您现在的位置:首页 --> 查看专题: 大数据




今天,有个同学向我咨询大数据的一些面试题,其中一类比较有代表性比如判断是否在集合内,比如10个url,判断一个url是否在集合内,还比如有个1~100万个连续无序数字,随机取出里面的N个,求这N个数字等等。这类问题都需要一个大的数据集合,而且每个数据单元都很小,比如一个int 。很大程度上,这类问题可以用Bitmap或者Bloomfilter来做,基本思想就是开辟一块大内存,然后利用一个byte里的8个bit来实现按位标记元素。因为地址空间都是连续的,所以查找都是O(1)的。这里需要说的是,BloomFilter判断属不属于集合,在理论上是存在误判的,如果要求数据100%正确,则不要使用BloomFilter。
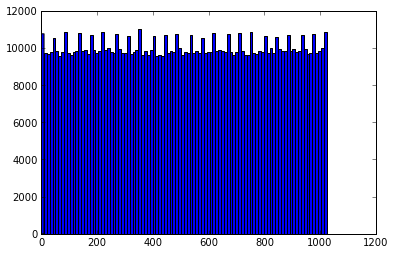
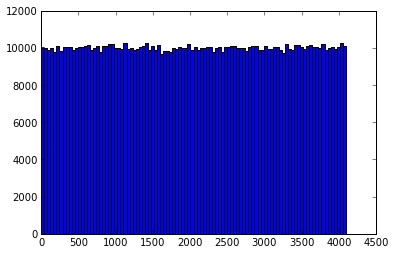
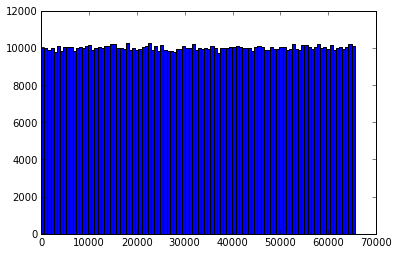
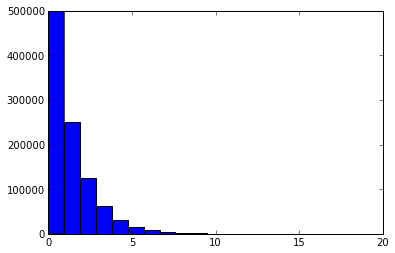
之前我曾写过一系列关于基数估计(cardinality estimation)算法的文章,文中介绍了一些常用基数估计算法的原理。最近对常用的基数估计算法做了一些实验,这篇文章描述了实验结果,包括这些算法的估计效果及误差状况,主要通过图表展示。通过观察实验数据和可视化图表可以加强对各种基数估计算法理论分析的直观理解。文章首先会对实验做一些说明,然后通过图表详细展示实验数据,最后会根据实验结果总结一些实践中有用的结论。同时文末会附上相关的参考文献及原始数据。
2013.6.23,工行发生重大系统故障,已经有一阵子了。今天想起写这个话题,完全是因为昨天看到了一条现在已经被和谐的微博,当时随手收藏却忘记了粉一下Po主,和谐之后已经死无对证,找不到“传谣”的人了,于是标题的最后形容某群体组织的四个字的专有名词变成了“工行”,不过也好,原来想的标题估计是跨不过深壑的。
数据化的另一大关键,就是如何与(移动)互联网与物联网有效融合。因为目前为止,移动互联网为我们提供了最好的,与用户粘在一起并充分挖掘用户数据的机会。无论是移动、社交还是本地化,都释放出了海量的数据,也就有着重大的挖掘空间。
究竟如何才能把数据转化为利润呢? 对大多数公司来说, 有两种选择, 一是数据导向的流程, 二是数据导向的产品。
如今,你到哪儿都能听到大数据。别说是亚马逊这样的公司,现在就是一个小的Startup, 每天也能有几个G的数据量。 而像Instagram 这样的照片分享网站,每天轻松就能产生出500T的数据量。 不少企业的CEO们都会问一个问题:“好,现在我有这么多数据,下一步我该怎么做呢?”
一直在特定领域的分布式系统一线摸爬滚打,曾取得一些微不足道的成绩,也犯过一些相当低级的错误。回头一看,每一个成绩和错误都是醉人的一课,让我在兴奋和懊恼的沉迷中成长。自己是个幸运儿,作为一个 freshman 就能够有机会承担许多 old guy 才能够有的职责。战战兢兢、如履薄冰的同时,在一线的实作和思考也让我获得了一些珍贵的经验,却直至今日才够胆量写出来一晒。这篇文章标题前面是“妄谈”两字,所持观点未必正确,我姑妄言之,有缘之人姑听之。若有些友好的讨论,亦我所愿也。 我做的虽然也是分布式系统,却不够胆去讨论通用分布式系统的设计原则。
[ 共6篇文章 ][ 第1页/共1页 ][ 1 ]
近3天十大热文
-
 [17] [译]Google Chrome中的高性能网
[17] [译]Google Chrome中的高性能网 -
[14] 最近总结的一些技巧(vim,python,s
-
[14] 在FreeNAS/BSD搭建基于Nginx+
-
[14] 关于Linux的文件系统cache
-
[13] Linux常用系统信息查看命令
-
[11] Linux(Ubuntu 10.04)上安装
-
[9] Centos yum 安装nginx+PHP
-
[8] base64_encode 和 urlenc
-
[8] PHP加速器 eaccelerator 缓存
-
[8] 浏览器缓存机制
赞助商广告
