您现在的位置:首页 --> 查看专题: 延迟

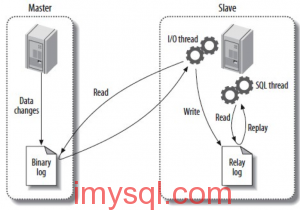




只读实例是目前RDS用户实现数据读写分离的一种常见架构,用户只需要将业务中的读请求分担到只读节点上,就可以缓解主库查询压力,同时也可以把一些OLAP的分析查询放到另外的只读节点上,减小复杂统计查询对主库的冲击。
由于RDS只读节点采用原生的MySQL Binlog复制技术,那么延迟必然会成为他成立之初就会存在的问题。延迟会导致只读节点与主库的数据出现不一致,进而可能造成业务上逻辑的混乱或者数据不正确;另外只读实例延迟同样也会触发binlog堆积,导致只读实例的空间迅速消耗完,这样会导致只读实例被锁定,锁定之后应用则无法完成读操作。
最近也收到了很多用户关于只读实例延迟的问题反馈,下面将会分析RDS只读实例出现延迟的几种常见场景,希望能够帮助用户理解和处理只读节点的延迟,更好地使用只读节点。
我们知道,计算机中有很多概念并不容易理解,有些时候一个好的比喻能胜过很多句解释。下面两个是我看到的两个很精彩的比喻,拿出来和大家分享一下:吞吐量和延迟、信号量和互斥锁。
我们在做网络服务器的时候,通常会很关心网络的带宽和延迟。因为我们的很多协议都是request-reponse协议,延迟决定了最大的QPS,而带宽决定了最大的负荷。 通常我们知道自己的网卡是什么型号,交换机什么型号,主机之间的物理距离是多少,理论上是知道带宽和延迟是多少的。但是现实的情况是,真正的带宽和延迟情况会有很多变数的,比如说网卡驱动,交换机跳数,丢包率,协议栈配置,光实际速度都很大的影响了数值的估算。 所以我们需要找到工具来实际测量下。
alarm函数是信号方式的延迟,这种方式不直观,这里不说了。 仅通过函数原型中时间参数类型,可以猜测sleep可以精确到秒级,usleep/select可以精确到微妙级,nanosleep和pselect可以精确到纳秒级。 而实际实现中,linux上的nanosleep和alarm相同,都是基于内核时钟机制实现,受linux内核时钟实现的影响,并不能达到纳秒级的精度,man nanosleep也可以看到这个说明,man里给出的精度是:Linux/i386上是10 ms ,Linux/Alpha上是1ms
我们在做网络服务器的时候,通常会很关心网络的带宽和延迟。因为我们的很多协议都是request-reponse协议,延迟决定了最大的QPS,而带宽决定了最大的负荷。 通常我们知道自己的网卡是什么型号,交换机什么型号,主机之间的物理距离是多少,理论上是知道是知道带宽和延迟是多少的。但是现实的情况是,真正的带宽和延迟情况会有很多变数的,比如说网卡驱动,交换机跳数,丢包率,协议栈配置,光实际速度都很大的影响了数值的估算。 所以我们需要找到工具来实际测量下。 网络测量的工具有很多,netperf什么的都很不错。 我这里推荐了qperf,这是RHEL 6发行版里面自带的,所以使用起来很方便,只要简单的: yum install qperf 就好。

Lazy Load是一个用Javascript写得jQuery插件。它可以使一个长网页中,不在当前视图中的图片延迟加载,以提高页面的载入速度。
[ 共9篇文章 ][ 第1页/共1页 ][ 1 ]
近3天十大热文
-
 [22] 招聘技巧一二
[22] 招聘技巧一二 -
[15] [译]Google Chrome中的高性能网
-
[14] 关于Linux的文件系统cache
-
[14] 在FreeNAS/BSD搭建基于Nginx+
-
[14] 最近总结的一些技巧(vim,python,s
-
[13] Linux常用系统信息查看命令
-
[11] Linux(Ubuntu 10.04)上安装
-
[9] 我对技术方向的一些反思
-
[9] Centos yum 安装nginx+PHP
-
[8] base64_encode 和 urlenc
赞助商广告
