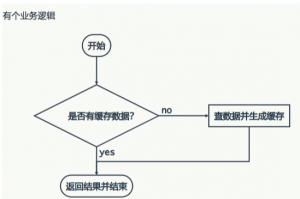
缓存穿透、缓存并发、缓存失效之思路变迁
作者从缓存实战中最常遇到的三类“坑”出发,分别剖析了问题的成因与演进式的解决思路。缓存穿透源于无效请求击穿缓存层直击数据库,作者提出了用特殊值预占位的拦截技巧。缓存并发则针对高并发下缓存瞬间失效带来的数据库压力,给出了加锁串行化的方案。缓存失效问题本质是缓存集体过期导致的雪崩,通过引入随机因子分散过期时间是关键。文章后半部分通过问答,进一步探讨了缓存与数据库的一致性等更深层的实践困惑,整体展现了从发现问题、分析根因到提出并优化方案的完整思考过程。
共 58 篇相关文章
作者从缓存实战中最常遇到的三类“坑”出发,分别剖析了问题的成因与演进式的解决思路。缓存穿透源于无效请求击穿缓存层直击数据库,作者提出了用特殊值预占位的拦截技巧。缓存并发则针对高并发下缓存瞬间失效带来的数据库压力,给出了加锁串行化的方案。缓存失效问题本质是缓存集体过期导致的雪崩,通过引入随机因子分散过期时间是关键。文章后半部分通过问答,进一步探讨了缓存与数据库的一致性等更深层的实践困惑,整体展现了从发现问题、分析根因到提出并优化方案的完整思考过程。
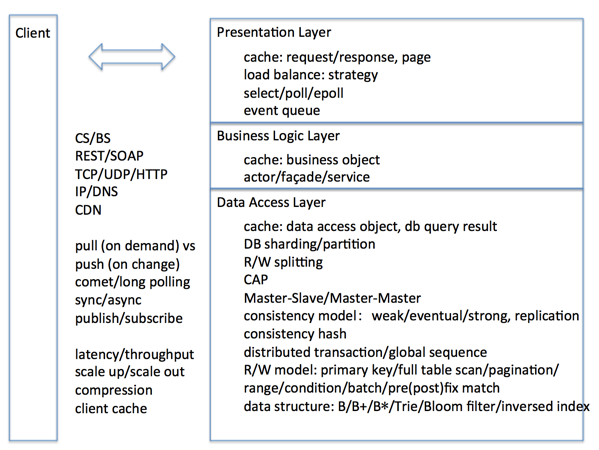
这篇讲的是系统设计面试中的典型套路。作者发现,许多看似复杂的设计问题,其实可以拆解为几个标准层次来思考。文章通过一张清晰的图表,梳理了从问题分析到具体技术点的完整框架。 核心将问题分为两大块:一类是“问题本身的分析”,涵盖同步/异步、消息推拉模式、数据结构设计等常见考察方向。另一类是“系统实现的分析”,又进一步细分为前端展示层、业务逻辑层,以及最复杂的数据访问层。每一层都对应着具体的挑战,比如缓存需要分层设计(冷热数据),数据库要考虑分片,而性能优化的核心始终围绕吞吐量与延迟展开。 特别值得注意的是,作者强调一致性模型是分布式系统的灵魂,读写模型则常与存储结构紧密结合。这篇文章的价值不在于给出一个标准答案,而是提供了一个结构化的思考工具,帮助你在面对任何系统设计问题时,都能快速定位关键层次,有条不紊地展开分析。
这篇讲的是作者从实际需求出发,设计高性能iOS缓存库YYCache的思考过程。他对比了NSCache、TMMemoryCache、PINMemoryCache等主流内存缓存实现,发现它们在性能或功能上各有不足,于是YYMemoryCache采用了OSSpinLock保证线程安全,并实现了LRU淘汰算法,在基准测试中性能表现突出。 针对磁盘缓存,文章分析了基于文件、mmap和SQLite三种技术路径的优劣。作者指出SQLite在存储小数据时性能更优,且便于实现元数据管理和淘汰策略,因此YYDiskCache采用了SQLite结合文件存储的混合方案,在实测中兼顾了性能与功能。 最后,作者还对比了Realm与SQLite的性能差异,并提到Realm会向外部IP发送数据,建议开发者谨慎使用。整篇文章从技术选型到性能评测,为iOS开发者选择和构建缓存方案提供了详实的参考。

这篇讲的是作者在阅读Redis源码时,特意“拾遗”的几个精妙的C语言编程技巧。作者从Redis简洁的1.0版本入手,并未重复大众熟知的源码剖析,而是聚焦于那些能让代码更健壮、更高效的小细节。 最典型的是“空数组”技巧:在`sdshdr`和`zskiplistNode`结构体的末尾定义一个空数组成员(如`char buf[]`和`level[]`)。这允许在动态内存分配时,根据实际需要的数据长度(如字符串长度、跳表层数)一次性申请合适大小的内存,实现了结构体内可变长数据的紧凑存储。 另一个常见但重要的技巧是使用 `do { } while(0)` 来包裹宏定义中的多条语句。这不仅能确保宏在if等控制流中像单条语句一样安全执行,文章还展示了将其用于简化流程控制的用法,使代码逻辑更清晰。 此外,文章还介绍了Redis中定制化的断言宏`redisAssert`和分级日志系统`redisLog`,前者在条件失败时能输出详尽的上下文信息,后者则允许根据日志级别进行过滤。这些实现虽小,却体现了生产级项目对可调试性和可观测性的重视。 这些从顶级项目中提炼出的技巧,对任何C/C++开发者都有直接的借鉴意义。
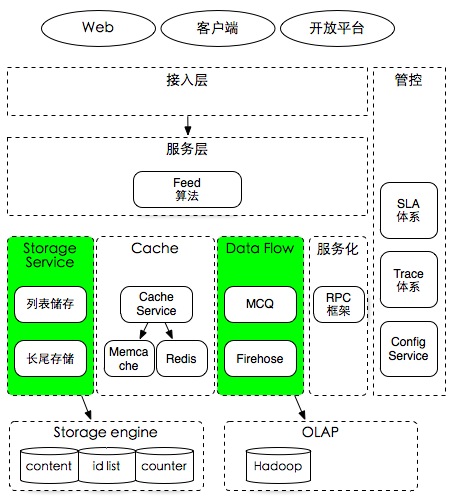
这篇讲的是微博技术团队在Feed架构演进中的一次坦诚复盘与反思。作者从团队过去几年成功解决的工程挑战切入——包括通过冷热分区设计应对长尾数据访问、利用数据库拆分实现存储扩展、依托缓存分级支撑百万级QPS,以及建设高可用的SLA体系。 但文章的重点不在这些成就,而是深入剖析了基于用户关系的分发架构在用户侧引发的“信息过载”问题。核心观点是:架构在解决了可扩展性与性能问题后,却造成了内容组织与消费效率上的新瓶颈。具体表现为:当前架构天然基于用户关系维度组织数据,这很难服务于更高效的“兴趣阅读”需求;同时,低质内容识别、实时反垃圾算法仍面临巨大技术挑战;此外,社交关系带来的“可解释性”要求(用户期望看到好友内容)也与纯粹的算法排序存在矛盾。 作者通过这次复盘,揭示了一个关键认知:Feed架构的难题已从纯粹的后端扩展性问题,转向了如何通过技术更好地理解与满足用户兴趣,同时平衡产品体验的复杂层面。这对于思考推荐系统与社交产品架构的未来方向,提供了很有价值的视角。
这篇讲的是Redis和Memcached这两种内存数据库的核心区别。文章从Redis作者的一个经典比较出发,清晰梳理了三者关键差异:首先,Redis支持String、Hash、List等更丰富的数据结构,可以在服务器端直接进行复杂操作,避免了Memcached需要将数据取回客户端修改的额外开销。其次,在内存效率上,若采用hash结构存储,Redis的组合压缩机制可能比Memcached更具优势。最后,性能表现各有特点:处理小数据时Redis的单核性能更优,而在100k以上的大数据场景中,Memcached的多核处理能力则略占上风。 文章随后深入剖析了Redis五种数据类型的实现原理,例如Hash内部如何根据成员数量自动转换存储结构,以及Set如何通过HashMap实现快速去重。这些细节不仅解释了差异背后的技术原因,也揭示了各自的设计考量。 总的来说,如果你的应用需要丰富的数据结构和复杂操作,Redis是更强大的选择;而如果是纯粹的、简单的大规模键值缓存,Memcached在内存利用和特定数据量级下的性能或许更合适。文章为技术选型提供了扎实的对比依据。
这篇讲的是微博崛起背后,一套被称作“纸牌屋”的关键人物合力。文章从新浪这家“无主”的互联网公司说起,剖析了在2009年管理层MBO前后,几股核心力量如何共同塑造了微博。 作者认为,微博的成功并非一张牌的力量,而是多张“牌”各司其职。内容大将陈彤奠定了“名人战略”的基石,复制了门户与博客的成功逻辑;销售核心杜红则将传统媒体的“大单”经营思维带入微博,高效地将流量转化为广告收入。执行者彭少彬力推项目并打通了用户标签系统,而技术出身的王高飞则敏锐抓住了移动浪潮,最终执掌产品技术,释放了“移动优先”的信号。 此外,曹国伟的资本运作与战略布局(如MBO、毒丸计划、商业化六大方向)为微博提供了关键支持和路线图。许良杰则带来底层技术与大公司管理经验,试图补强新浪的技术短板。文章指出,这套由内容、经营、执行、移动、资本与技术组成的“牌”,共同推动微博在竞争中胜出并走向上市,其合力也深刻影响了这家传统媒体基因公司的转型方向。
这篇讲的是如何快速清理 Chrome 浏览器的本地 DNS 缓存。作者从 DNS 缓存的工作原理切入,指出 Chrome 会通过预提取 DNS 记录来加速网站连接,并内置了一个便捷的查看地址:在地址栏输入 `about:DNS`,就能直接看到当前存储的本地缓存记录。 当遇到网站解析异常、访问某些站点时 IP 指向错误,或者进行本地开发调试需要即时生效新 DNS 记录时,一个有效的解决办法就是清除这个缓存。文章具体指出了操作路径:在地址栏输入 `chrome://net-internals/#dns`,进入网络内部信息面板后,点击页面上方的“Clean host cache”按钮即可完成清理。 整个方法非常直接,不需要借助任何第三方工具或重启浏览器。对于开发者、运维人员或者经常遇到网络连接小毛病的用户来说,这算是一个实用的系统级调试技巧,能快速排除因本地缓存导致的 DNS 问题。
这篇讲的是,作者在配置Nginx的fastcgi_cache模块时,明明参数都设对了,缓存却一直不生效、状态始终是MISS的诡异经历。通过strace工具抓包后,他发现是Discuz论坛程序默认返回的 `Cache-Control: no-cache` 响应头,直接导致Nginx放弃了缓存。 作者没有停留在表面,而是深入到Nginx源码层面,找到了关键的判断逻辑。他总结出:当fastcgi响应头中包含 `Set-Cookie`、`Expires` 时间过早或 `Cache-Control` 指向不缓存时,即使配置了cache,Nginx也会直接跳过。文章清晰地展示了从“配置无误却不生效”到“抓包定位干扰源”,再到“查阅源码验证规则”的完整排查链路。 对于实际运维或开发人员,这提醒我们:缓存是一个“端到端”的决策过程,上游应用的“不缓存”响应头拥有最高优先级。文末附带的Nginx配置示例和缓存状态头调试方法,也为快速定位类似问题提供了实用工具。
这篇讲的是Web性能优化中一个常被低估的选手:缓存。作者从“快速Web应用的关键是Ajax、优化JavaScript和更好的缓存”这一观点出发,做了一项有趣的实测,想看看这三招在实际网站里到底谁最管用。 他用WebPagetest工具模拟不同网络环境,对Alexa前1000网站进行了对比测试。结果有点出乎意料:缓存模式表现最强,页面加载中位数只需3.46秒,远快于“快速网络”(4.13秒)和“禁用JavaScript”(4.74秒)。核心原因在于,缓存直接将90个HTTP请求削减到仅32个,大部分资源从本地读取,彻底避免了网络传输。 文章进一步分析,当前很多网站虽配置了缓存,但有效期很短,导致优势局限于“重复浏览”。作者由此提出,未来的方向是延长缓存时间,并探索预读技术,让性能优势更持久。这提醒我们,在追求新技术的同时,扎实做好缓存这一“基本功”,往往能带来最显著的收益。
这篇讲的是如何用开源的APC扩展来保护PHP源代码,摆脱商业加密软件的束缚。 作者从实际痛点出发:像Zend Guard这类商业方案每年费用不菲(约4000元),且因每次访问都需解密验证,性能损耗巨大,曾导致服务器CPU负载飙升至100倍。相比之下,APC作为PHP官方的opcode缓存扩展,免费、开源且性能优越,能通过缓存编译后的中间代码来保护源码。 文章的核心价值在于,作者不满足于基础用法。他分享了将多个PHP文件编译为单个二进制opcode文件的实践,这比管理数百个零散文件更便捷,也避免了版本不一致的风险。更关键的是,他针对APC默认需要手动加载bin文件的繁琐流程,阅读源码并提交了一个补丁,实现了PHP-FPM启动时自动预加载,极大简化了运维。 作者还详细介绍了导出、部署、版本回滚的全流程,并附上了检测文件完整性的MD5校验方法。文中也坦诚地记录了在适配PHP 5.4等版本时遇到的APC本体Bug及解决方案,展现了从发现问题、提交BUG到推动社区修复的完整过程。 最终,这套方案让作者团队在免费、高性能的前提下,实现了对线上PHP代码的有效保护与高效管理,其贡献的补丁也为有类似需求的开发者提供了直接可用的工具。

文章从实际业务需求出发,对比了三种点击日志记录方案。第一种是通过URL参数传递信息,在服务器端(如Nginx)记录请求日志;第二种是通过中间服务器进行跳转并记录,数据最完整,Google、百度等搜索引擎均采用此方式,百度每天十亿级网页搜索请求用约50台服务器即可承载;第三种是前端JavaScript监控上报,能记录悬浮、滚动等丰富行为,但普遍存在15%-20%的数据丢失率。 文章重点剖析了JS方案丢数据的根本原因:前端无法为每个事件立即发送请求,必须将行为缓存后批量上报。如果用户在上报触发前关闭浏览器或发生崩溃,这部分缓存数据就会丢失。这本质上是用户体验流畅度与数据完备性之间的权衡——上报越频繁,体验越卡顿但数据越完整;反之则数据丢失风险增加。同时,高频上报也会给日志服务器带来巨大压力。对于追求数据完整性的核心场景,跳转记录是更可靠的选择;而JS方案更适合需要采集丰富交互行为、对少量丢失可容忍的分析场景。
这篇文章从实际应用出发,讨论了Redis的优势与局限,并对比了其他海量数据存储方案。作者指出,Redis的有序集合(zset)等丰富数据结构使其在表达业务逻辑时极为高效,特别适合对性能要求高、数据规模可控的场景,比如消息传递系统的收发件箱。 然而,Redis“所有数据必须存放在内存中”的核心设计,直接导致了容量瓶颈和高昂的硬件成本。作者通过计算说明,对于一个百万级用户系统,数据量轻松超过单机内存极限。由此还引发了一系列问题:持久化时fork进程占用双倍内存,Aof日志写盘可能阻塞系统,以及不成熟的主从复制可能因网络抖动产生全量同步,严重消耗带宽。单机架构也迫使开发者在业务逻辑之外,必须额外设计复杂的数据分片方案。 面对海量数据,文章对比了Cassandra、HBase和MongoDB等方案。作者认为纯键值存储(如Cassandra)对结构化数据的表达能力太弱;而像HBase这类系统,其数据模型提供了更有序的组织方式。文章最终提出的观点是:理想的存储方案应当提供基础的有序数据结构,允许开发者通过“实体”加“有序子集”的方式来自然映射业务逻辑,从而在海量数据规模下,实现高效的数据访问与传输。 因此,Redis应定位在小而美的高性能缓存或结构化存储层,而非追求海量数据的存储目标。
这篇讲的是三种代理服务器的区别:标准代理、透明代理与反向代理。 作者从它们的工作机制和应用场景出发,做了清晰的对比。标准代理需要用户主动配置浏览器,主要作用是缓存静态内容,为企业或局域网用户节省带宽。透明代理则对用户完全“透明”,无需配置,由网络设备(如路由器)在80端口直接截获HTTP流量进行缓存,这在ISP和简单局域网加速场景中很常见。 而反向代理的工作重点完全不同,它面向服务器端,被架设在Web服务器前端,主要目的是缓存服务器生成的动态或静态内容,直接响应大量请求,从而显著减轻后端服务器的负载压力,提升网站整体性能。 文章的亮点在于没有止步于理论对比。后半部分详细演示了如何使用Apache搭建一个反向代理服务器,以解决“如何用一台公网服务器(A)代理访问内网其他服务器(B、C)”的实际问题。内容涵盖了模块启用、VirtualHost配置等具体步骤,非常实用。 总的来说,这篇既讲清了三种代理的“是什么”和“为什么”,又通过实例说明了“怎么用”,对于理解网络架构和解决服务器部署问题都有参考价值。
这篇讲的是 Squid 缓存代理在处理源服务器响应时,一个可能被忽略但至关重要的细节——Vary 响应头,特别是针对内容协商场景。 文章从实际问题出发:当源服务器返回的响应中缺少了关键的 “Vary: Accept-Encoding” 头部时,会发生什么?作者深入剖析了这个问题,指出 Vary 头是 HTTP 缓存正确性的基石。它告诉缓存(如 Squid):“这个资源的不同变体是基于请求的哪个字段来区分的”。对于 `Accept-Encoding`,它意味着不同的压缩格式(如 gzip, br)对应不同的响应体。 如果缺失这个头,Squid 可能会错误地将一个压缩版本缓存,并直接提供给不支持压缩的客户端,导致乱码或渲染错误。文章清晰地梳理了从问题现象(如客户端接收到乱码)到根因(缓存了不匹配的变体)的完整逻辑链,并给出了具体的排查方向和配置建议,例如如何通过 `Vary` 头或 `Cache-Control` 来引导 Squid 的行为。 对于使用 Squid 或任何反向代理的开发者来说,这是一个典型的缓存陷阱。文章的价值在于将抽象的 HTTP 规范落地到具体的故障场景,提醒大家在架构涉及内容协商时,务必关注并正确设置 Vary 头,以确保缓存的准确性。
这篇直接回应了一个在技术社区中常见的疑问:MySQL 的 Query Cache(QC)使用的是“全局锁”还是“表锁”?作者没有停留在简单的二选一,而是深入到实现层面,厘清了 QC 的锁模型。 关键点在于,QC 的锁并非传统意义上的、针对整个查询或某张表的锁。它实际上是一个更细粒度的“锁段”(lock segment)机制。当一个查询被解析并需要访问 QC 时,它会根据查询语句的哈希值定位到特定的内存段,然后尝试获取该段上的锁。这意味着,只要两个查询的哈希值不同(即查询不同),它们就可以并发地读写 QC 中不同的内存段,互不干扰。 这解释了为什么在某些高并发场景下,QC 不会像全局锁那样成为瓶颈。但同时,哈希冲突(不同查询映射到同一段)或对同一内存段的竞争,依然会导致串行化等待。作者的剖析,帮助读者超越了“是或不是”的简单判断,去理解锁竞争的实质粒度,这对于分析具体业务下的 QC 性能瓶颈非常有指导意义。
这篇讲的是PHP加速器APC一个容易被忽略的实用功能:`apc_store`。大家通常只知道APC能缓存PHP字节码来提速,但作者将视角转向了它作为通用键值存储的应用。核心场景是:当项目的配置信息(尤其是那个可能无比庞大的多维数组)频繁被读取时,与其每次启动都解析文件,不如直接用`apc_store`将整个配置数组一次性缓存在共享内存里。这相当于给应用启动配置提供了一个极速通道,避免了重复的文件I/O和解析开销,让应用能更快地投入服务。文章聚焦于这个具体实践,点明了从“缓存代码”到“缓存数据”的思维延伸。
这篇讲的是Facebook如何用架构支撑起数十亿用户的巨量访问。作者从Facebook的技术文章和演讲视频中,梳理出其架构演进的核心思路,重点探讨了为应对极端流量和复杂业务场景,Facebook在分布式系统、数据存储、缓存与实时计算等方面采取的关键设计。比如他们如何通过Memcached和自研缓存系统解决海量数据读取,或是如何设计TAO这类社交图谱数据库来应对复杂关系查询。 文章没有陷入单一技术细节,而是将这些分散的实践串联起来,展示了一个庞大系统如何通过分层解耦、渐进式优化和对开源生态的深度参与来保持可扩展性。最后也提醒,Facebook的方案源于其特定规模与场景,直接套用风险很高,但其解决问题的思路和面对规模化挑战时的取舍,对任何构建高可用系统的团队都具有启发意义。
这篇讲的是Memcache协议的核心细节,作者从最基础的TCP协议切入,梳理了Memcache的连接建立、命令交互与响应处理的全过程。 文章详细解读了Memcache的文本和二进制两种协议格式。文本协议以明文命令和CR LF分隔,简单直观,方便调试;而二进制协议则采用结构化的帧格式,追求更高的解析效率与可靠性。对于关键的缓存操作,如GET、SET、DELETE等,文章解释了其报文结构,并特别指出了像CAS(Check And Set)这样的高级操作如何实现乐观锁,避免并发下的数据覆盖问题。同时,也探讨了Keep-Alive长连接复用在提升性能上的作用。 在对比中,文章阐明了Memcache主要基于TCP协议以提供可靠传输,但也支持UDP用于特定场景。TCP保证了命令和数据的准确送达,适用于核心业务;而UDP则能进一步降低延迟,适合对可靠性要求稍低但对速度敏感的场景。 通过对协议本身的拆解,这篇文章为深入理解Memcache的内部工作机制,以及在实际开发中进行高效、精准的客户端交互打下了坚实基础。
这篇讲的是2012年初,12306.cn购票网站因高并发访问陷入瘫痪,引发全网热议这一技术事件。作者没有停留在吐槽层面,而是选择从网站性能优化的专业视角切入,尝试梳理这类问题背后的技术逻辑。 文章并未提供一个“银弹”方案,而是坦诚地基于自身经验,围绕“性能”这一核心,粗略地探讨了系统在架构设计、资源扩展等方面可能面临的挑战与思考方向。作者明确表示,讨论聚焦于性能技术本身,而将UI、用户体验及部分功能设计暂时搁置。 从一次公开的系统故障出发,去反思其技术成因与应对之道,对于技术从业者而言,这不仅是对一个热点事件的记录,更是一次将公众关注转化为深度技术讨论的尝试。它提醒我们,面对海量用户的考验,性能问题永远是系统建设中必须直面的硬骨头。