您现在的位置:首页
--> 系统架构

针对HBase在单column family单column qualifier和单column family多column qualifier两种场景下,分别批量Put写入时的性能对比情况,下面是结合HBase的源码来简单分析解释这一现象。




SolrCloud是Solr4.0版本开发出的具有开创意义的基于Solr和Zookeeper的分布式搜索方案,或者可以说,SolrCloud是Solr的一种部署方式。Solr可以以多种方式部署,例如单机方式,多机Master-Slaver方式,这些方式部署的Solr不具有SolrCloud的特色功能。




作为常用的NoSQL存储系统之一,KV存储系统受到了开发者的关注。但常见的KV存储系统并不具备自动容灾和在线扩容功能,这给系统运营造成了不少麻烦。本文提出了一种构建高可用和自动弹性伸缩的KV存储系统的方法。
您是否见过当文档加载时其内容会显示不规律的移动。之所以会这样,是因为浏览器为了能够显示每一个加载的图像,而不断地重新调整页面的布局。浏览器通过下载并解析出图像的宽度和高度来决定图像的大小,然后就会在显示窗口中留出一个相应的矩形空间。然后浏览器就会调整页面的显示布局,以便把图像插入到显示当中。这同时也告诉我们,图像是独立的文件,它与源文件都分别是独立加载的。

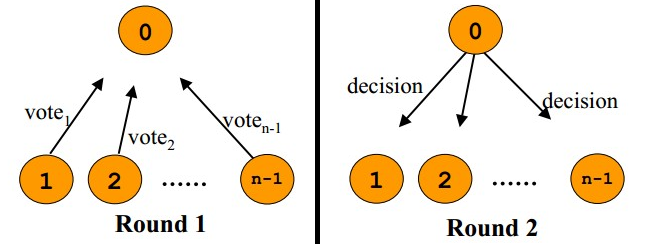
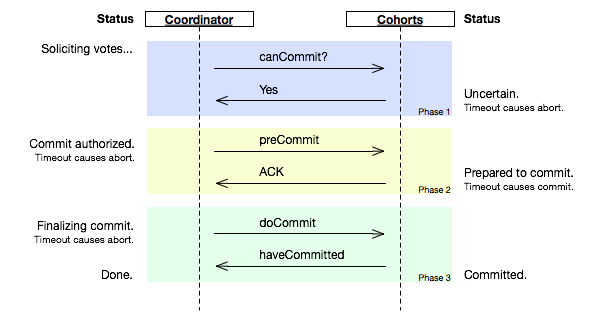
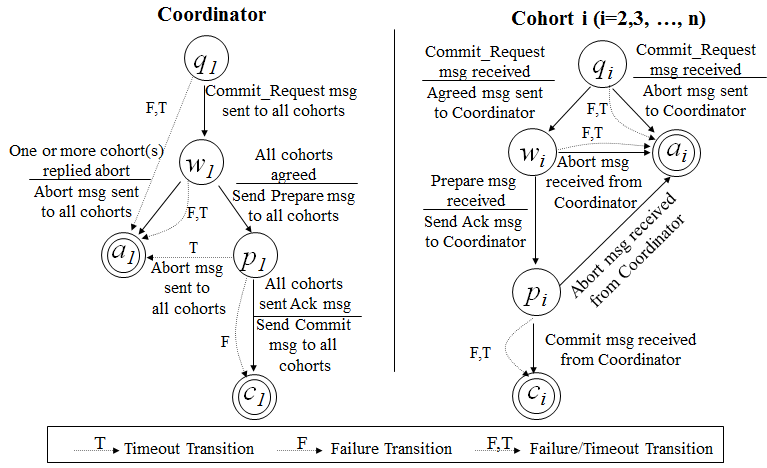
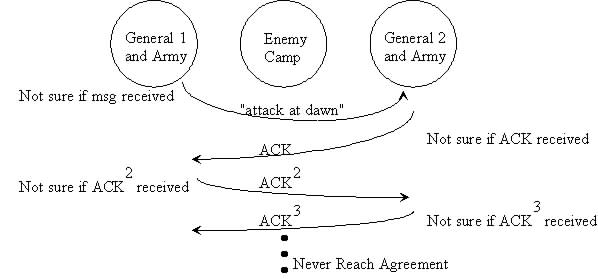
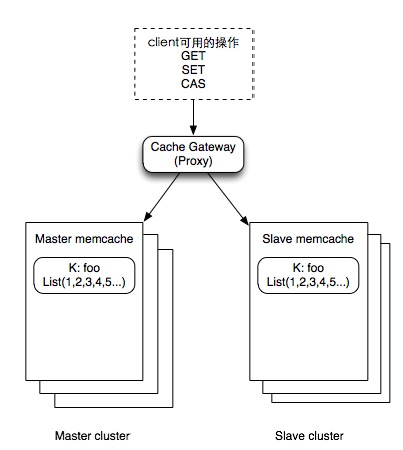
当我们在生产线上用一台服务器来提供数据服务的时候,我会遇到如下的两个问题:
1)一台服务器的性能不足以提供足够的能力服务于所有的网络请求。
2)我们总是害怕我们的这台服务器停机,造成服务不可用或是数据丢失。
于是我们不得不对我们的服务器进行扩展,加入更多的机器来分担性能上的问题,以及来解决单点故障问题。





曾“夸下海口”说听完讲座后七天就可以打造自己的前端性能监控系统,既然说出去了也不能食言。从前一篇文章前端数据之美相信大家对前端数据有了一定的了解,下面就针对其中的性能数据及其监控进行详细阐述。







iMAG是一个非常简洁高效的移动跨平台开发框架,开发一次可以同时兼容Android和iOS平台,有点儿Web开发基础就能很快上手。当前移动端跨平台开发的框架有很多,但用iMAG还有一个好处,就是用iMAG开发出的App是原生的。iMAG采用XML + JavaScript(配置 + 脚本)的开发方式,它的原理是将符合iMAG开发规范的XML文件解释成对应的原生应用代码来执行。原生跨平台开发,iMAG App具有和Native App相同的性能和用户体验,因此相比PhoneGap、JQuery Mobile等Web开发框架iMAG适用于对性能要求较高的情况。
• 规则引擎简介




现实生活中,规则无处不在。法律、法规和各种制度均是;对于企业级应用来说,在IT技术领域,很多地方也应用了规则,比如路由表,防火墙策略,乃至角色权限控制(RBAC),或者Web框架中的URL匹配。不管是那种规则,都规定了一组确定的条件和此条件所产生的结果。

• CAP 理论
CAP理论被很多人拿来作为分布式系统设计的金律,然而感觉大家对CAP这三个属性的认识却存在不少误区。从CAP的证明中可以看出来,这个理论的成立是需要很明确的对C、A、P三个概念进行界定的前提下的。在本文中笔者希望可以对论文和一些参考资料进行总结并附带一些思考。
提到这两个系统,他们在核心思路上是非常类似的,但有一些细节性的东西又有所偏重,在分布式系统中也算是独树一帜了,很有代表性的一个系列,这些不一致的地方,最明显的地方就在于一致性上。可见,哪怕是从追求简单为上的工程化实现来说,各种不同的方式实现一致性也都有很大的不同,不过他们也有一些共性和一些独树一帜的概念,下面来做一下分别解说。
Erlang公平调度是它的哲学(或者说坚持)之一,从第一个版本的beam代码的时间片分配和抢占开始,到最近版本的bif对公平性的坚持(比如R17版binary_to_term就大幅做了修改,代码复杂很多,执行效率也有下降,但是在碰到大的binary的情况下,通过Trap机制会让出执行权,排队后再回来断点续作), nif(加入扣除时间片的接口),这些努力保证了erlang系统是个公平的系统。 很多终端系统和业务会受益于这个哲学,如云计算。不管用户大小和业务的负载情况如何,系统性的公平性可以保证每个用户有机会被服务,对用户有很好的体验。




CPU,一般认为写C/C++的才需要了解,写高级语言的(Java/C#/pathon…)并不需要了解那么底层的东西。我一开始也是这么想的,但直到碰到LMAX的Disruptor,以及马丁的博文,才发现写Java的,更加不能忽视CPU。经过一段时间的阅读,希望总结一下自己的阅读后的感悟。本文主要谈谈CPU缓存对Java编程的影响,不涉及具体CPU缓存的机制和实现。

近3天十大热文
-
 [593] 招聘技巧一二
[593] 招聘技巧一二 -
[17] 我的git笔记
-
[16] 数据分析中常用的数据模型
-
[15] 30分钟3300%性能提升――python+
-
[15] 在ssh服务里使用chroot
-
[15] 豆瓣是啥?
-
[14] 密度聚类算法之OPTICS
-
[14] 一次神奇的MySQL优化
-
[14] jQuery性能优化指南
-
[14] Android用户界面设计:表格布局
赞助商广告
