您现在的位置:首页
--> 算法



在 redis 中有多个数据集,数据集采用的数据结构是哈希表,用以存储键值对。默认所有的客户端都是使用第一个数据集,如果客户端有需要可以使用 select 命令来选择不同的数据集。redis 在初始化服务器的时候就会初始化所有的数据集.。。。。。


redis 中 zset 是一个有序非线性的数据结构,它底层核心的数据结构是跳表. 跳表(skiplist)是一个特俗的链表,相比一般的链表,有更高的查找效率,其效率可比拟于二叉查找树。

MULTI,EXEC,DISCARD,WATCH 四个命令是 redis 事务的四个基础命令。其中:MULTI,告诉 redis 服务器开启一个事务。注意,只是开启,而不是执行;EXEC,告诉 redis 开始执行事务;DISCARD,告诉 redis 取消事务;WATCH,监视某一个键值对,它的作用是在事务执行之前如果监视的键值被修改,事务会被取消。在介绍 redis 事务之前,先来展开 redis 命令队列的内部实现。




验证码主要是防止机器暴力破解。之前的验证码都是以静态为主,现在一些产品开始使用动态方式,增加破解的难度。动态方式以 gif 最为简单可靠。gif 兼容性好,尺寸小。这里分享的就是一种:用 JS 实现 gif 动态验证码的思路。
intset 和 dict 都是 sadd 命令的底层数据结构,当添加的所有数据都是整数时,会使用前者;否则使用后者。特别的,当遇到添加数据为字符串,即不能表示为整数时,redis 会把数据结构转换为 dict,即把 intset 中的数据全部搬迁到 dict。
TokuMX的一大创新在于,它打破了一条长久存在的关于数据库的规则:要保证好的写入性能,索引的工作集应当能够放在内存里。标准答案是这样的:如果索引的工作集比内存要大,写入就需要执行I/O,I/O就会成为限制因素,性能就会下降。所以,要么让索引小到能全部放进内存,要么提供一种索引写入模式,避免工作集过大,比如MongoDB所采用的,内存中只为最近插入的数据保存索引。
问题 如何能使得一些信息可以存储更小?



Kyle McCormick 在 StackExchange 上发起了一个叫做 Tweetable Mathematical Art 的比赛,参赛者需要用三条推这么长的代码来生成一张图片。具体地说,参赛者需要用 C++ 语言编写 RD 、 GR 、 BL 三个函数,每个函数都不能超过 140 个字符。

15道常见的基础算法题:1、合并排序,将两个已经排序的数组合并成一个数组,其中一个数组能容下两个数组的所有元素; 2、合并两个已经排序的单链表;3、倒序打印一个单链表; 4、给定一个单链表的头指针和一个指定节点的指针,在O(1)时间删除该节点;5、找到链表倒数第K个节点;6、反转单链表;7、通过两个栈实现一个队列;8、二分查找;9、快速排序;10、获得一个int型的数中二进制中的个数;11、输入一个数组,实现一个函数,让所有奇数都在偶数前面;12、判断一个字符串是否是另一个字符串的子串;13、把一个int型数组中的数字拼成一个串,这个串代表的数字最小;14、输入一颗二叉树,输出它的镜像(每个节点的左右子节点交换位置);15、输入两个链表,找到它们第一个公共节点;


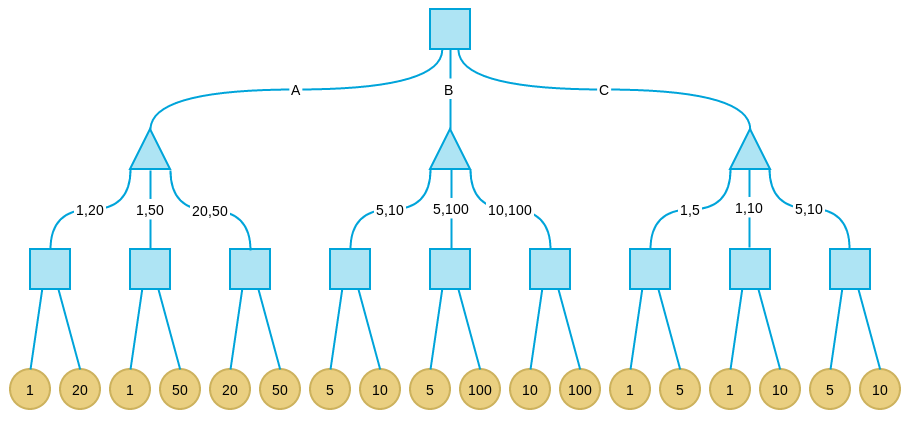
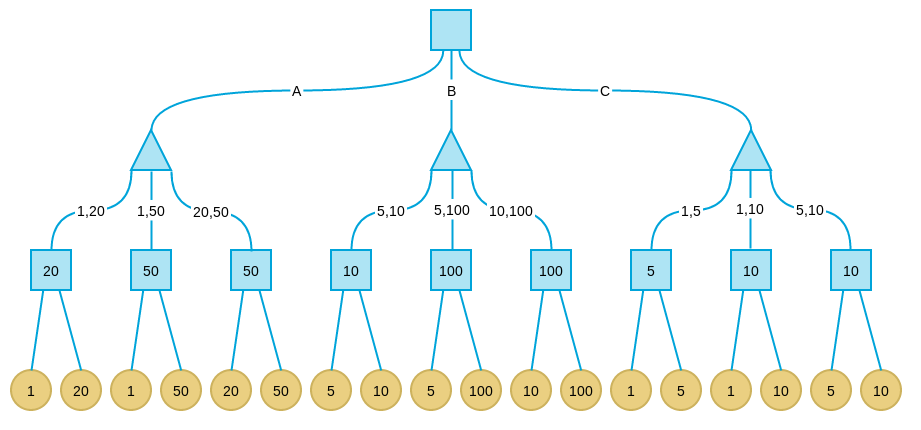
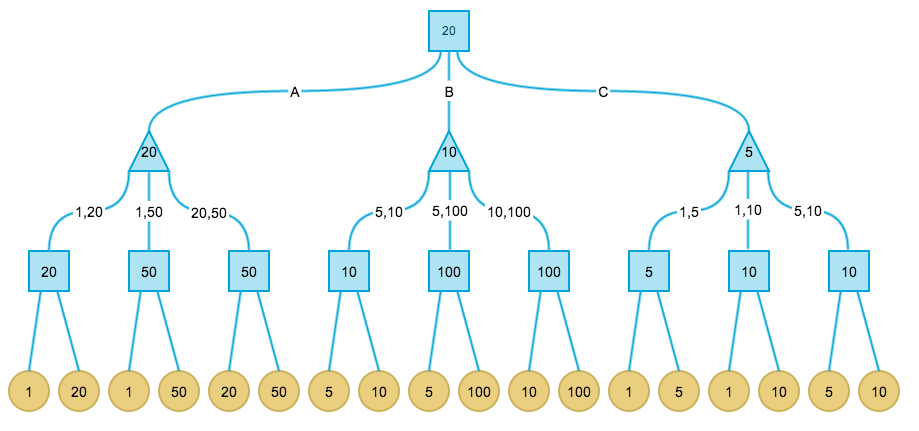
针对目前火爆的2048游戏,有人实现了一个AI程序,可以以较大概率(高于90%)赢得游戏,并且作者在stackoverflow上简要介绍了AI的算法框架和实现思路。但是这个回答主要集中在启发函数的选取上,对AI用到的核心算法并没有仔细说明。这篇文章将主要分为两个部分,第一部分介绍其中用到的基础算法,即Minimax和Alpha-beta剪枝;第二部分分析作者具体的实现。
用 k × 1 的小矩形覆盖一个 n × n 的正方形棋盘,往往不能实现完全覆盖(比如,有时候 n × n 甚至根本就不是 k 的整倍数)。不过,在众多覆盖方案中,总有一种覆盖方案会让没有覆盖到的方格个数达到最少,我们就用 m(n, k) 来表示这个数目。求证:不管 n 和 k 是多少, m(n, k) 一定是一个完全平方数。
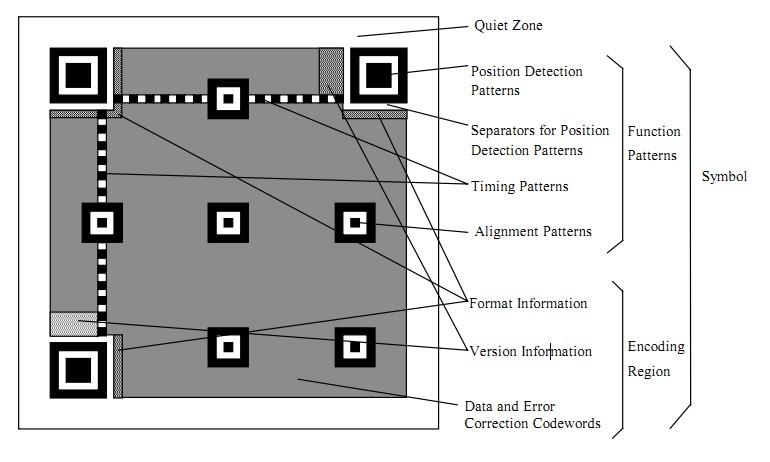
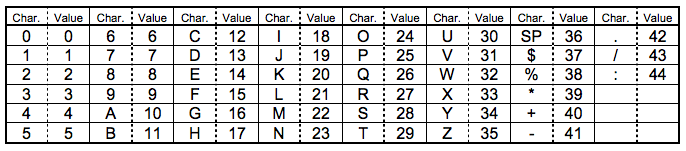
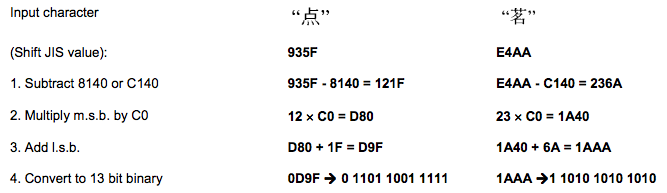
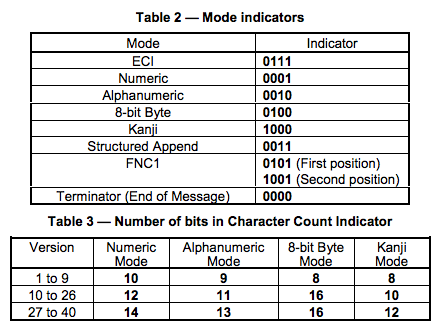
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。

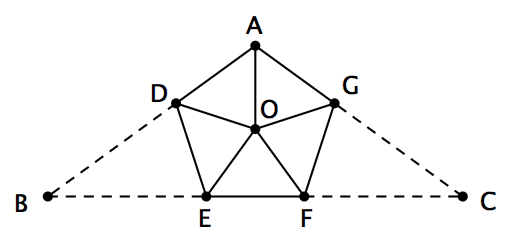
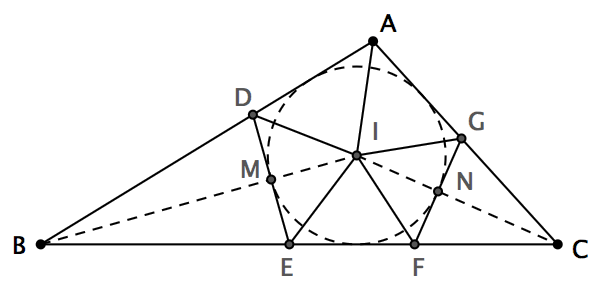
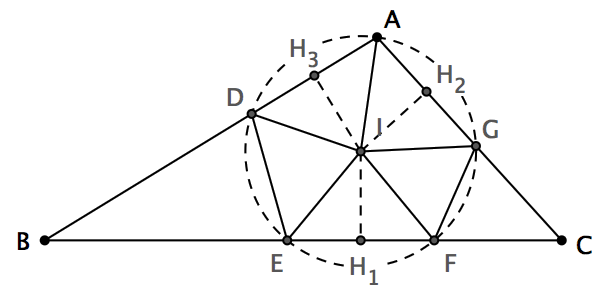
这是我最喜欢的几何谜题之一:你能否在纸上画一个钝角三角形,然后把它分割成若干个锐角三角形?令人难以置信的是,这竟然是可以办到的!继续看下去之前,大家不妨先自己想一会儿。
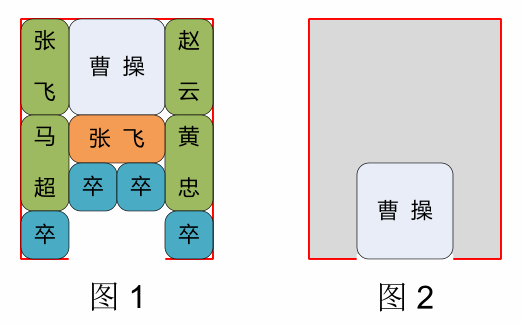
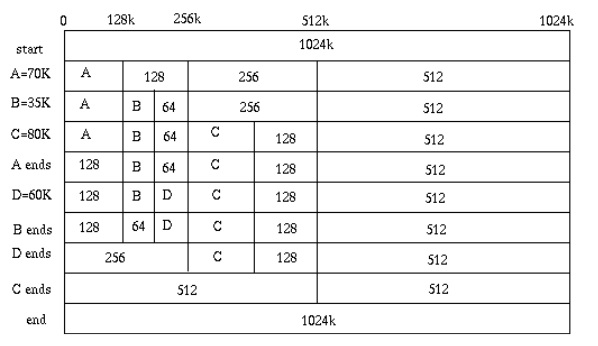
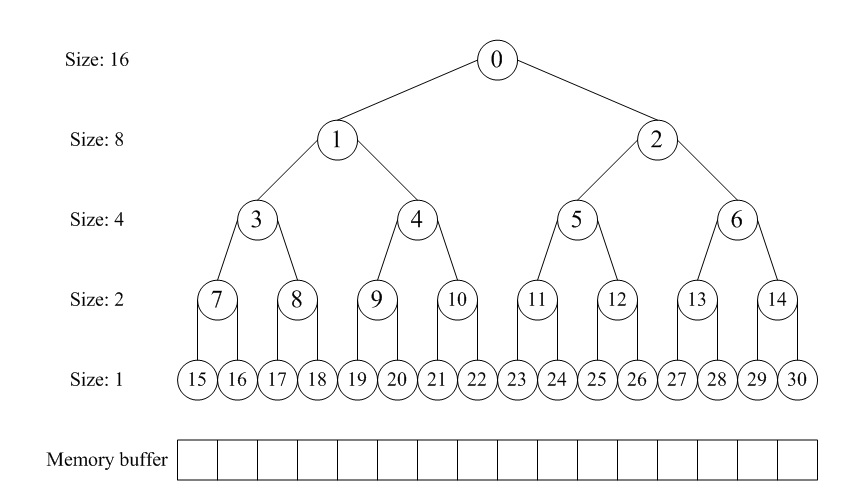
伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。
在之前的一片文章(迷宫营救公主算法)中提供了一个半成品的解决方案,之所以说他是半成品,是因为首先选择的算法就不对,采用的是深度优先搜索,其次也没有真正的用对深度优先算法,走过的点应该标记为已经走过,而不应该重复遍历该节点。下面的文章对于广度优先和深度优先两种算法的解释非常到位。今天准备把这个问题再完整的用正确的算法解答一遍。
• 大整数乘法
很长时间都没写过代码了,试着写了这个常见的题目。整体思路:采用整形链表记录大整数的每一位,然后分别遍历乘数和被乘数的每一位,将每两个数字的乘积累加到结果的相应位上面。针对大整数类型,重载输入和输出流,重载乘法。
近3天十大热文
-
 [589] 招聘技巧一二
[589] 招聘技巧一二 -
[17] 我的git笔记
-
[16] 豆瓣是啥?
-
[16] 数据分析中常用的数据模型
-
[15] 30分钟3300%性能提升――python+
-
[15] 给自己的字体课(一)——英文字体基础
-
[15] Android用户界面设计:表格布局
-
[14] jQuery性能优化指南
-
[14] iOS 8/Android/WP 系统设置的
-
[14] 密度聚类算法之OPTICS
赞助商广告
