您现在的位置:首页 --> 查看专题: Innodb

MySQL 的 innodb 引擎之所以使用 B+tree 来存储索引,就是想尽量减少数据查询时磁盘 IO 次数。树的高度直接影响了查询的性能。一般树的高度在 3~4 层较为适宜。数据库分表的目的也是为了控制树的高度。那么如何获取树的高度呢?下面使用一个示例来说明如何获取树的高度。
对于数据库来讲大多瓶颈都出现在IO问题上,所以现在SSD类的设备也才能大行其道。那数据库的IO这块有什么可以优化的吗? 我这里大致谈一下我的看法,希望能达到一个抛砖引玉的效果。
这周阿里集团DBA内部分享时,支付宝的黄忠同学提了一个问题,关于InnoDB索引page 的利用率。 page利用率 主要是指btee里面每个page的使用被使用的空间大小。我们知道InnoDB默认一个page大小是16k。但实际使用情况不会总用满.
第六章、锁 锁是区别文件系统和数据库系统的一个关键特性。 6.1、什么是锁?
第四章、表 4.1、innodb存储引擎表类型 innodb表类似oracle的IOT表(索引聚集表-indexorganized table),在innodb表中每张表都会有一个主键,如果在创建表时没有显示的定义主键则innodb如按照如下方式选择或者创建主键。
第一章、mysql体系结构和存储引擎 1.1、数据库和实例的区别 数据库:物理操作系统或其他形式文件类型的集合。在mysql下数据库文件可以是frm,myd,myi,ibd结尾的文件。
本文从实际使用经验出发,介绍一款开源的MySQL数据库InnoDB数据恢复工具:innodb-tools,它通过从原始数据文件中提取表的行记录,实现从丢失的或者被毁坏的MySQL表中恢复数据。例如,当你不小心执行DROP TABLE、TRUNCATE TABLE或者DROP DATABASE之后,可以通过以下方式恢复数据。 以下内容大部分参考自:Percona Data Recovery Tool for InnoDB,文档是英文的,而且写的比较晦涩,这里是个人的实战经验总结,供大家参考学习。




最近在做MySQL的优化,看到现在MySQL分表分库后导致的内存利用率较低的问题,进行了优化,问题 当一个MySQL存不下全部的数据时,那么分库分表是一种常规的解决方案.但是一旦分库分表之后,关系型数据库对应的关系实际上被弱化了,很多查询不得不转换为类似K-V的查询.一般情况下为了使分库分表的数据尽量的平均都采用去模(mod)...
当innodb_buffer_pool_size大到几十GB或是百GB的时候,因为某些日常升级更新或是意外宕机,而必须要重新启动mysqld服务的之后,就面临一个问题,如何将之前频繁访问的数据重新加载回buffer中,也就是说,如何对innodb buffer pool进行预热,以便于快速恢复到之前的性能状态。如果是光靠Innodb本身去预热buffer,将会是一个不短的时间周期,业务高峰时,数据库将面临相当大的考验,I/O的瓶颈会带来糟糕的性能。那么,该怎么办呢?
之前没经历过漫长的crash recovery恢复过程,一是本身库中的数据量就不大,平时的业务量就不是很高,二是innodb_buffer_pool_size和innodb_log_file_size的大小平时设置的也不大。所以,对于意外导致innodb自动恢复时,经历的等待时间的长短没有什么深刻的体会。在浏览peter很早以前的文章时,看到当时大家是多么的无奈和痛苦,同时,在InnoDB没有对其作出改进之前,大家都在开动脑筋,配合各种参数尽可能的缩短故障恢复的时间。先...
数据的存储方式对应用程序的整体性能有着极大的影响。对数据的存取,是顺利读写还是随机读写?将数据放磁盘上还将数据放flash卡上?多线程读写对性能影响?面对着多种数据存储方式,我们如何选择?本文给大家提供了一份不同存储模式下的性能测试数据,方便大家在今后的程序开发过程中可以利用这份数据选择合适的数据存储模式。
InnoDB是支持MVCC多版本一致性读的,因此和其他实现了MVCC的系统如Oracle,PostgreSQL一样,读不会阻塞写,写也不会阻塞读。虽然同样是MVCC,各家的实现是不太一样的。

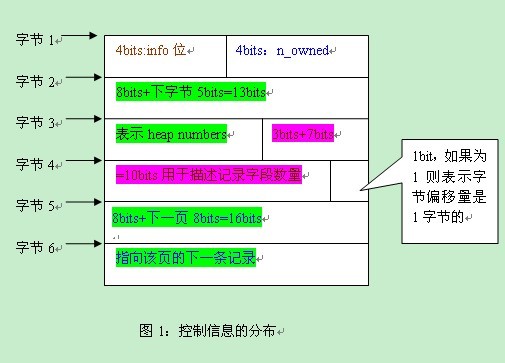
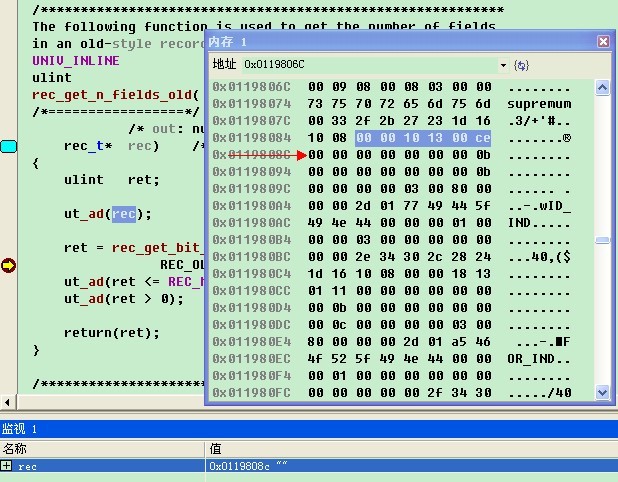
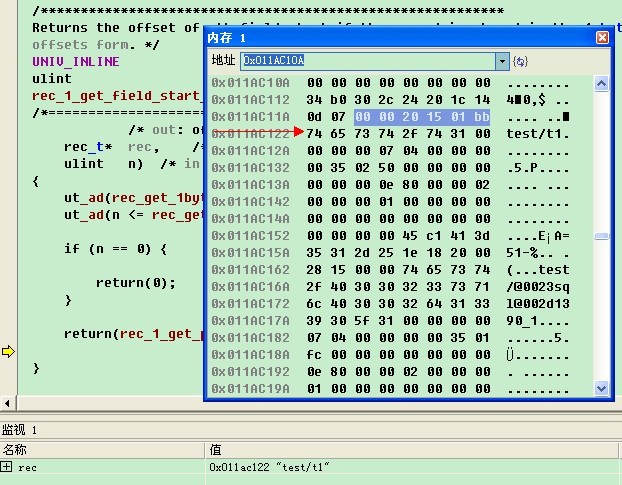
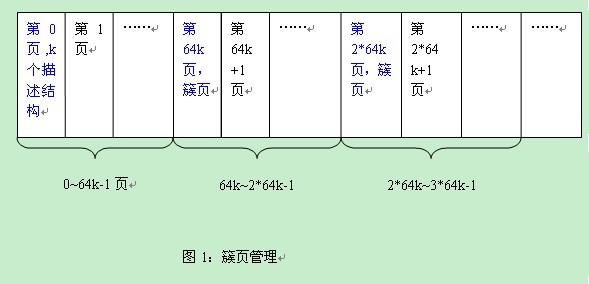
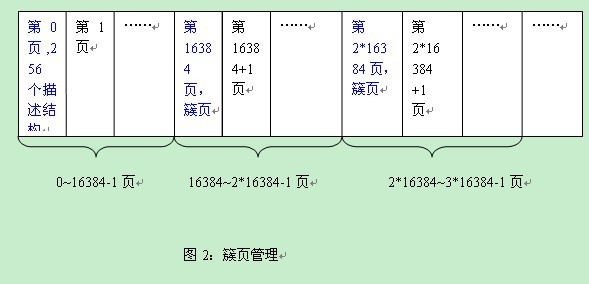
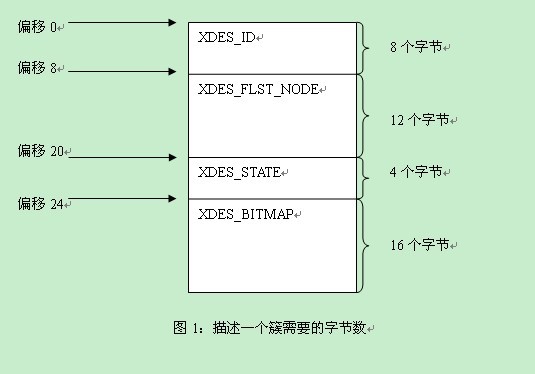
最近我分析了一下Innodb是如何写多个日志的。我这里有个流量比较高的MySQL系统,使用的是Percona XtraDB存储引擎,我使用strace命令分别跟踪了innodb如何去日志文件的。通常来说,innodb是以512bytes的大小来写入日志的。


众所周知,InnoDB是clustered-index table,因此对于InnoDB而言,主键具有特殊意义。可以通过主键直接定位到对应的某一数据行记录的物理位置,主键索引指向对应行记录,其他索引则都指向主键索引;因此,可以这么说,InnoDB其实就是一个 B-树索引,这棵B-树的索引就是主键,它的值则是对应的行记录。

近3天十大热文
-
 [584] 招聘技巧一二
[584] 招聘技巧一二 -
[16] 豆瓣是啥?
-
[16] 数据分析中常用的数据模型
-
[15] 给自己的字体课(一)——英文字体基础
-
[15] 30分钟3300%性能提升――python+
-
[14] 腾讯资深运维专家周小军:QQ与微信架构的惊天
-
[14] jQuery性能优化指南
-
[14] iOS 8/Android/WP 系统设置的
-
[13] 一次神奇的MySQL优化
-
[13] Android用户界面设计:表格布局
赞助商广告
