您现在的位置:首页
--> 算法
在命令式编程中,我们解决一些问题往往可以使用循环来代替递归,这样便不会因为数据规模造成堆栈溢出。但是在函数式编程中,要实现“循环”的唯一方法便是“递归”,因此尾递归和CPS对于函数式编程的意义非常重大。了解尾递归,对于编程思维也有很大帮助,因此大家不妨多加思考和练习,让这样的方式为自己所用。
以前我也在博客上简单谈过“尾递归”及其优化方式方面的话题。前几天有同学在写邮件向我提问,说是否所有的递归算法都能改写为尾递归,改写成尾递归之后,是否在时间和空间复杂度方面都能有所提高?他以斐波那契数列为例,似乎的确是这样的情况。我当时的回答有些简单,后来细想之后似乎感觉有点问题,而在仔细操作之后发现事情并没有理论上那么简单,因此还是计划写篇文章来讨论下这方面的问题。 斐波那契数列 大家对于斐波那契数列(Fibonacci)的认识一定十分统一,唯一的区别可能仅在于n是从0开始还是从1开始算起。
最近有段十分流行的代码,是从江湖传闻“身怀八蛋”的铁道部发言人王勇平同志的一句名言:“不管你们信不信,反正我信了……这是生命的奇迹……它就是发生了”所引申出来的。这段代码虽然只是在调侃,但是围绕这段代码也产生了一些讨论(如代码风格,编程规范等等),在此顺手记录一下,就当无聊罢。
今天早上一边出门一边在平板上读了左耳朵耗子的新文章《为什么我反对纯算法面试题》,略有想法。正逢外面暴雨如注,我就又回屋打开笔记本发了一些回复,特此整理一下。为了避免有人扭曲我的看法,我先声明我并不是反对这篇文章,相反我是基本同意其中的观点,只不过会加以一些补充,把其中一些我认为有些过头的地方按一按。您也可以认为我的观点是提交一些补丁,发了一些Pull Request(当然不是这种Pull Request)就行了。我当时吐的第一个槽,是说文章太鄙视搞学术研究的人,说他们是书呆子,不关心业务需求,认为那是应试教育不会思考的产物。这个么其实不是重点,只不过触到了我的学术研究情结罢了,接下来的才是我真正想说的。 耗子的文章以前两天的一个讨论引出话题,那是一道面试题:“找出无序数组的第2大的数”,而在当时的面试中,“排序”后再取数被判为不合格的答案。
今天发现 Skynet 消息处理的一个 bug ,是由多线程并发引起的。又一次觉得完全把多线程程序写对是件很不容易的事。我这方面经验还是不太够,特记录一下,备日后回顾。 Skynet 的消息分发是这样做的: 所有的服务对象叫做 ctx ,是一个 C 结构。每个 ctx 拥有一个唯一的 handle 是一个整数。 每个 ctx 有一个私有的消息队列 mq ,当一个本地消息产生时,消息内记录的是接收者的 handle ,skynet 利用 handle 查到 ctx ,并把消息压入 ctx 的 mq 。 ctx 可以被 skynet 清除。为了可以安全的清除,这里对 ctx 做了线程安全的引用计数。每次从 handle 获取对应的 ctx 时,都会对其计数加一,保证不会在操作 ctx 时,没有人释放 ctx 对象。




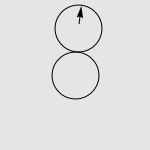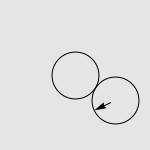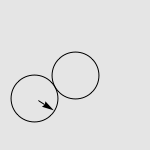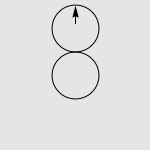
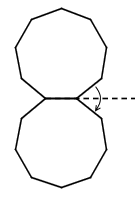
有一道非常经典的智力问题:假设有两个一模一样的硬币 A 和硬币 B ,如果让硬币 B 不动,让硬币 A 贴着硬币 B 旋转一周,那么硬币 A 自身旋转了多少周?一个常见的错误答案是“显然也是一周啊”,而实际上正确的答案是两周,如下图所示。我们有很多方法来解释这种现象,其中最传统的说法便是“公转了一周,自转了一周”。硬币 A 的运动是由两部分合成的,公转一周(想像一个人绕着地球走了一圈),以及自转一周(想像一个轮子在地面上滚动了一周)。想像你是站在硬币 B 中心处的一个小人儿,看着硬币 A 贴着你脚下的硬币转动一圈。如果在此过程中,你始终面向硬币 A ,那么在你看来,硬币 A 似乎就是在长为 2πr 的平地上滚了一圈。而实际上,在观察硬币 A 的过程中,你自己也原地转了 360 度,因此从外面的人开来,硬币实际上转了两周。
• 树与存储



二叉树: 一个根节点,每个节点下挂着最多2个子节点。、 概念: 度:结点的分支数,二叉树度为2。 深度:树的层次。 二叉排序树: 二叉树的基础上,每个节点上都有一个数字,节点上的数字都比右节点上的大。 应用场景: 基于内存的排序数据结构,写入时将数据写入到对应的位置。数据可能会出现倾斜,可以想到数字写入顺序如果不是50-20-60-18-55,而是18-20-50-55-60,那么二叉树就会退变为链表。 B-树: B-树每个节点上包含着数据和指针,每个指针指向其一个子节点的位置,并且数据的个数为指针的2d-1个。这里的d是指针的个数,同时也是树的“度”。 B-树的查找需要一次对每个节点进行二分查找,直至找到或返回null。通常,可以引入布朗过滤器等方式加速查找。 B-树的写入、删除时要进行分裂、合并、转移等操作,越是非顺序的插入就越容易碰到这些高性能消耗的操作。
当我们在修改数据结构中某个副本时,为了修改过程的原子性,我们需要复制一个副本出来,修改,然后利用 CAS 交换到主干上。这个过程中,其它读线程,可能引用老的版本,读完后就需要销毁掉过期的版本。在有 GC 机制的语言中这非常简单。但是在 C/C++ 这种手动管理内存的条件下,几乎变得不可能。对,我们可以用引用计数来管理。但难点在于引用记数本身需要放在对象上,那么改写引用值却需要获得对象本身先,这个变成了绕不过去的死结。在并发条件下,如果你不使用锁,那么获得对象指针后,到操作引用记数之间,无法确保对象不在那一刻被其它线程减少引用而销毁掉。
考虑一个传统的猜数游戏。 A 、 B 两名玩家事先约定一个正整数 N ,然后 A 在心里想一个不超过 N 的正整数 x , B 则需要通过向 A 提问来猜出 A 心里想的数。 B 的问题只有唯一的格式:先列出一些数,然后问 A “x 是否在这些数里”, A 则需要如实回答“是”或者“否”。显然, B 是保证能猜到 x 的,只需要依次询问“x 是否等于 1 ”,“x 是否等于 2 ”即可。由于 B 可以精心选出满足某种特征的所有数,询问 x 是否在这些数里,因而 B 还可以做得更好。例如当 N = 16 时, B 第一次可以问“x 是否小于等于 8 ”,或者等价地,“x 是否属于 {1, 2, 3, [...]




在电子竞技游戏中,特别是当有多名选手参加比赛的时候需要平衡队伍间的水平,让游戏比赛更加有意思。这样的一个参赛选手能力平衡系统通常包含以下三个模块: 一个包含跟踪所有玩家比赛结果,记录玩家能力的模块。 一个对比赛成员进行配对的模块。 一个公布比赛中各成员能力的模块。 事实上目前已经有的游戏评分系统是Elo评分,但是Elo评分仅只是两名选手参加的游戏。TrueSkill系统是基于贝叶斯推断的评分系统,由微软研究院开发以代替传统Elo评分,并成功应用于Xbox Live自动匹配系统。TrueSkill评分系统是Glicko评分系统的衍伸,主要用于多人游戏中。TrueSkill评分系统考虑到了你水平的不确定性,综合考虑了玩家的胜率和可能的水平涨落。当玩家进行了更多的游戏后,即使你的胜率不变,系统也会因为对你的水平更加了解而改变对你的评分。
• 原子字典
一个需求:一个玩家数据的写入者,可以批量修改他的属性。但是,同时可能有其他线程在读这个玩家的数据(通过共享内存)。这可能造成,读方得到了不完整的数据。 我们可以不在乎读方得到某个时间的旧数据,但不可以读到一份不完整的版本。就是说,对玩家数据的修改,需要成组的修改,每组修改必须是原子的。 起先,我想用读写锁来解决这个问题。方案想好了,一直没有实现。只是把读写锁的基本功能实现了。 这几天这个问题被重提出来。因为,前段我们都采用了鸵鸟政策,当问题不存在(事实上我们也没有发现实际中出现可观测到的问题)。 反正探讨了好几个解决方案,一开始都是围绕怎么加锁,锁的粒度有多大来展开的。甚至,我们把其中的一种方案都实现出来了,并写了压力测试程序测试。不过,这些方案都不太令人满意。




我们做设计时常是在做信息的组织,差异的控制。而什么样的信息组织可以被用户更好的接收,被更有效率的认知,可以从人是怎么认知事物而来探讨下,毕竟用户的认知是具有普遍规律性的,但是模式的发现与利用并不是一件容易的事,“误解”常常也是人类特质的表现之一。 在计算机学科里有一个专业方向叫“模式识别”,Pattern Recognition。是指通过借助计算机,对人类外部世界某一特定环境中的客体、过程和现象进行自动识别的技术。这个技术在我们身边最典型的应用应该是现在各种相机里的人脸识别技术
在前端领域,很少会遇到算法问题,这不能说不是一种遗憾。不过,随着前端处理的任务越来越复杂和重要,偶尔,也能遇到一些算法上的问题。本文,所要讨论的,就是这样一样问题。 什么是SKU 问题来自垂直导购线周会的一次讨论,sku组合查询,这个题目比较俗,是我自己取得。首先,看下什么是sku,来自维基百科的解释: 最小存货单位(Stock Keeping Unit)在连锁零售门店中有时称单品为一个SKU,定义为保存库存控制的最小可用单位,例如纺织品中一个SKU通常表示规格、颜色、款式。


与文章新闻类排名不同的事,评论类的算法可能发表时间没有什么关系。 目前很多网站采用的评论排名主要有两种,即绝对好评数(好评减去差评)和好评率(好评/总评)。这两种评价方式 都存在很明显的缺陷,以下为事例: A:好评550; 差评450 B:好评60;差评40 C:好评1;差评0 D:好评9,差评1 首先是A与B比较,A的绝对好评数是550-450=100,B的绝对好评数是60-40=20,从绝对好评数比较,A的排名应该在B的前面;A的好评率为550/(450+550)=55%,B的好评率为60/(40+60)=60%,从好评率来说B的排名要比A的排名好。 再来比较下C与D,从好评率出发,C的好评率为100%,而D的好评率为9/(1+9)=90%,单纯从数据上看D的排名要比C的排名落后。




Hacker News 是一家关于计算机黑客和创业公司的社会化新闻网站,由 Paul Graham 的创业孵化器 Y Combinator 创建。与其它社会化新闻网站不同的是 Hacker News 没有踩或反对一条提交新闻的选项(不过评论还是可以被有足够 Karma 的用户投反对票,或是投支持票);只可以赞或是完全不投票。简而言之,Hacker News 允许提交任何可以被理解为“任何满足人们求知欲”的新闻。 每个新闻标题前面有一个向上的三角形,如果你觉得这个内容很好,就点击一下,投上一票。根据得票数,系统自动统计出热门文章排行榜。但是,并非得票最多的文章排在第一位,还要考虑时间因素,新文章应该比旧文章更容易得到好的排名。




在电影《社交网络》的开始有这么一段,扎克博格由于被女友甩了,所以需要做一个网站,用来推选哈佛最漂亮的女生。网站的逻辑非常的简单,就是系统从照片库中随机挑出两幅女生照片,选择两者较“美”者。就是这么一个网站在上线两小时(周末凌晨两点到四点)内点击量达到了2万2千次,从而导致了哈佛网络的瘫痪。(备注:最近华中科技大学女生的照片也被类似的放到了网上评比,并且使用山寨的域名) 信息的关注应该注意到,上述功能中涉及到一个排名规则,是由扎克博格那位同学提供的,他把公式写在了窗户上,如下截图: 上面的公式主要作用作用是用来对进行女生的分数进行评比,从而确定哪些是最优质女生。不过让人遗憾的是电影中给出的这个公式是错误的公式,真正的公式应该如下: 即分数线下方是1+10的幂次,而非10的倍数。


StackOverflow的排序共分为两类,1个是问题排序,1个是答案排序。这里主要介绍的是关于热门问题的排序。 在分析问题前可以先考虑下,如果是你来做这个排名算法需要考虑哪些因素? 1、问题的投票人数,StackOverflow允许用户投反对票,所以这里可以使用绝对投票数,即正面票-负面票数量。绝对数越高问题越热门。 2、问题浏览量,或是有效浏览量,有效浏览量可以建立一个停留时间的阀值去衡量。浏览的越多则越热门。 3、问题的答案数,理论上说答案越多则问题的越热门,但这也并不绝对,有些好的问答可能只有一个好的答案。 4、问题答案的认可数,即是否存在一个被大量认可的答案。这里存在两种情况,被提问者认可或被其他访问者投票。
策略开发人员在完成策略之后,在全流量上线之前要评估新的策略的优劣,常用的评估方法是A-B测试,做法是在全流量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出新策略的优劣,进而决定新策略是否全流量。我们把抽样的过程分为流量切分和流量筛选两个步骤。流量切分的逻辑较为复杂,包含多种切分类型和多层嵌套,另外为了保证灵活性,层的组合应该是任意的。
近3天十大热文
-
 [17] [译]Google Chrome中的高性能网
[17] [译]Google Chrome中的高性能网 -
[14] 最近总结的一些技巧(vim,python,s
-
[14] 在FreeNAS/BSD搭建基于Nginx+
-
[14] 关于Linux的文件系统cache
-
[13] Linux常用系统信息查看命令
-
[11] Linux(Ubuntu 10.04)上安装
-
[9] Centos yum 安装nginx+PHP
-
[8] 浏览器缓存机制
-
[8] base64_encode 和 urlenc
-
[8] PHP加速器 eaccelerator 缓存
赞助商广告
