您现在的位置:首页
--> MySQL
很多时候,RDS用户经常会问如何调优RDS MySQL的参数,为了回答这个问题,写一篇blog来进行解释:1、哪一些参数不能修改,那一些参数可以修改;2、这些提供修改的参数是不是已经是最佳设置,如何才能利用好这些参数。
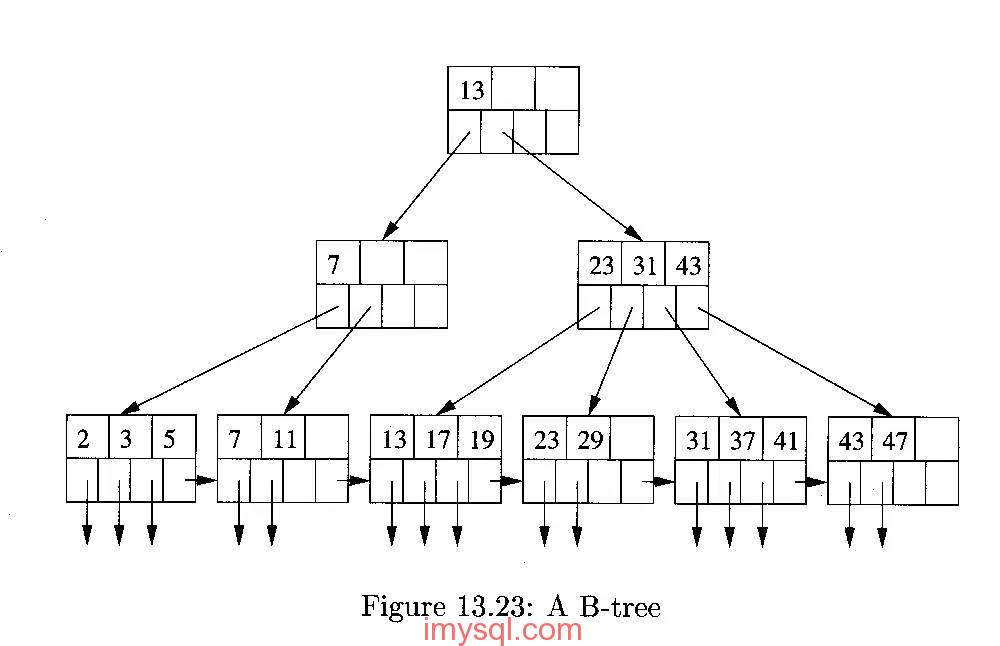
从一个现场说起,全程解析如何定位性能瓶颈。
遇到SLAVE延迟很大,binlog apply position一直不动的情况如何排查?
互联网高速发展的成功,得益于MySQL数据库的给力支持。MySQL本身发展的速度较快,性能方面提升显著,让传统企业也有想法使用MySQL提供服务。目前看来MySQL DBA的缺口非常大。所以欢迎加入到MySQL DBA的团队中来。
有同学一提到MySQL DBA或是DBA都把高难度入门联系到一块。我从事MySQL DBA差不多10几年了,在这里我也给大家讲述一下怎么成为一名MySQL DBA, 少走湾路,快速成为MySQL DBA。
关于 lower_case_table_names 选项的设置的建议是怎样的呢?我个人认为,纠结于这个选项设置源于有些项目是从ORACLE或SQL Server迁移过来,在这两个数据库系统中,都无需关心数据表的大小写。而在MySQL中,默认是要区分大小写的(因为Unix/Linux文件系统是区分文件名大小写的),除非在windows系统下(windows系统是不区分大小写的)。
当磁盘空间爆满后,MySQL会发生什么事呢?又应该怎么应对?
关于在linux上二进制部署mysql,我其实现在linux已经很熟练了,那是一年前的曲折之路。不过这篇文章还是有参考意义,毕竟测试环境可以再3分钟就弄好mysql服务器.还是很happy的一件事情.之前笔记是参考别人写的,现在重新整理.主要问题是centos和ubuntu上,ubuntu上需要注意的事项等说明。
EXPLAIN的结果中,有哪些关键信息值得注意呢?
在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别?
EXPLAIN中的key_len一列表示什么意思,该如何解读?
EXPLAIN执行计划中有一列 key_len 用于表示本次查询中,所选择的索引长度有多少字节,通常我们可借此判断联合索引有多少列被选择了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符等等。

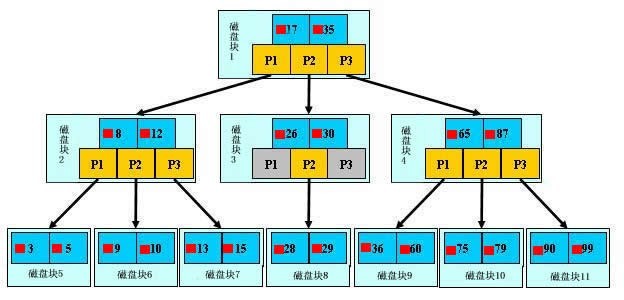
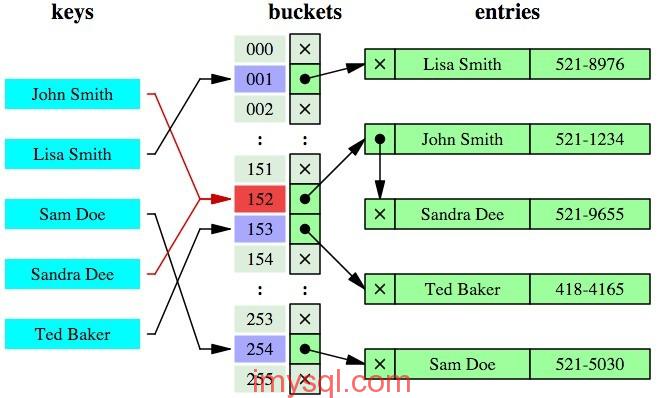
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者w开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
在mysql的innodb引擎的数据库异常恢复中,一般都要求有主键或者唯一index,其实这个不是必须的,当没有index信息之时,可以在整个表级别的index_id进行恢复。
• SQL 新手指南




本文我们浏览了涵盖 CRUD 四个基本的数据库功能:比如:`CREATE TABLE`, `INSERT INTO`, `SELECT`, `UPDATE`, `DELETE` 和 `DROP`。当 SQL 开发人员新手在开始数据库工作、以及使用一门新语言 SQL 时,本文中的基本知识应该能为他们开个好头。



在金融数据库中,由于强一致性是必选项,因此,要做到持续可用比较困难,但也并不是不可能,CAP和持续可用并不矛盾。成熟的商业数据库都是基于共享存储的,不过基于Paxos的持续可用方案开始越来越多地应用到核心场景,例如Google Spanner,Microsoft SQL Server云版本,Amazon DynamoDB,而Aliababa OceanBase也在金融核心场景得到了验证。同时,笔者认为,采用Paxos协议,虽然工程难度很高,但是,只要在实现上做到极致,在同城的情况下,可以容忍单个IDC故障,且性能损耗非常小;而在异地的场景,考虑到光速不可突破,往往由业务在一致性和可用性之间权衡。越来越多的云数据库将会采用Paxos来实现持续可用。
这里所说的数据结构是针对 redis 内部存储 key-value 的,其他诸如 redis 配置相关的数据结构,不在此篇讨论范围。
在 redis 中,允许用户设置最大使用内存大小 server.maxmemory,在内存限定的情况下是很有用的。譬如,在一台 8G 机子上部署了 4 个 redis 服务点,每一个服务点分配 1.5G 的内存大小,减少内存紧张的情况,由此获取更为稳健的服务。redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略。
在MSSM的FREELIST下, 高水位High Water Mark代表所有相关块, 高水位以上就是未格式化unformatted 的数据块,INSRT数据时不能直接使用。当FREELIST中不包含可插入数据块时 HWM默认每次上升5个数据块。 对于ASSM管理的BITMAP 数据段而言,Oracle允许在数据段的中部出现unformatted blocks未格式化的数据块, 基于以下的原因。。。。
自从NoSQL概念横空出世,关系数据库似乎就成了众矢之的,似乎一夜之间,关系数据库和SQL就成了低效,高成本,速度慢的数据处理模式的代名词。 在很多地方都能看到类似:”我的项目初创,应该选择什么NoSQL产品才能快速的开发?” 这样的问题。
近3天十大热文
-
 [64] 招聘技巧一二
[64] 招聘技巧一二 -
[14] [译]Google Chrome中的高性能网
-
[14] 关于Linux的文件系统cache
-
[14] 在FreeNAS/BSD搭建基于Nginx+
-
[13] 最近总结的一些技巧(vim,python,s
-
[12] Linux常用系统信息查看命令
-
[10] 我对技术方向的一些反思
-
[10] 如何让ssh登录更加安全
-
[9] Redis和Memcached的区别
-
[9] Linux(Ubuntu 10.04)上安装
赞助商广告
