您现在的位置:首页
--> MySQL
当使用Pytohn的 Flask-SQLAlchemy库操作 MySQL 数据时,出现'MySQL server has gone away' 了,是怎么回事呢?又该怎么办呢?分别从MySQL服务端和Python客户端来排查相关问题。
有个疑似 OCD 患者最近抽风升级了一下 MySQL 数据库,然后发现 blog 里面全都变成了乱码。
那乱码的模式一看就是把 utf8 直接扔进了 latin1 的数据库,一看 SHOW CREATE TABLE mt_entry 发现果然如此。
MySQL 的 innodb 引擎之所以使用 B+tree 来存储索引,就是想尽量减少数据查询时磁盘 IO 次数。树的高度直接影响了查询的性能。一般树的高度在 3~4 层较为适宜。数据库分表的目的也是为了控制树的高度。那么如何获取树的高度呢?下面使用一个示例来说明如何获取树的高度。
一台测试服务器,很久没有登录使用,忘记了mysql得root密码,经过搜索引擎一番查找,发现需要进行如下步骤做root密码重置。
mysql group replication官方在监控及优化方面文档较少,为了在教学中方便使用,总结一下。
• 删库跑路救命策略
首先看下mysql误删数据排名最前的几种是:
1.误删文件
2.误删库、表
3.错误全表删除 / 更新
4.升级操作失误
都来看看你命中过几个,hoho。
考虑到数据优化,现将千万级数据作分表存储便与查询。
文章背景:使用magenetico抓取磁力链接,由于它使用的是sqlite3, 文件会越来越大,而且不支持分布式;所以需要将其改造成MySQL,在迁移之前需要将已经抓取的15G数据导入到MySQL。

从master上用xtrabackup物理备份到slave,启动实例后,应该再执行 mysql_upgrade 升级相关表结构,确保P_S(performanc_schema)、I_S(information_schema)以及 mysql 等几个系统库表结构都升级到最新版本。
MySQL 管理工具集 persona-toolkit。


最近一段时间处理了较多锁的问题,包括锁等待导致业务连接堆积或超时,死锁导致业务失败等,这类问题对业务可能会造成严重的影响,没有处理经验的用户往往无从下手。下面将从整个数据库设计,开发,运维阶段介绍如何避免锁问题的发生,提供一些最佳实践供RDS的用户参考。
互联网很危险,信息及数据安全很重要,SQL注入是最常见的入侵手段之一,其技术门槛低、成本低、收益大,颇受各层次的黑客们所青睐。
一般来说,SQL注入的手法是利用各种机会将恶意SQL代码添加到程序参数中,并最终被服务器端执行,造成不良后果。
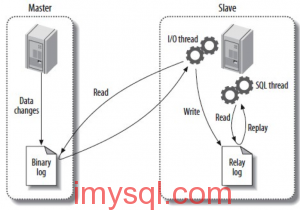
有时候,我们希望将 MySQL 的 relay log 多保留一段时间,比如用于高可用切换后的数据补齐,于是就会设置 relay_log_purge=0,禁止 SQL 线程在执行完一个 relay log 后自动将其删除。但是在官方文档关于这个设置有这么一句话: Disabling purging of relay logs when using the --relay-log-recovery option risks data consistency and is therefore not crash-safe. 究竟是什么样的风险呢?
MySQL被运用于越来越多的业务中,在关键业务中对数据安全性的要求也更高,如何保证MySQL的数据安全?
在mysql中limit可以实现快速分页,但是如果数据到了几百万时我们的limit必须优化才能有效的合理的实现分页了,否则可能卡死你的服务器哦。
对于一般进程,要让进程崩溃时能生成 core file 用于调试,只需要设置 rlimit 的 core file size > 0 即可。比如,用在 ulimit -c unlimited 时启动程序。
对 MySQL 来说,由于 core file 中会包含表空间的数据,所以默认情况下为了安全,mysqld 捕获了 SEGV 等信号,崩溃时并不会生成 core file,需要在 my.cnf 或启动参数中加上 core-file。
但是即使做到了以上两点,在 mysqld crash 时还是可能无法 core dump。还有一些系统参数会影响 core dump。
问题:有位同学问我,在类似pt-osc场景下,需要将两个表名对调,怎么才能确保万无一失呢?
问题:修改了 my.cnf 配置文件后,却不生效,这是怎么回事?
近3天十大热文
-
 [580] 招聘技巧一二
[580] 招聘技巧一二 -
[16] 给自己的字体课(一)——英文字体基础
-
[16] 数据分析中常用的数据模型
-
[16] 豆瓣是啥?
-
[15] 腾讯资深运维专家周小军:QQ与微信架构的惊天
-
[15] 30分钟3300%性能提升――python+
-
[15] iOS 8/Android/WP 系统设置的
-
[14] jQuery性能优化指南
-
[13] 一次神奇的MySQL优化
-
[13] Android用户界面设计:表格布局
赞助商广告
