模型太平均了,没有说服力。
好了,我们回到LSI模型,有了LSI模型,我们如何来计算文档直接的相思度,或者换个角度,给定一个查询Query,如何找到最相关的文档?当然首先是建索引了:
>>> index = similarities.MatrixSimilarity(lsi[corpus])
2013-05-27 19:50:30,282 : INFO : scanning corpus to determine the number of features
2013-05-27 19:50:30,282 : INFO : creating matrix for 3 documents and 2 features
还是以这篇英文tutorial中的查询Query为例:gold silver truck。首先将其向量化:
>>> query = “gold silver truck”
>>> query_bow = dictionary.doc2bow(query.lower().split())
>>> print query_bow
[(3, 1), (9, 1), (10, 1)]
再用之前训练好的LSI模型将其映射到二维的topic空间:
>>> query_lsi = lsi[query_bow]
>>> print query_lsi
[(0, 1.1012835748628467), (1, 0.72812283398049593)]
最后就是计算其和index中doc的余弦相似度了:
>>> sims = index[query_lsi]
>>> print list(enumerate(sims))
[(0, 0.40757114), (1, 0.93163693), (2, 0.83416492)]
当然,我们也可以按相似度进行排序:
>>> sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
>>> print sort_sims
[(1, 0.93163693), (2, 0.83416492), (0, 0.40757114)]
可以看出,这个查询的结果是doc2 > doc3 > doc1,和fast tutorial是一致的,虽然数值上有一些差别:
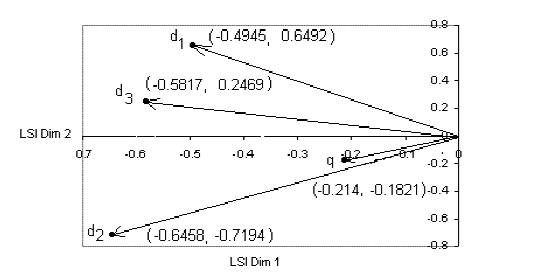
好了,这个例子就到此为止,下一节我们将主要说明如何基于gensim计算课程图谱上课程之间的主题相似度,同时考虑一些改进方法,包括借助英文的自然语言处理工具包NLTK以及用更大的维基百科的语料来看看效果。
未完待续…
建议继续学习:
- 相似度计算常用方法综述 (阅读:9183)
- 字符串匹配那些事(一) (阅读:5579)
- 如何计算两个文档的相似度(一) (阅读:4498)
- URL相似度计算的思考 (阅读:3574)
- Levenshtein distance相似度算法 (阅读:2996)
- 如何计算两个文档的相似度(三) (阅读:2714)
- 若无云,岂有风——词语语义相似度计算简介 (阅读:2347)
- 相似度计算之兰氏距离 (阅读:1343)
- 相似度计算之马氏距离 (阅读:1299)
- 常见相似度计算方法回顾 (阅读:1252)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:52nlp 来源: 我爱自然语言处理
- 标签: gensim 相似度
- 发布时间:2013-05-28 22:24:03

-
 [601] 招聘技巧一二
[601] 招聘技巧一二 -
[17] 我的git笔记
-
[16] 在ssh服务里使用chroot
-
[16] 密度聚类算法之OPTICS
-
[15] 数据分析中常用的数据模型
-
[15] 豆瓣是啥?
-
[14] jQuery性能优化指南
-
[14] Android用户界面设计:表格布局
-
[13] 一次神奇的MySQL优化
-
[13] 配合jquery实现异步加载页面元素
