您现在的位置:首页
--> 系统架构

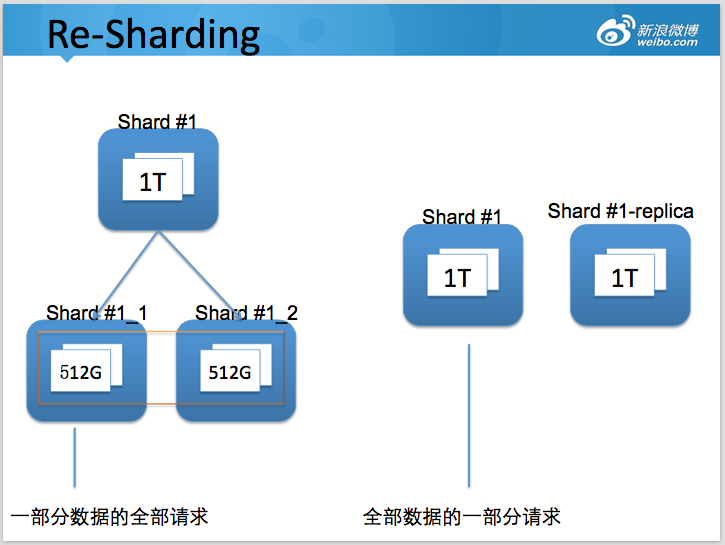
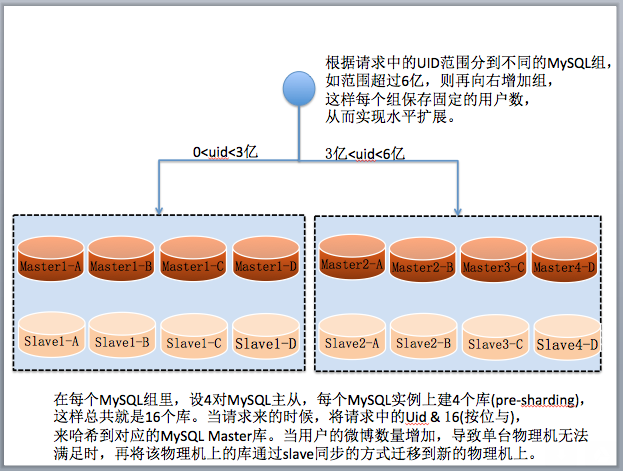
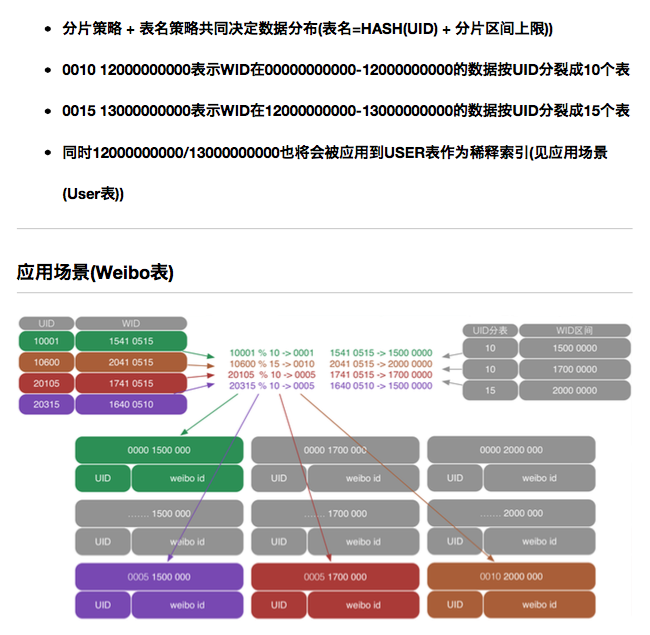
可能通过「高可用架构」听说过在微博的系统中,单张 MySQL 在线业务表 60 亿条数据的场景。很多关注互联网架构的工程师也非常关注如何如何设计类似系统。下面是一道微博新兵训练营的分布式存储课堂练习,要设计合格才能上岗。
• 如何设计用户登录
在Web系统中,用户登录是最基本的功能。要实现用户名+密码登录,很多同学的第一想法就是直接创建一个Users表,包含username和password两列,这样,就可以实现登录了.现在问题来了,如果要让用户通过第三方登录,比如微博登录或QQ登录,怎么集成进来呢?


最近出现的 React Native 再次让跨平台移动端开发这个话题火起来了,曾经大家以为在手机上可以像桌面那样通过 Web 技术来实现跨平台开发,却大多因为性能或功能问题而放弃,不得不针对不同平台开发多个版本。
但这并没有阻止人们对跨平台开发技术的探索,毕竟谁不想降低开发成本,一次编写就处处运行呢?除了 React Native,这几年还出现过许多其它解决方案,本文我将会对这些方案进行技术分析,供感兴趣的读者参考。


前天参加了腾讯的一个面试,面试官除了提到前端的一些基础问题,还问了不少前端安全方面的知识,以及一些实际应用的设计思路。整个面试过程中,面试官不断地抛问题,而且很多问题都是点到为止。对于一些比较难的问题,也没有任何提示,回答对错也不告诉你,更不会跟你讲解这个问题到底是如何解决的!难道是为了节省面试时间吗?面试中,问了这么一道题:“微信手机客户端扫面二维码实现网页登录原理是什么?”。当时,答得比较乱。问题本身还是挺有意思的,于是今天好好研究了下!





实时检索分析平台(Hermes)是腾讯数据平台部为大数据分析业务提供一套实时的、多维的、交互式的查询、统计、分析系统,为各个产品在大数据的统计分析方面提供完整的解决方案,让万级维度、千亿级数据下的秒级统计分析变为现实。
Paxos是一个分布式选举协议,被广泛用在很多分布式系统中,比如Google的Chubby,MegaStore,Linux的Ceph。它的目的是为了让一群机器通过选举的方式达成一个一致性的决议。比如现在有5台MySQL服务器,它们要选举一个Master出来(无人工干预),所有的数据修改请求都发给这个Master,其它的做为Slave,以备在Master死掉后自动顶上去。
在大型分布式 java 应用中,为了方便开发者,通常底层的 rpc 框架都会做一些调用的封装,让应用层开发人员在开发服务的时候只用编写简单的 pojo 对象就可以了,如流行的 spring remoting , jboss remoting 等等,都有这样的效果。
数据库客户端有着各种类型和大小。一些用起来不太爽,一些相当有爱。不幸的是,我已经发现所有的数据库客户端在不同的地方存在欠缺。下面是我认为的理想数据库客户端的特点。
• Email精粹

MeCab是一套日文分词(形态分析)和词性标注系统(Yet Another Part-of-Speech and Morphological Analyzer), rick曾经在这里分享过MeCab的官方文档中文翻译: 日文分词器 Mecab 文档,这款日文分词器基于条件随机场打造,有着诸多优点,譬如代码基于C++实现,基本内嵌CRF++代码,词典检索的算法和数据结构均使用双数组Double-Array,性能优良,并通过SWIG提供多种语言调用接口,可扩展性和通用性都非常不错。
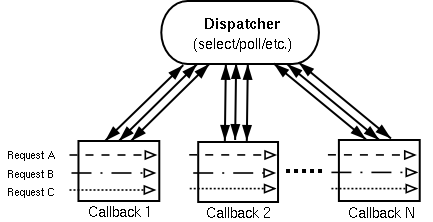
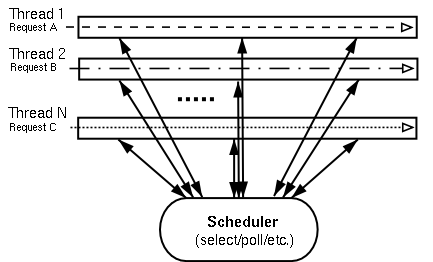
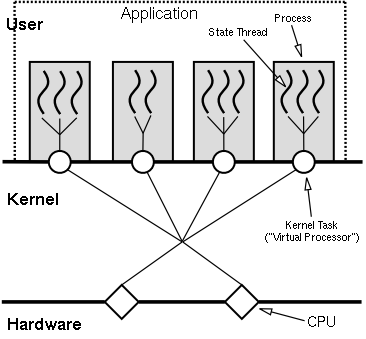
传统EDSM最常见的方式就是I/O事件的异步回调。基本上都会有一个叫做dispatcher的单线程主循环(又叫event loop),用户通过向dispatcher注册回调函数(又叫event handler)来实现异步通知,从而不必在原地空耗资源干等,在dispatcher主循环中通过select()/poll()系统调用来等待各种I/O事件的发生,当内核检测到事件触发并且数据可达或可用时,select()/poll()会返回从而使dispatcher调用相应的回调函数来对处理用户的请求。所以异步回调与其说是通知,不如说用委托更恰当。


笔者最早接触的是Condor/HTCondor,搞过网格计算的同学应该比较了解;Goolge的Borg应该算是一开始借鉴了很多Condor的东西,Omega则是在解决borg的单master调度的瓶颈问题;Tencent的Tborg/Torca则是和Borg系统有很深的渊源;Yarn和Mesos应该是被更多的人所熟知,都支持多种计算框架;对AutoPilot的认知更多来自于相关的论文;Baidu的系统其实蛮有意思,特别是IDLE(有个组件可以随意种植在任何机器上,当机器空闲的时候则调度一些低优先级并且可以随时K掉的计算任务上去执行,而且他们的PE人员身背机器利用率的KPI,大家都求着调度任务上去,这和咱们的现状完全是两样);FUXI和T4是集团内的系统,大家想要了解可以在内网找到他们。
说起load balance,一般比较容易想到的是大型服务在多个replica之间的load balance、和kernal的load balance。前者一般只是在流量入口做一下流量分配,逻辑相对简单;而后者则比较复杂,需要不断发现正在运行的各个进程之间的imbalance,然后通过将进程在CPU之间进行迁移,使得各个CPU都被充分利用起来。
而本文想要讨论的load balance有别于以上两种,它是多线程(多进程)server程序内部,各个worker线程(进程)之间的load balance。
SKU,Stock Keeping Unit,库存单元,是商品库存的最小单位。通俗的讲,一种商品可能有各种规格的货,每一种货就是一个SKU。搜索引擎是以商品作为检索单位,没法提供更细粒度(SKU粒度)的检索功能。于是,为了提升用户的搜索体验,为了把搜索做得更好,搜索引擎需要支持SKU粒度的检索。
有感于我厂某iOS项目的开发管理混乱,所以这里说一下我这边对Xcode工程的一些管理经验 。




分布式存储有出色的性能,可以扛很多故障,能够轻松扩展,所以我们使用Ceph构建了高性能、高可靠的块存储系统,并使用它支撑公有云和托管云的云主机、云硬盘服务。
由于使用分布式块存储系统,避免了复制镜像的过程,所以云主机的创建时间可以缩短到10秒以内,而且云主机还能快速热迁移,方便了运维人员对物理服务器上硬件和软件的维护。
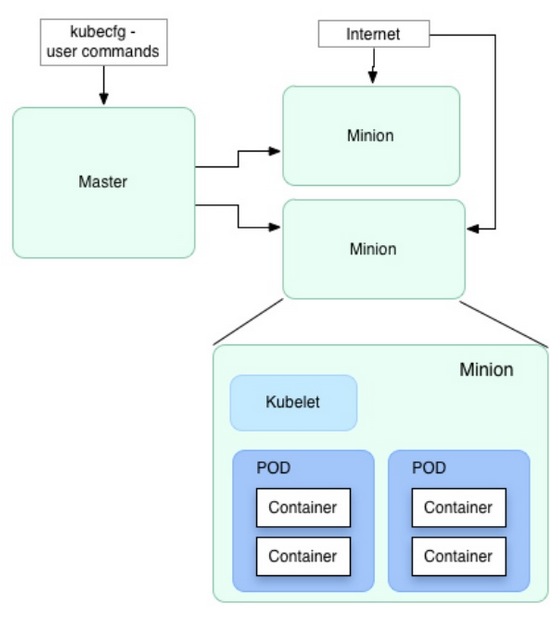
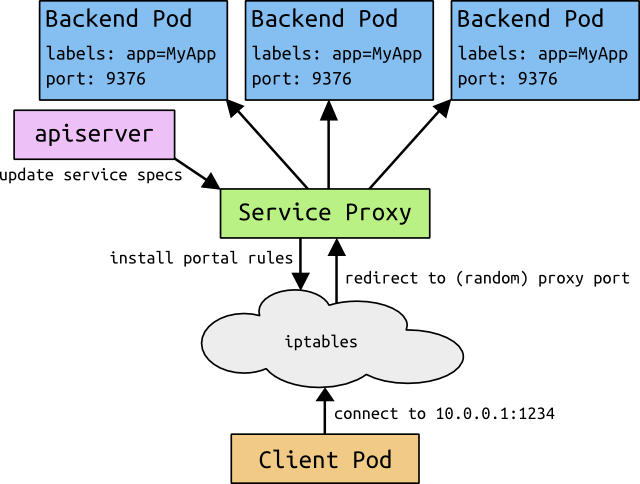
Kubernetes是Google开源的容器集群管理系统。前几天写的 分布式服务框架的4项特性 中提到一个良好的分布式服务框架需要实现 服务的配置管理。包括服务发现、负载均衡及服务依赖管理。 服务之间的调度及生命周期管理。


随着业务的快速增长,TDW的节点数也在增加,对单个大规模Hadoop集群的需求也越来越强烈。TDW需要做单个大规模集群,主要是从数据共享、计算资源共享、减轻运营负担和成本等三个方面考虑。
近3天十大热文
-
 [611] 招聘技巧一二
[611] 招聘技巧一二 -
[18] 配合jquery实现异步加载页面元素
-
[18] 在ssh服务里使用chroot
-
[17] 我的git笔记
-
[15] 跨域请求的iframe解决方案(1)
-
[14] 豆瓣是啥?
-
[14] Android用户界面设计:表格布局
-
[14] 跨域请求的iframe解决方案(2)
-
[13] 使用document.domain和ifra
-
[13] 密度聚类算法之OPTICS
赞助商广告
