您现在的位置:首页
--> 算法
VXLAN 是非常新的一个 tunnel 技术,它是一个 L2 tunnel。Linux 内核的 upstream 中也刚刚加入 VXLAN 的实现。相比 GRE tunnel 它有着很的扩展性,同时解决了很多其它问题。
这篇文章以抛硬币试验为引子引出了一系列现代数学中概率的基本模型、定理及基本的估计及显著性检验方法。写这篇文章是我无聊抛硬币时一时兴起,其中对很多东西只是给出一个轮廓,没有处处给出严格的定义和证明,不过大约说明了常用的一些统计方法及其理论基础,限于篇幅不能面面俱到,例如一个假设检验如果展开写可以单独写一篇文章。目前随着大数据概念的热炒,基于互联网的数据挖掘和机器学习也变得火热,其实很多数据挖掘和机器学习都是基于概率和统计理论的,很多方法甚至只是传统统计方法的应用。因此如果准备在这方面深入学习,不妨考虑先在概率论和数理统计方面打好基础。
• 如何测试洗牌程序
我希望本文有助于你了解测试软件是一件很重要也是一件不简单的事。
我们有一个程序,叫ShuffleArray(),是用来洗牌的,我见过N多千变万化的ShuffleArray(),但是似乎从来没人去想过怎么去测试这个算法。所以,我在面试中我经常会问应聘者如何测试ShuffleArray(),没想到这个问题居然难倒了很多有多年编程经验的人。对于这类的问题,其实,测试程序可能比算法更难写,代码更多。
在《游戏人工智能编程案例精粹 》 和 《 Windows 游戏编程大师技巧 》 中都分别有一章谈及模糊逻辑。记得前几年我的同事 Soloist 同学曾经研究过一小段时间,给我做过简单介绍,我便仔细把这两章书读了一遍。感觉都是点到为止,所以又翻了一下 Wikipedia 的 Fuzzy Logic 的介绍。午饭时跟做 AI 的同事交流了一下,觉得可以做一点笔记记录理解的部分。
• JVM垃圾收集器
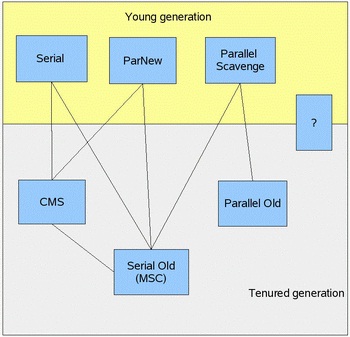
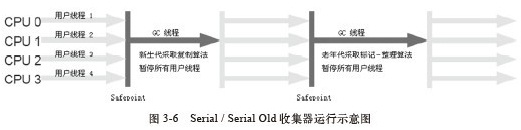
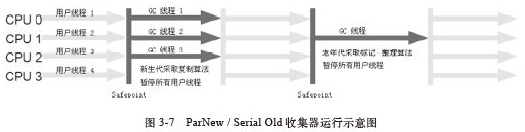
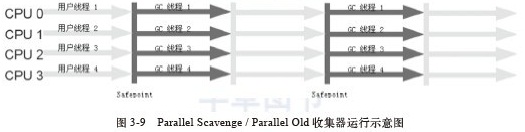
垃圾收集器就是收集算法的具体实现,不同的虚拟机会提供不同的垃圾收集器。并且提供参数供用户根据自己的应用特点和要求组合各个年代所使用的收集器。本文讨论的收集器基于Sun Hotspot虚拟机1.6版。 下图中展示了jdk1.6中提供的6种作用于不同年代的收集器,两个收集器之间存在连线的话就说明它们可以搭配使用。没有最好的收集器,也没有万能的收集器,只有最合适的收集器。从Serial收集器到Parallel收集器,再到CMS收集器, G1收集器,用户线程的停顿时间在不断缩短,但是仍然没有办法完全消除。
Java中的一个byte,其范围是-128~127的,而Integer.toHexString的参数本来是int,如果不进行&0xff,那么当一个byte会转换成int时,对于负数,会做位扩展,举例来说,一个byte的-1(即0xff),会被转换成int的-1(即0xffffffff),那么转化出的结果就不是我们想要的了。
而0xff默认是整形,所以,一个byte跟0xff相与会先将那个byte转化成整形运算,这样,结果中的高的24个比特就总会被清0,于是结果总是我们想要的。
对象的内存分配,就是在堆上分配(但也可能经过JIT编译后被拆散为标量类型并间接地在栈上分配),对象主要分配在新生代的Eden区上,如果启动了本地线程分配缓冲,将按线程优先在TLAB上分配。少数情况下也可能会直接分配在老年代中,分配的规则并不是百分之百固定的,其细节取决于当前使用的是哪一种垃圾收集器组合,还有虚拟机中与内存相关的参数的设置。
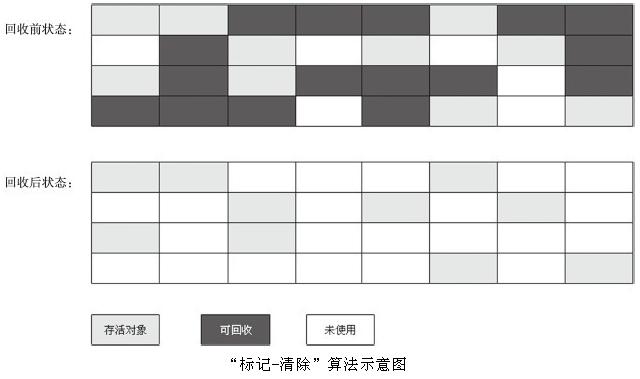
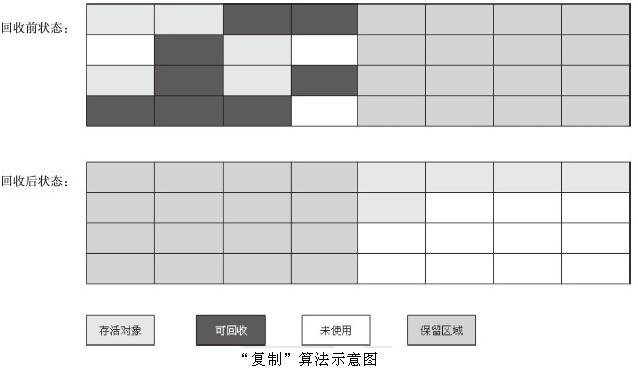
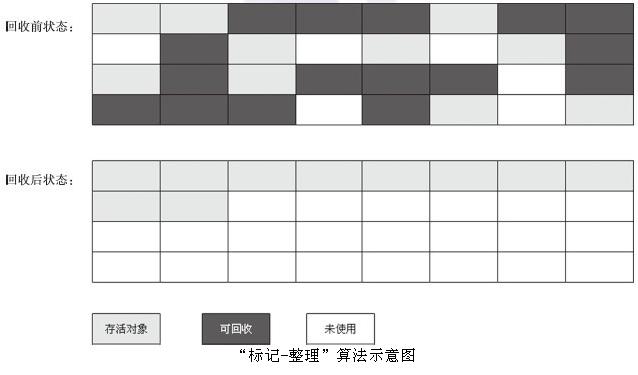
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象(如果对象在进行根搜索后发现没有与GC Roots相连接的引用链,对象将会被标记)。它是最基础的收集算法,因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
最大的特点是压缩好的数据和zip兼容,也就是说目前标准的zip uncompress算法都能解开,看起来比较适合web服务器的数据存储,降低成本,虽然只有3-8%点的提高,但是数据规模大了,还是很可观的。
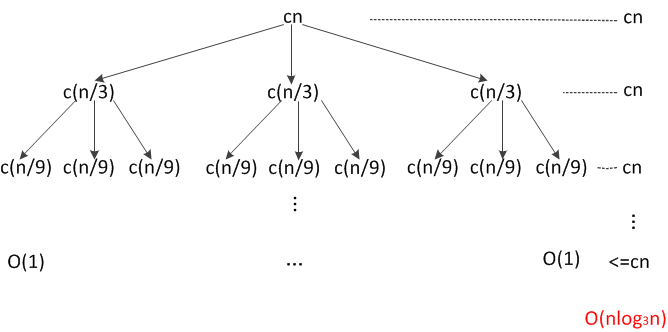
• 内存异常排查
一个层次分明的系统,在物理上就应该是相互隔离的,这种隔离,仅仅存在于人阅读的源代码层是绝对不够的。这就好比 OS 管理下的应用进程,它绝对不依赖应用进程的程序的工作正常,不依赖应用进程准确的申请和释放资源。而是当应用进程结束后,干净的回收它申请过的所有东西。

问题背景
成语是中华民族的文化瑰宝,作为历史的缩影、智慧的结晶、汉语言的精华,闪烁着睿智的光芒。
你的任务是给一个错误的四字成语进行纠错,找到它的正确写法。具体来说,你只允许修改四个汉字中的其中一个,使得修改后的成语在给定的成语列表中出现。原先的错误成语保证不在成语列表中出现。
• 房租分配问题
今天读到策划同学的周报中提到的一个关于合租房子的分摊房租问题。
引用周报中的一节如下:
上周在搬家,和喵、刘阳一起租房子住,遇到一个问题,就是分摊房租。中式的解决方法一般都是商量一下,但具体怎么商量,没有手段,总之就是大家估摸一下,觉得大略上说的过去就OK了。很少有拉下面子认真谈价格的,即使心里其实觉得并不认可。
在这方面,美国人还真能想一些办法,这是一个旅美的留学生在博客上写的,他和老美同学的商议方式:两个人A,B合租一个二居的房子,比如每个月是1500美元,因为主卧和次卧有大有小,价格肯定是不均的,那么两个人分别写两个价格,也就是对主卧和次卧的心理价格。可以很极端,比如1400:100,但总额必须是1500,因为这是A,B必须接受的大条件,然后公开,除掉开价完全相当的情况,两间卧室必然各有一个出价最高的人,价高者入住,而月租则是A,B对这个卧室开价的均值。例如A出价是900:600,B出价是1000:500,那么A住次卧,价格为550,B住主卧,价格为950。两个人都得到了自己认可的房子,而价格还低于自己的预期。
这一方案还有一个优势,就是双方都无法通过恶意的叫价来损害对方,获得利益。相信很多同学会提出一个更直接的解决方案:一个人提价格方案,另一个人选择。但是这一方案也有点问题,提价格的人相对是吃亏的,对吧?
遗憾的是,这种做法,似乎无法推广到三个人的情况。
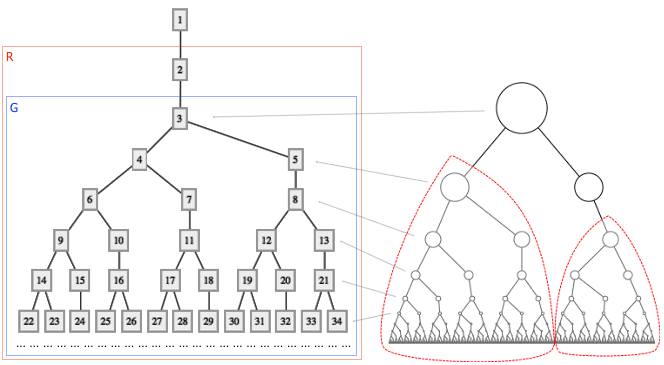
在著名奇书 Gödel, Escher, Bach: An Eternal Golden Braid 的第五章中,为了展现出递推序列的神奇之处,作者 Douglas Hofstadter 定义了这么一个递推序列: G(n) = n - G(G(n - 1)) ,其中 G(1) = 1 。这个数列通常被称作 Hofstadter G-sequence 。它有什么特别的地方呢?
bmp图片的格式我是了如指掌的,是不是ps以某种方式记录了它的更改操作呢?我比较了下ps前和ps后的图片的大小,结果发现ps后图片大小大了两个字节。用UltraEdit打开看了下十六进制的数据,发现原来是ps后的图片末尾被ps添加了两个字节的零。这两个字节的零不会对亮度和对比度起任何作用,那么到底什么改变了亮度和对比度呢?



题目:给定sina微博的全部用户(1亿以上)和标签(uniq的标签30万左右)的关系, 系统找出共有2个或以上标签的用户对,并给出这些标签是哪些。
近3天十大热文
-
 [582] 招聘技巧一二
[582] 招聘技巧一二 -
[16] 数据分析中常用的数据模型
-
[16] 豆瓣是啥?
-
[15] 30分钟3300%性能提升――python+
-
[15] 给自己的字体课(一)——英文字体基础
-
[15] 腾讯资深运维专家周小军:QQ与微信架构的惊天
-
[15] iOS 8/Android/WP 系统设置的
-
[14] jQuery性能优化指南
-
[13] 一次神奇的MySQL优化
-
[13] Android用户界面设计:表格布局
赞助商广告
