您现在的位置:首页 --> 查看专题: IO

很多C/C++程序虽然在做网络编程, 但大多用别人封装好的库, 对底层不甚了解, 感觉 IO 操作不是很简单吗? 我敢说, 大多数人进行 IO 的姿势都不对, 所谓的 IO, 主要是 read()/write() 两个函数.



随着所有的在高可用服务器设计上的炒作,以及nodejs背后的风行,我想关注一些IO的设计模式,却一起没有足够的时间。现在正在完成的一些研究,我想最好记下这些资料以备查。让我们跳上IO bus兜风去。
前几天微博上有同学问我磁盘util达到了100%时程序性能下降的问题,由于信息实在有限,我也没有办法帮太大的忙,这篇blog只是想给他列一下在磁盘util很高的时候如何通过blktrace+debugfs找到发生IO的文件,然后再结合自己的应用程序,分析出这些IO到底是谁产生的,最终目的当然是尽量减少不必要的IO干扰,提高程序的性能。 blktrace是Jens Axobe写的一个跟踪IO请求的工具,Linux系统发起的IO请求都可以通过blktrace捕获并分析。
对于数据库来讲大多瓶颈都出现在IO问题上,所以现在SSD类的设备也才能大行其道。那数据库的IO这块有什么可以优化的吗? 我这里大致谈一下我的看法,希望能达到一个抛砖引玉的效果。
在上家公司曾写过这样一个服务,用户通过我的应用(以下简称fri_svr)索取自己的好友信息,而fri_svr需要向第三方平台(如:人人,Facebook)通过http协议批量请求用户数据,由于用户数据可能很大(几k几十k的级别),所以整个req/rep的过程通常会很慢,平均大概会在 1s - 10s 之间,这样当瞬时请求量到一定级别后,就会造成fri_svr的内存暴涨且响应不了前端的请求,原因在于fri_svr会对前端的每个请求hash到(根据user_id)专门用于http请求的线程队列中(也即是one thread per queue模型),当前端向fri_svr的请求速率大于平台响应fri_svr的,那么就会造成fri_svr中队列的积攒,内存的暴涨,且无法在超时时间内响应前端请求。
最近由于一些控制IO带宽的需求,开始研究CFQ以及对应的IO cgroup,今天baidu了一下,竟然发现没有多少中文的介绍,所以准备写一个系列,介绍一下这个调度器,粗粗想了一下,大概可以灌四篇水,包括CFQ的基本介绍,CFQ各个配置参数的含义和调优,CFQ的基本架构以及CFQ+cgroup。各位看官要是觉得还有什么值得写的,请留言给我或者直接新浪微博 @淘伯瑜。闲话少说,言归正传。 CFQ是Completely Fair Queuing的缩写,顾名思义,他存在的主要目的就是为了保证公平性, 并为此做了大量的工作。为了说明他的公平性,让我们先来简单看看另外目前kernel另外两个IO调度器,noop和deadline。那么怎么看自己目前硬盘的调度器呢?
作为一个Linux系统管理员,统计各类IO是一项必不可少的工作。其统计工具中iostat显然又是最重要的一个统计手段。但是这里iostat不是本文的重点,因为这个工具的使用在网络上已经有大量的教程,可以供大家参考。这里主要是想介绍一些其他统计工具以来满足不同的需求。

1.InnoDB存储引擎 AIO insert into nkeys values (71,71,71,71,71); Innodb的异步I/O,默认情况下使用linux原生aio,libaio。关于异步I/O的优势,可参考网文[18][19];libaio的限制,可见网文[17]。下面详细分析Innodb 异步I/O的处理步骤。




Linux异步I/O是Linux内核中提供的一个相当新的增强。它是2.6版本内核的一个标准特性,异步非阻塞I/O背后的基本思想是允许进程发起很多I/O操作,而不用阻塞或等待任何操作完成。稍后或在接收到I/O操作完成的通知时,进程就可以检索I/O操作的结果。


文件读写是日常编程中最经常使用的操作之一。这篇blog将大概介绍下Clojure里对文件操作的常用类库。 首先介绍标准库clojure.java.io,这是最经常用的IO库,定义了常见的IO操作。 首先,直接看一个例子,可以熟悉下大多数常用的函数:(nsio(:use[clojure.java.io]));;file函数,获取一个java.io.File对象(deff(file"a.txt"));;拷贝文件使用copy(copyf(file"b.txt"));;删除文件,使用delete-file(delete-filef);;更经常使用reader和writer(defrdr(reader"b.txt":encoding"utf-8"))(defwtr(writer"c.txt":appendtrue));;copy可以接受多种类型的参数(copyrdrwtr:buffer-size4
需要注意在应用中要避免漏建立了索引,这样会引起I/O大幅度的增加,导致不必要的磁盘扫描,如果有多块硬盘来存储Oracle的数据文件,尽量使用操作系统的条带化软件来分布Oracle的数据文件使得I/O分配均匀。此外,大量的磁盘排序会导致存在很多的脏缓存需要写完,因此,临时表空间中的数据文件最好能分配到不同的磁盘上,避免同一个磁盘上的I/O竞争。还有如果排序的BLOCK的检查点没有完成,将会存在于正常的缓存写批处理中,如果缓存...
目前web的应用大多都以I/O密集型为主,而存储技术的发展远没有计算机中其他系统发展迅速,尽管也不少高端存储设备,但是价格的昂贵,不是一般大众能享受的起的。而基于现状更多是我们使用一般SAS盘结合应用使用不同的RAID组合,来实现我们平民化存储,为了得到更好的性能,那么和I/O相关的调整优化是必不可少的。对于我们数据库调优来说,磁盘io优化是首屈一指的调优重点,我们都知道木桶原理,短板绝对整体的好坏,而数据库系统...
本文讲述了IO调用中的阻塞,非阻塞,同步,异步的概念和关系。是的读者可以很清楚的理解这几个概念。看了这篇文章,绝对可以很了解这几个IO调用的概念了。
网站的很多性能问题最终都会归结到IO头上,所以说理解iostat命令是非常有必要的。 小技巧:你知道iostat是从哪里得到IO相关信息的吗?使用strace命令能跟踪到答案...
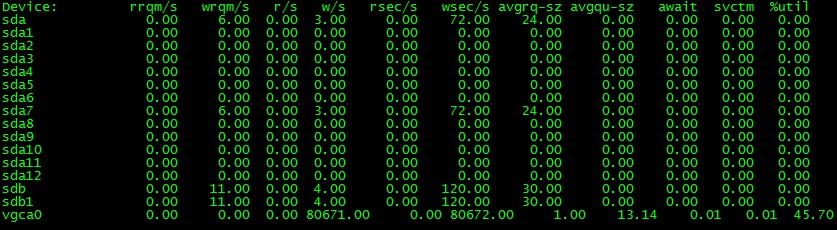
对以磁盘IO性能,一般有如下评判标准:正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
查看 CPU, Memory, I/O and NetFlow
随机IO几乎是令所有DBA谈虎色变的一个问题,这个问题,往往在数据量小的时候不出现,在数据量超过内存大小时,才陡然出现,令没有经验的DBA促不及防,也令有经验的DBA寝食难安。传统的数据库架构对随机IO几乎没有还手之力。传统数据库的核心通常是页级缓存、B+树、堆或索引组织表,这些机制,对随机IO的抵抗能力,都无一例外的可悲的差。页级缓存有很强的“连坐”效应,就是为了要缓存一条有价值的记录,顺带可能要同时缓存百条无...
[ 共31篇文章 ][ 第1页/共2页 ][ 1 ][ 2 ]
近3天十大热文
-
 [587] 招聘技巧一二
[587] 招聘技巧一二 -
[18] 密度聚类算法之OPTICS
-
[17] 豆瓣是啥?
-
[16] linux内核研究笔记(一)内存管理 – p
-
[16] 配合jquery实现异步加载页面元素
-
[15] 我的git笔记
-
[15] 在ssh服务里使用chroot
-
[14] 自建DNS以防止GFW干扰
-
[14] 可用性测试好助手——Morae软件的应用
-
[13] 使用document.domain和ifra
赞助商广告
