您现在的位置:首页
--> 算法
Windows平台下 如果以“文本”方式打开文件,当读取文件的时候,系统会将所有的”/r/n [...]The post 文本与二进制方式打开文件的区别 appeared first on PHPor 的Blog.
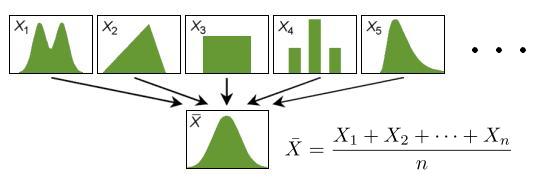

19世纪初,随着拉普拉斯中心极限定理的建立与高斯正态误差理论的问世,正态分布开始崭露头角, 逐步在近代概率论和数理统计学中大放异彩。在概率论中,由于拉普拉斯的推动,中心极限定理发展 成为现代概率论的一块基石。而在数理统计学中,在高斯的大力提倡之下,正态分布开始逐步畅行于天下。
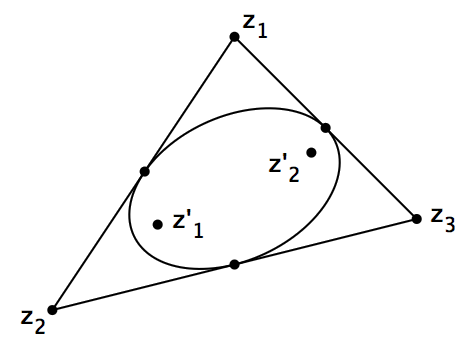
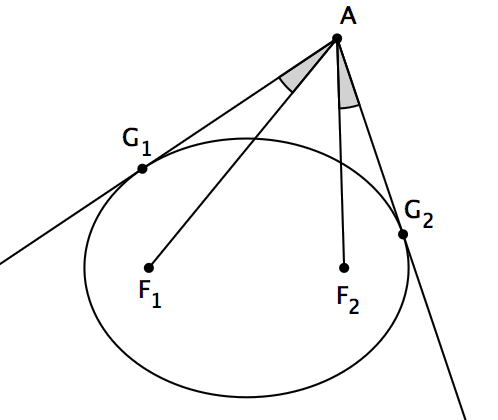
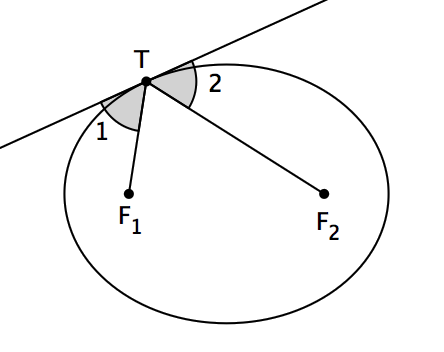
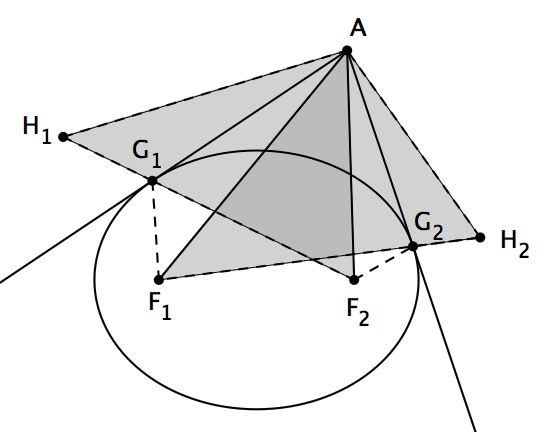
设 p(z) 是一个复数域上的三次多项式, z1 、 z2 、 z3 是 p(z) 的三个根,它们在复平面上不共线。那么,在这个复平面上存在唯一的椭圆,使得它与三角形 z1z2z3 的各边都相切,并且都切于各边的中点处。并且,这个椭圆的两个焦点是 p'(z) 的两根。


我们的游戏中需要对渲染字体做勾边处理,有种简单的方法是将字体多画几遍,向各个方向偏移一两个像素用黑色各画一遍,然后再用需要的颜色画一遍覆盖上去。这个方法的缺点是一个字就要画多次,影响渲染效率。

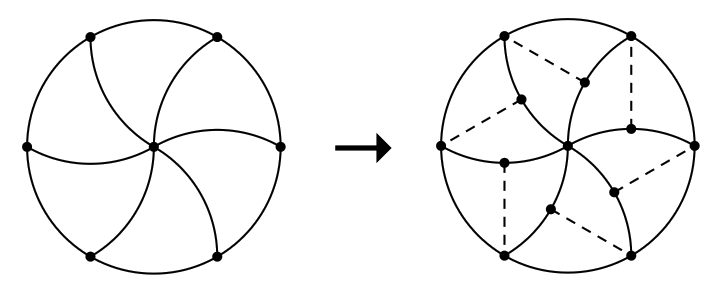
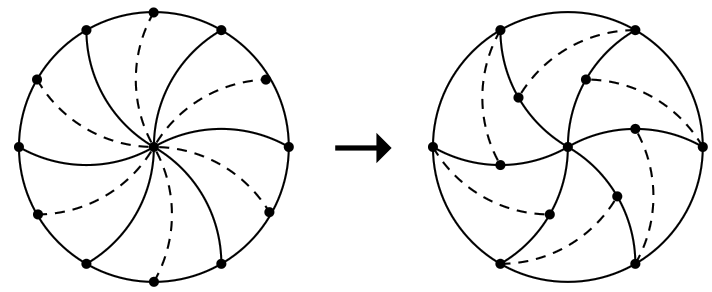
请你把一个圆形的比萨分成若干个大小形状都相同的部分,使得其中至少有一部分不含有比萨的边儿。换句话说,你需要把一个圆分成若干个全等的部分,其中至少有一个部分不包含任何一段圆周。
一般来说,如果你希望数据能够被快速的找到,那么最主要的两种技术手段就是二分查找,或者使用Hash函数。今天来介绍一个最简单的数据结构,有序数组来组织的二分查找,当然,我的主要目标是介绍前人解决问题的思路,而非算法本身,所以不会尝试用比较难理解的公式和伪码来描述问题。



一谈到二叉树,相信很多人一定会有一个疑问: 这玩意儿有什么用? (当然这么多人里面肯定包括大学时候的我- -)
其实,我个人觉得这并不怪我们,是教科书写的有点问题,开始的时候没有给到大家明确的学习意义,开始就去讲如何遍历,如何从树变森林,如何做树的前序中序后序遍历。但这样的学习会让整个过程很无聊,太容易让人放弃了。所以在今天,请允许我用另外的方式来重新讲解一下吧~
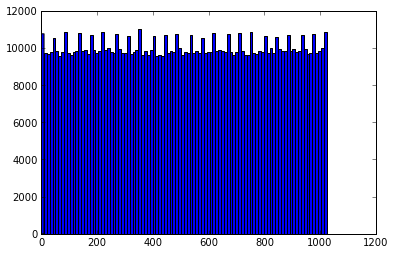
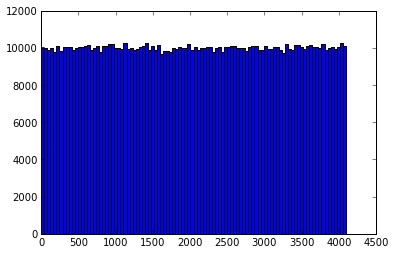
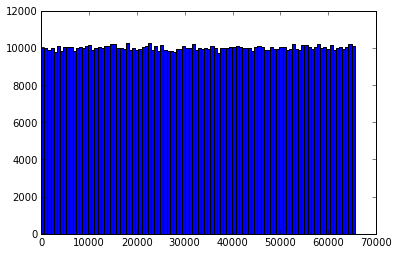
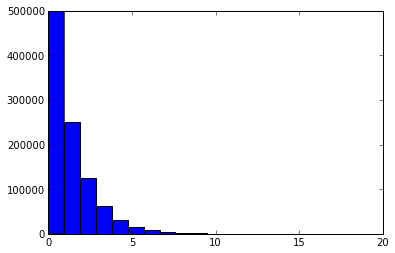
之前我曾写过一系列关于基数估计(cardinality estimation)算法的文章,文中介绍了一些常用基数估计算法的原理。最近对常用的基数估计算法做了一些实验,这篇文章描述了实验结果,包括这些算法的估计效果及误差状况,主要通过图表展示。通过观察实验数据和可视化图表可以加强对各种基数估计算法理论分析的直观理解。文章首先会对实验做一些说明,然后通过图表详细展示实验数据,最后会根据实验结果总结一些实践中有用的结论。同时文末会附上相关的参考文献及原始数据。






这篇文章我要向大家介绍Hacker News网站的文章排名算法工作原理,以及如何在自己的应用里使用这种算法。这个算法非常的简单,但却在突出热门文章和遴选新文章上表现的异常优秀。

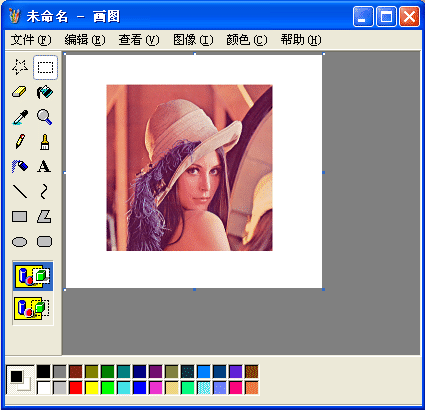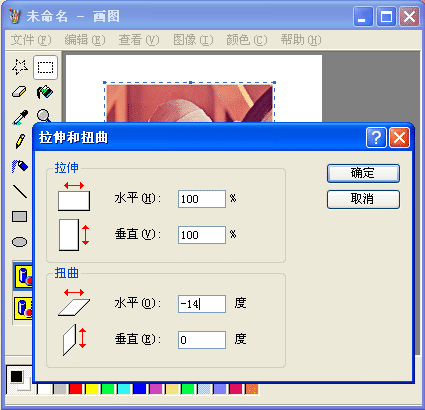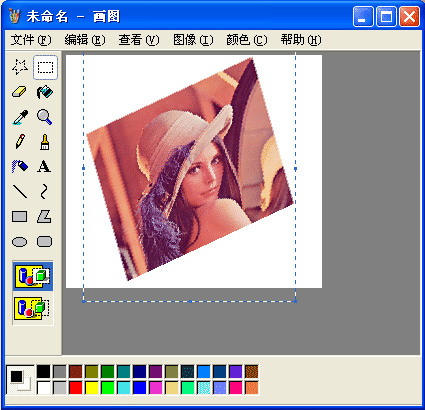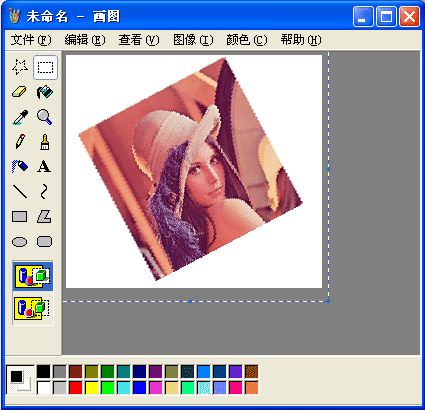
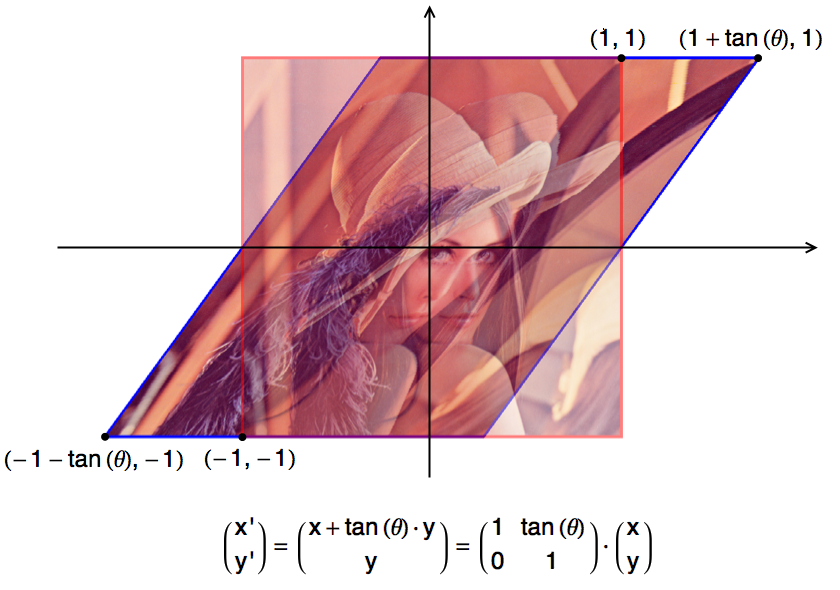
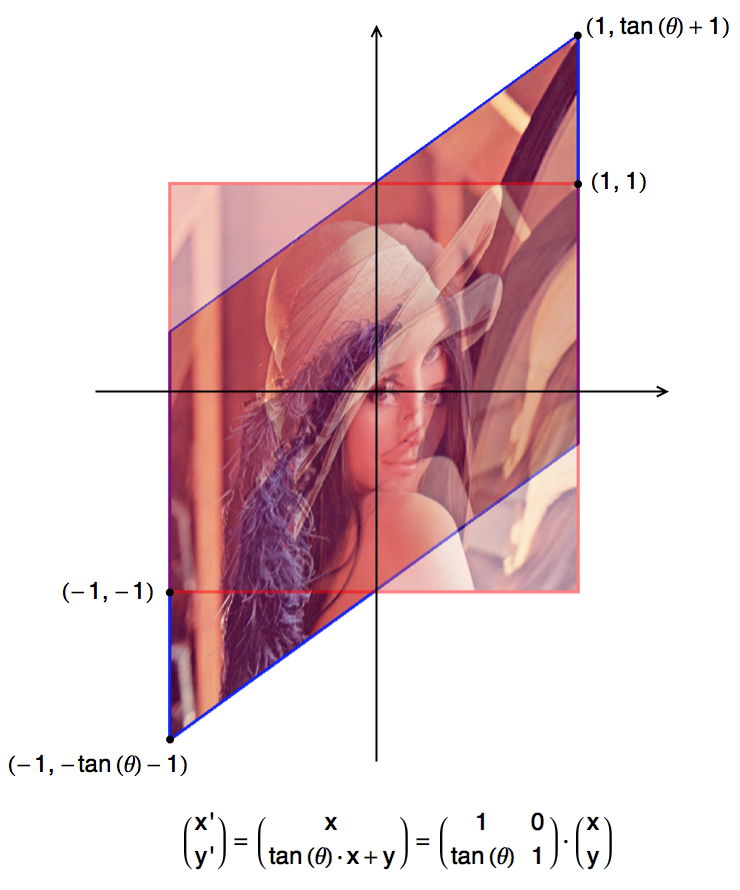
在早期的小型图像编辑软件中,考虑到时间空间的限制,再加上算法本身的难度,很多看似非常简单的功能都无法实现。比如说,很多图像编辑软件只允许用户把所选的内容旋转 90 度、 180 度或者 270 度,不支持任意度数的旋转。毕竟,如果我们只是旋转 90 度的整数倍,那么所有像素仅仅是在做某些有规律的轮换,这甚至不需要额外的内存空间就能完成。但是,如果旋转别的度数,那么在采样和反锯齿等方面都将会有不小的挑战。

本文将继续围绕Solr+Lucene使用Cartesian Tiers 笛卡尔层和GeoHash的构建索引和查询的细节进行介绍。
在Solr中其实支持很多默认距离函数,但是基于坐标构建索引和查询的主要会基于2种方案:
(1)GeoHash;
(2)Cartesian Tiers+GeoHash;
而这块的源码实现都在lucene-spatial.jar中可以找到。接下来我将根据这2种方案展开关于构建索引和查询细节进行阐述,都是代码分析,感兴趣的看官可以继续往下看。




在Solr中基于空间地址查询主要围绕2个概念实现: Cartesian 、Tiers 、笛卡尔层。 Cartesian Tiers是通过将一个平面地图的根据设定的层次数,将每层的分解成若干个网格。
• 谈谈页面停留时间
页面停留时间表示用户的一次浏览行为花了多少时长在这个页面上。直接体现出用户愿意花多长时间在你的页面上,所以通过这个指标,可以衡量一些网站页面、网站产品定位和设计的优劣。因此,页面停留时间是网站优化的一个较为重要和常见的参考指标。

上一节我们用了一个简单的例子过了一遍gensim的用法,这一节我们将用课程图谱的实际数据来做一些验证和改进,同时会用到NLTK来对课程的英文数据做预处理。
目前中文分词的一般做法是将分词当作序列标注问题来处理,这种做法首先标注好一批训练语料,然后用统计模型进行训练和标注。常用的统计模型包括隐马尔可夫模型(HMM)、最大熵模型(MEM)以及条件随机场模型(CRF)。因为CRF比HMM和MEM有更弱的上下文无关假设,所以CRF一般能取得更好的分词结果。
• 二叉树迭代器算法
二叉树(Binary Tree)的前序、中序和后续遍历是算法和数据结构中的基本问题,基于递归的二叉树遍历算法更是递归的经典应用。
近3天十大热文
-
 [588] 招聘技巧一二
[588] 招聘技巧一二 -
[17] 我的git笔记
-
[16] 数据分析中常用的数据模型
-
[16] 豆瓣是啥?
-
[15] Android用户界面设计:表格布局
-
[14] jQuery性能优化指南
-
[14] 一次神奇的MySQL优化
-
[14] 给自己的字体课(一)——英文字体基础
-
[14] 密度聚类算法之OPTICS
-
[13] 在ssh服务里使用chroot
赞助商广告
