您现在的位置:首页
--> 系统架构
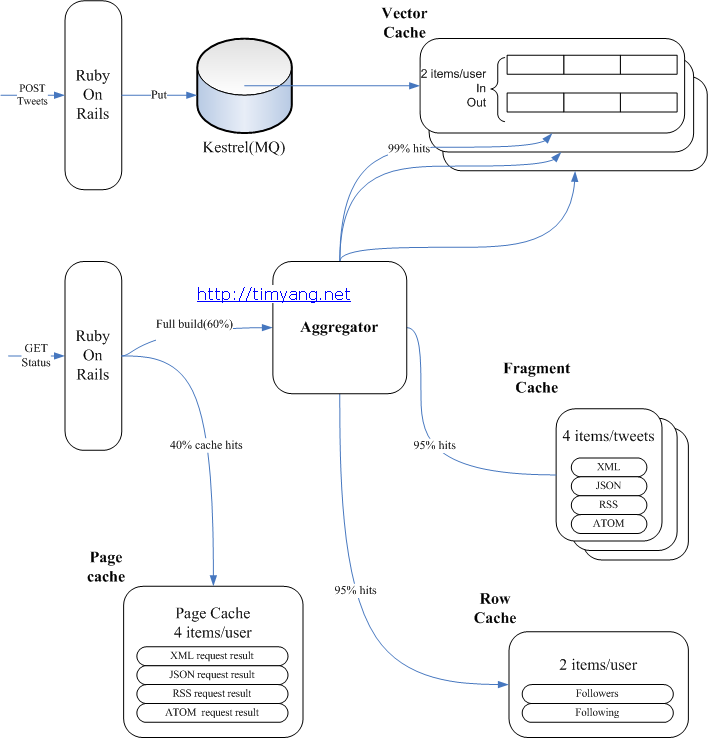
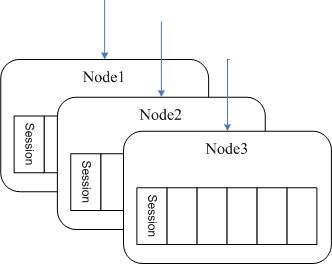
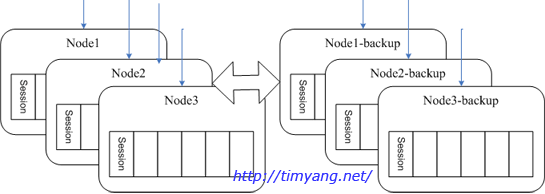
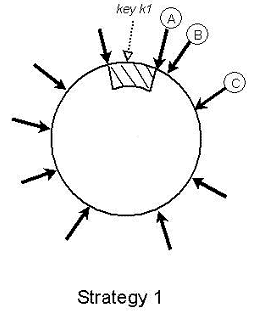
最近项目中一个分布式应用碰到一些设计问题,听过上次技术沙龙key value store漫谈的同学可能会比较容易理解以下说明。场景假定一个有状态的服务,可以理解成web或者socket服务器,每个用户在这个服务上登录后是有状态的,我们把它的状态连同其他加载到内存的用户数据统称用户session。由于session数据实时会变化,加上程序访问session频率大,几乎所有的操作都跟session数据相关,因此不适合放在远程memcached中第一阶段考虑...
NTP(Network Time Protocol)是由美国德拉瓦大学的David L. Mills教授于1985年提出,除了可以估算封包在网络上的往返延迟外,还可独立地估算计算机时钟偏差,从而实现在网络上的高精准度计算机校时,它是设计用来在Internet上使不同的机器能维持相同时间的一种通讯协定。时间服务器(time server)是利用N...
“客户端访问”与“服务器端响应”,犹如一场战争。初期,访问量较小,弄几台服务器随便拉起一只队伍,就能抵抗住客户端的进攻。慢慢的,访问量大起来,这时候,就需要讲究排兵布阵、战略战术、多兵种协调作战。于是,开始有了负载均衡服务器、Web服务器、缓存服务器、数据库服务器、存储服务器等多兵种;开始...

我们都知道浏览器会缓存访问过网站的网页,浏览器通过URL地址访问一个网页,显示网页内容的同时会在电脑上面缓存网页内容。如果网页没有更新的话,浏览器再次访问这个URL地址的时候,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页...
• 浏览器的结构
现代浏览器大都基于XML中的DOM规范来建立,而且DOM规范提供了对ECMAScript的绑定,可以方便的用来实现javascript。
Craigslist 绝对是互联网的一个传奇公司。根据以前的一则报道:每月超过 1000 万人使用该站服务,月浏览量超过 30 亿次,(Craigslist每月新增的帖子近 10 亿条??)网站的网页数量在以每年近百倍的速度增长。Craigslist 至今却只有 18 名员工(现在可能会多一些了)。
原文(英文)地址: http://www.mnot.net/cache_docs/ 版权声明:署名-非商业性使用-禁止演绎 2.0这是一篇知识性的文档,主要目的是为了让Web缓存相关概念更容易被开发者理解并应用于实际的应用环境中。为了简要起见,某些实现方面的细节被简化或省略了。如果你更关心细节实现则完全不必耐心看完本文,后面参考文档和更多深入阅读部分可能是你更需要的内容。什么是Web缓存,为什么要使用它?缓存的类型:浏览器缓存;代理服务器缓...
内容摘要:拥有大量的历史积累的各种论坛系统中的内容往往很难被搜索引擎收录,BBS2BLOG是一个bbs改造思路:通过对现有BBS加入按“个人”的归档机制,让这些丰富内容都可以成为整个可搜索互联网知识库的一部分。
内容摘要:对于一个日访问量达到百万级的网站来说,速度很快就成为一个瓶颈。除了优化内容发布系统的应用本身外,如果能把不需要实时更新的动态页面的输出结果转化成静态网页来发布,速度上的提升效果将是显著的,因为一个动态页面的速度往往会比静态页面慢2-10倍,而静态网页的内容如果能被缓存在内存里,访问速度甚至会比原有动态网页有2-3个数量级的提高。
内容摘要: 为Lucene做一个通用XML接口一直是我最大的心愿:更方便的在WEB应用中嵌入全文检索功能,2004年时类似应用还很不成熟,但现在也许应该优先试试以Lucene为核心的Solr全文应用引擎; 提供了XML的数据输入接口:适合将原有基于各种数据库的数据源导入到全文索引中,保证了数据源的平台无关性; 通过了基于XML的搜索结果输出:方便了通过XSLT进行前台的结果显示;
内容摘要: 内容管理系统概述 内容管理系统的选型 广告管理系统的选型 论坛/社区系统的选型 所见即所得编辑器的选型 图片上传和文件管理组件

前言应该是很久之前,我开始研究Memcache,写了一系列的学习心得,比如《Discuz!的Memcache缓存实现》等。后面的好几十条回复也让这篇文章成为了此博客中颇受关注的一员。同时在百度和Google,关键词Memcache在长达一年多的时间里占据着第二位(第一位是官方),为很多需要了解或者应用Memcache的朋友提供了一些信息,但是我始终觉着还不够,于是本文诞生。
由于最近要搞一个P2P项目,所以最近找了份C#版BtTorrent [MonoTorrent]代码,参考参考它对BT协议的实现,在看Tracker模块时发现了这个功能,非常不错,于是就将他单独挖出来,写了个简单测试代码,这东西还是很不错的,有时候还真能派上点用处。
一、编译先前条件确认是否已经安装以下软件,有些也许不是必须的,但建议还是都装上。apt-get install autoconf automake autotools-dev cpp curl gawk gcc lftp libc6-dev linux-libc-dev make libpcre3-dev libpcrecpp0 g++ libtool libncurses5-devaptitude install libmysql++-dev libmysqlclient15-dev checkinstallapt-get install python python-dev二、安装所需文件所需文件列表mmseg-0.7.3.tar.gz 中文分词 mysql-5.1.26-...




最近在做一个内部测试工具类的优化工作中接触到了连接池, 对象池技术, 将原有的未使用连接池的数据库访问操作改成连接池方式.性能有了非常大的提升, 事实证明, 经过两次改造, 原来一个比较大的测试类需要500多秒, 第一次优化后只需要300多秒, 第二次改用连接池之后同一个测试类只需要80多秒.下面是改造过程中的一些总结. 对象池就是以”空间换时间”的 一种常用缓存机制, 这里的”时间”特指创建时间,因此这...
由于web程序和一般的软件开发不同,自动化测试的效率和必要性一直较低,因此人工测试一直是web项目的最主要测试手段。但这并不表示web项目就不需要进行自动化测试。对于web项目而言,自动化测试可以分为单元测试和功能测试。功能测试主要针对具体页面进行测试,个人觉得意义不大,因为既然是针对具体页面进行测试,采用人工测试的方式更为直接,高效,且灵活。当然如果针对某些页面进行的压力测试还是很有必要的。
近3天十大热文
-
 [333] 招聘技巧一二
[333] 招聘技巧一二 -
[14] linux内核研究笔记(一)内存管理 – p
-
[13] 个人开公司的流程,以后用得着
-
[10] Nginx+FastCgi+Php 的工作机
-
[10] DBA最缺的不是技术
-
[10] DBA有什么个人前途?
-
[10] 关于大学学习,说说我的一些体会
-
[10] ps - 按进程消耗内存多少排序
-
[10] 我的程序员之路
-
[9] oracle技术方面的路线
赞助商广告
