您现在的位置:首页
--> 系统运维
Linux系统需要定期巡检,以检查服务器软硬件使用情况,相当于对人的体检,确保可以及时发现问题、解决问题,降低损失,常用的巡检命令如下...
本着分享的精神, 给近一二年使用 Mojolicious 的经验分享给大家. 今天要分享的是怎么加强默认 Mojo 显示日志, 让我们更加好的排错。
正确的重定向标准输出和标准错误的方法是:>/dev/null 2>&1 ,关于连环重定向,可以参考这里的解释:>/dev/null 2>&1 含义。如果一不小心,可能会导致/dev/null 被重定向到0,1或2,导致整个系统异常。
最近在一个性能测试中遇到机器的CPU频率不对。查了一下原来是irqbalance和cpuspeed搞出来问题。
操作一台服务器的时候可以 ssh,操作多台服务器可以开多个窗口多个 ssh,那操作很多台服务器呢?
我们的一个 Oracle Gird Engine 集群上大概有60多台 Ubuntu 服务器作执行节点,这些服务器操作系统和软件配置完全一样(上线后由 puppet 统一配置),有时候我们需要在这些服务器上做同样的操作,这个时候特别适合使用 PSSH 这种 ssh 批量操作工具。
当然,如果对 Python 不恐惧的话也可以用 Fabric 批量执行服务器任务。
关于Syslog的内容我并不想多说,否则就偏离了主题,大家如果有不清楚的地方,可以参考鸟哥的Linux私房菜。虽然Syslog中规中矩,但是随着时间的推移,无论是功能还是性能,它都显得捉襟见肘,于是出现了:Rsyslog和Syslog-ng,它们都涵盖SysLog的常用功能,不过在功能和性能上更为出色,至于孰优孰劣是个仁者见仁智者见智的问题,鉴于多数Linux发行版均选择了Rsyslog,姑且让我随波逐流一次。
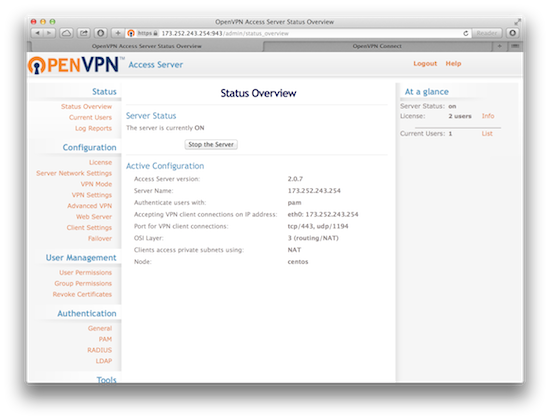
平时很少用 VPN,需要的时候一般用 ssh -D 搞定,或者 sshuttle 也是个不错的工具。自己配置 OpenVPN 虽然不是很麻烦,但对第一次配置 VPN 的新手来说还是挺费神费事的,如果急用或者怕麻烦的话可以选用 OpenVPN 的商业收费版本 OpenVPN Access Server,其免费的 license 可以支持2个 VPN 用户的同时在线,对个人用户来说足够用了。
一台Redis服务器在很短的时间里消耗了几十个G的内存,最终因为SWAP而宕机。因为这台服务器的社会背景比较复杂,所以一时无法判断犯罪嫌疑人到底是谁。 最开始的直觉是认为肯定有人保存了大体积的数据,于是问题就变成了找出哪些键占用的空间比较大,DBA同事用了redis-rdb-tools等工具来分析数据文件。可惜的是虽然找到了一些大体积的键,但最终都排除了嫌疑,问题似乎陷入了僵局。
启动iptables时,出现了Setting chains to policy ACCEPT: security raw nat filter [FAILED]
Google 之后发现是CentOS 的iptables多了一个security 表,而 /etc/init.d/iptables 中却没有该表的规则定义字段,所以需要手工添加。


考虑到我手上的服务器逐渐的增多,有时候需要大规模的部署同一个文件,例如因为方便使用systemtap这个工具定位问题,需要把手上几百台服务器同时安装kernel-debuginfo这个包,原有的方式采用一个源服务器,采用rsync或者scp之类的文件传输方式只能做到一个点往下分发这个文件,这个时候下发的速度就会比较的慢,基于以上原因,我写了一个基于bt协议传输文件的小工具,实际测试,传输到10个机房,70多台机器传输一个240M的这个内核文件,到所有的机器,源采用限速2m/s的上传速度,测试的结果大概只要140s,就可以全部传输完毕,这个效率是非常之高,如果不限速的情况下速度会更快,下面把这个程序开源出来。
现代社会,熟练使用ssh是一项必不可少的技能,下面是我日常使用ssh的一些小总结。
注意:测试全部是在linux系统上进行,如果你使用windows系统,可以好好研究putty和xshell的各类选项,一定会找到实现的办法!




最近每天抽调一点时间充当客服工作,解决用户的技术问题,在充当客服工作当中,遇到各种形形色色的问题,才知道以前自认为不是问题的问题现在都成为了问题,在问题的分析,解决过程中相当的困惑人,有时候同一个问题分析好几天,尝试各种方式,最后到问题的解决,解决问题后,那种兴奋是无法用语言来形容,感谢用户容忍我们这么不停的折腾,在这个过程当中,让我了解到一些更底层的东西,对于自身也是一个很大的提高。下面说说遇到几个问题的案例吧。




我的blog前面有一篇文章描述了软终端导致单cpu消耗100%,导致机器丢包跟延迟高的问题,文中我只是简单的说明了一下升级内核进行解决的,这个问题我并没有进行一个问题解决的说明,经历了一系列的调整后,单机的并发从单机单网卡承受100M流量到160M流量,到现在的最高的230M流量,在程序没有大规模修改的情况下效果还是十分的明显,这次这篇文章将完整的说一下我的一个解决方法。
Apache/Nginx 通常被放在tomcat前作为http代理:browser -> apache -> tomcat。但是缺点是丢失了很多原有的网络信息:ip、hostname、protocol(用的是http还是 https),比如,当java程序想生成http重定向请求的时候会遇到麻烦。因为HTTP头部的Location字段的值必须是绝对URL。重定向的问题勉强可以交给前面的proxy来解决(让apache重写header),但是藏在http body中的各种链接问题就棘手多了。比如当从一个html页面载入一个外部资源时,资源的链接到底是写http的还是https的呢?
默认情况下,Linux网络被配置成最佳可用性状态,但不是最佳性能状态。对于一个10GbE的网卡来讲,这是尤其明显的。内核的 send/recv 缓冲区,tcp堆栈的内存分配策略和 数据包的队列都设置的太小,以至于它们不能工作在最佳的性能状态。下面所做的一些测试和优化,希望能够给你的网卡带来一定的性能提升。
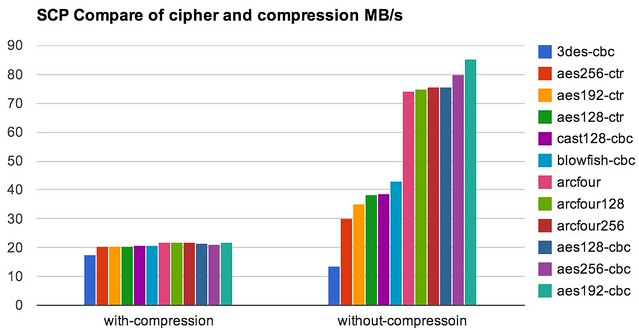
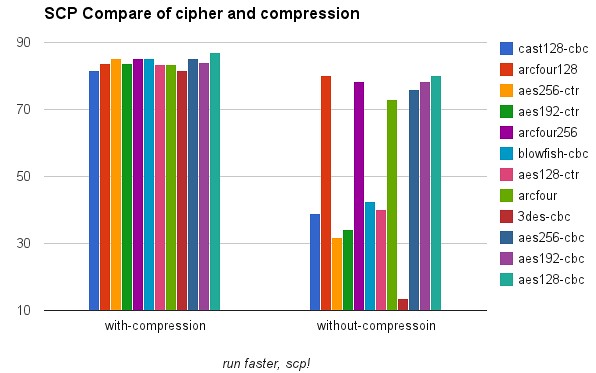
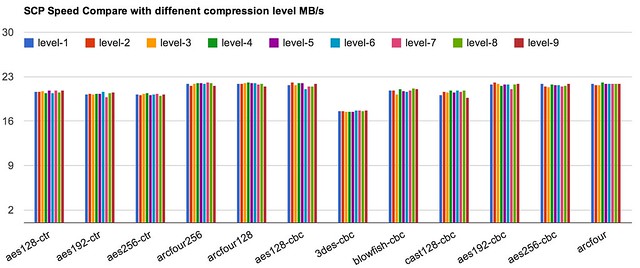
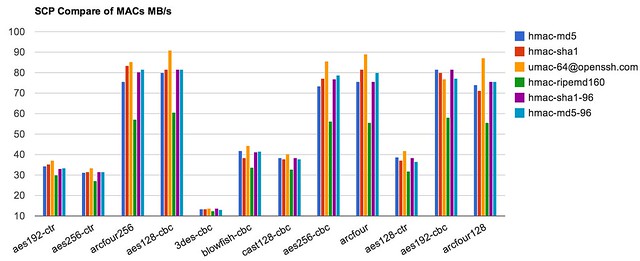
当需要在机器之间传输400GB文件的时候,你就会非常在意传输的速度了。默认情况下(约125MB带宽,网络延迟17ms,Intel E5-2430,本文后续讨论默认是指该环境),scp的速度约为40MB,传输400GB则需要170分钟,约3小时,如果可以加速,则可以大大节约工程师的时间,让攻城师们有更多时间去看个电影,陪陪家人。
在Linux的/proc文件系统,可以看到自启动时候开始,所有CPU消耗的时间片;对于个进程,也可以看到进程消耗的时间片。这是一个累计值,可以"非阻塞"的输出。获得一定时间间隔的两次统计就可以计算出这段时间内的进程CPU利用率。
前些天发现XEN虚拟机上的Nginx服务器存在一个问题:软中断过高,而且大部分都集中在同一个CPU,一旦系统繁忙,此CPU就会成为木桶的短板。
近3天十大热文
-
 [166] 招聘技巧一二
[166] 招聘技巧一二 -
[15] Linux常用系统信息查看命令
-
[13] 最近总结的一些技巧(vim,python,s
-
[12] Redis和Memcached的区别
-
[12] 关于Linux的文件系统cache
-
[12] 在FreeNAS/BSD搭建基于Nginx+
-
[11] 个人开公司的流程,以后用得着
-
[10] 每个程序员都应该知道的8个Linux命令
-
[10] 我对技术方向的一些反思
-
[10] ps - 按进程消耗内存多少排序
赞助商广告
