{kind=link}
{kind=link}
{kind=link}
{kind=link}
国际站P4P系统总体概况
外贸直通车,即国际站P4P,是让阿里巴巴的ICBU会员企业(后面也会对免费的认证会员开放)更好的推广其产品的一种增值业务。在此业务系统中,卖家可以自主地选定要推广的产品和添加购买关键词,然后在买家用户搜索关键词或类目浏览时免费优先展示其产品信息并通过大量曝光来吸引潜在买家,并最终按照用户点击来付费。
在总体技术架构上,国际站P4P包含几个重要的子系统和模块.它们之间的交互关系如下图所示:

其中,每个子系统的主要功能为:
BP(Business Platform)
BP系统是重要的后台支撑系统。卖家(广告主)在此系统中开户、添加推广产品和购买关键词。此外它也会将用户操作产生的实时变更消息发送给引擎;同时会根据点击过滤系统生成的结算日志和校正日志进行结算和生成效果报告。
iMatch引擎
iMatch引擎是重要的广告offer的在线查询系统。它首先会从BP系统的数据库中dump 客户、offer、match等相关数据,然后build成iSearch索引,从而提供在线查询功能。此外,点击过滤系统会对加密的点击串进行解密、过滤,进而生产结算日志和校正日志供BP结算系统使用.最后,引擎生成的PV log会被DA系统用来关联点击等数据做各种数据报表分析.
算法模块和服务
算法主要负责扩展匹配、广告质量(mlr)以及预估点击转化率(ectr)等模型的训练和建立,并以库的方式提供给iMatch引擎使用。同时,算法也将归一化和预估排名等功能以服务的方式提供给BP系统使用。此外,点击过滤系统中的反作弊模型也是一个重要的算法模块。
SW(Search Web)
SW应用负责根据各个布点的要求请求iMatch引擎得到相应的广告offer并展示他们。同时,SW也负责处理广告offer和自然搜索结果的一些展示去重等逻辑。这块逻辑后面会在引擎规划的SP业务层来实现。
DA(Data Application)
DA系统主要负责收集各种log,包括PV log和点击日志,然后进行按小时和全天的数据分析得出各种报表数据供我们自己分析和用户查看。
iMatch引擎系统
简介
目前国际站P4P iMatch引擎是基于iSearch 4.2.1开发的一套分布式广告搜索引擎系统。在整体流程处理上,它接收从SW等外部发过来的查询请求,然后经过查询串解析和重写、广告offer查询、过滤、排序以及竞价扣费和记录PV日志等处理后将最终得到的广告offer返回给调用方。此外,它离线支持全量dump BP数据库中的用户、广告offer和match等广告实体数据建立全量索引。同时,它也实时的接收并处理BP系统的变更消息进而建立增量索引,从而使得用户的各种更改能够及时的在搜索结果中体现出来。
作为一个可扩展的分布式广告引擎系统,iMatch引擎主要包含如下的几个模块:

下面分别介绍上图中每个模块的主要功能和实现.
离线全量索引构建
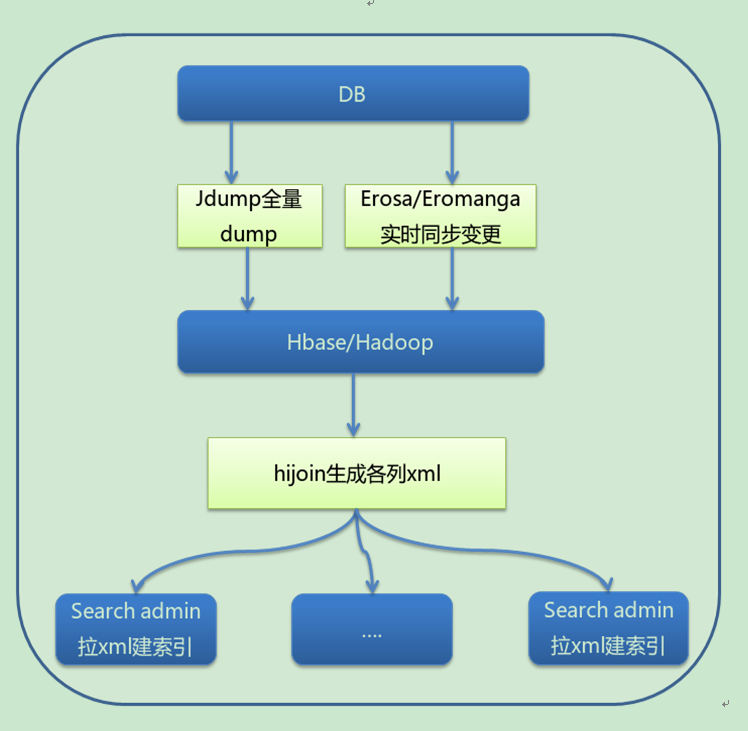
离线全量build索引是实现在线搜索查询的基础和前提,它线下批量分析每个offer、match和keyword等信息然后构建成isearch引擎的索引供在线查询使用。为了减少全量dump对数据库系统的压力以及缩小全量build时间,国际站P4P在Sourcing信息平台上面接入了dump中心基于HBase/Hadoop的离线分布式存储和计算系统。
新的dump系统首先会全量dump BP数据系统里面的数据,然后基于Erosa/Eromanga做到准时候的同步BP数据库中的各种增、删、改、查的变更操作,将修改操作写入到HBase中。这样在以后的每天全量时候就不用连接数据库进行offer和match等大表的全量dump了,从而大大减少了对数据库系统的依赖和缩短了全量时间。在内部,HBase会将一些数据库中的几个表合并成一张宽表,比如product表与广告offer表,从而可以减少在join时候的开销。
在全量的时候,相关数据会被从HBase表中取出来进行join操作,从而生成用于建索引的xml文件。这一步是典型的Map/Reduce批量计算。生成的xml文件的路径信息会被放到zookeeper中,然后iMatch引擎在每天全量的时候会根据zookeeper中路径信息到Hadoop上面将生成的xml拉取下来在iMatch引擎的各列search admin上面运行prebuild处理,然后运行ibuild生成全量索引。索引build好以后,再切换就可以在在线服务中使用了。
所以,整体上离线索引构建系统的处理流程图如下图所以:
实时增量索引构建
P4P的实时增量消息是直接对接BP的iNotify系统的。每条消息的处理流程如下图所示:
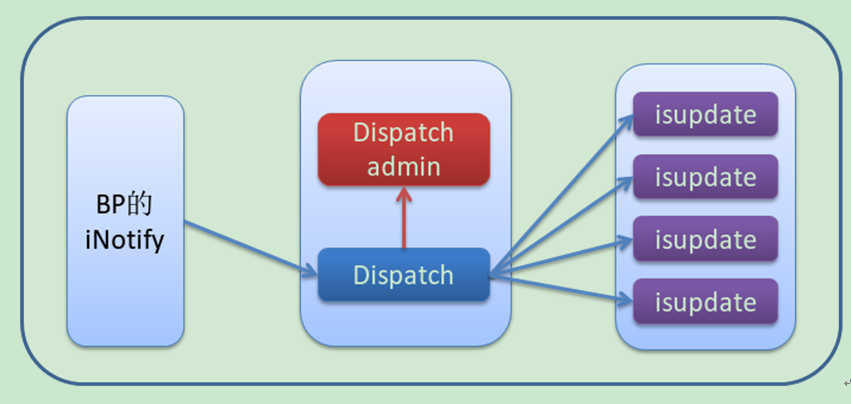
当用户在BP系统进行各种变更操作时,比如添加offer,添加购买词和修改购买词价格等操作,BP在修改数据库的同时会将这些变更以消息的形式实时发给引擎的dispatch服务。Dispatch在收到每一条消息后,先到disptch admin机器上面获取唯一的消息号,然后将此条消息存储在本地的同时将消息发给实时在线服务searcher机器上面的isupdate进程。Isupdate收到消息后会首先将其保存在本地磁盘中,然后处理消息对本地索引进行更新,最后这些变更会在新的索引查询中体现出来。
值得一提的是,当每天全量以后,isupdate会对在全量build阶段从iNotify收到的消息进行补偿处理。这时候由于前面isupdate收到的消息已经保存在了本地的文件系统中,不用再到dispatch上面去取了,所以处理起来会快很多。
在线查询系统
在线查询系统是iMatch引擎最重要的子系统,它负责对BP和SW等发过来的查询请求进行处理,然后将结果返回给调用发。此子系统是一个可扩展的分布式系统,它的整体架构如下图所示:
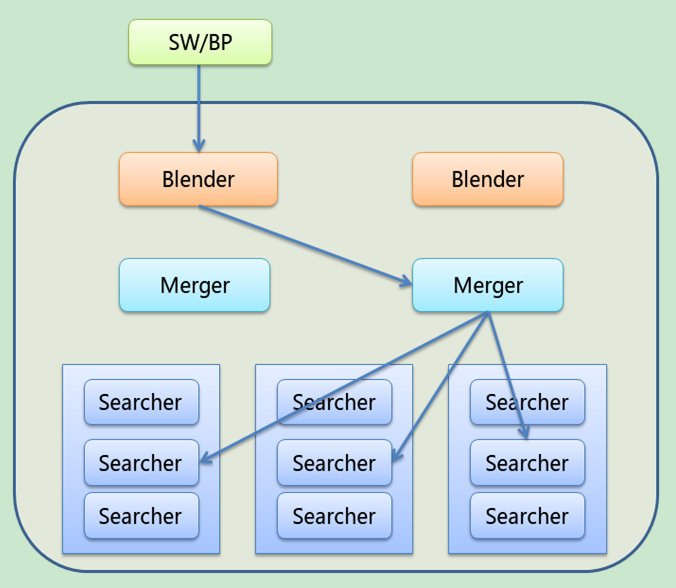
其中,各个角色的功能为:
Blender
Blender负责接收从外界,比如SW,发过来的查询请求,然后根据配置重写查询请求后转发给merger,并对从merger返回的结果做点击价格计算和PV日志生成等操作,然后将最终的广告结果集返回给请求方。 查询串改写(QRW)、点击价格计算和记录PV日志是重要的P4P业务模块。后面Blender层的一些业务处理逻辑会在统一的SP层实现。
Merger
Merger将从blender发过来的请求串根据load-balance的策略分发给各列中的一个searcher机器进行处理,然后接收从每列searcher返回的结果并汇总后继续对这些结果做CDistinct、P4PNormalSort和FieldFormatSort等sort模块的处理,最后再将得到的结果集返回给Blender。
Searcher
Searcher可以说最重要和最复杂的在线查询角色,真正的索引查询功能就是在这里完成的。流程上,Searcher在接到Merger的请求后会根据查询串中的查询字句对field或ackage索引进行查询,并对得到的结果集进行过滤和各种排序,最后将得到的结果集返回给Merger。
点击过滤系统
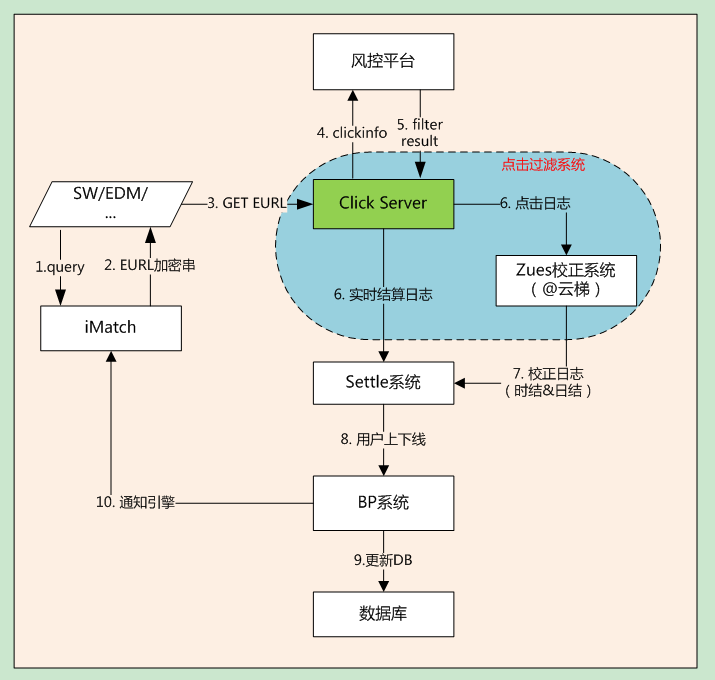
点击过滤系统也是iMatch引擎的一个重要模块。它的点击服务器会实时接收用户在点击搜索展示的广告标题或图片后发来的点击串,并对这些点击串首先进行相关规则过滤和反作弊处理,然后对有效点击生成点击日志和结算日志。这些结算日志会实时的发送给BP的结算系统。此外,点击过滤系统每小时会在云梯上对上述生成的点击日志进行离线反作弊校正计算,校正实时过滤的误差,生成校正日志发给BP结算系统进行结算校正。最后,BP系统会根据结算信息实时通知引擎进行一些客户的上下线处理。
下图显示的是一个点击加密串的生成和处理的整个流程:
结束语
以上就是对目前国际站P4P系统,特别是引擎系统架构的整体介绍. 未来,随着阿里巴巴ICBU信息平台和交易平台业务的不断发展, P4P引擎系统的架构也会不停的进行演化以便更好的支撑业务的成长.