标题是我瞎取的,非常感谢 @ytzong 同学在twitter上推荐这篇文章,原文在此。
本文系统的对HTTP Headers进行了简明易懂的阐述,我仅稍作笔记。
什么是HTTP Headers
HTTP是“Hypertext Transfer Protocol”的所写,整个万维网都在使用这种协议,几乎你在浏览器里看到的大部分内容都是通过http协议来传输的,比如这篇文章。
HTTP Headers是HTTP请求和相应的核心,它承载了关于客户端浏览器,请求页面,服务器等相关的信息。

示例
当你在浏览器地址栏里键入一个url,你的浏览器将会类似如下的http请求:
第一行被称为“Request Line” 它描述的是这个请求的基本信息,剩下的就是HTTP headers了。
请求完成之后,你的浏览器可能会收到如下的HTTP响应:
HTTP/1.x 200 OK
Transfer-Encoding: chunked
Date: Sat, 28 Nov 2009 04:36:25 GMT
Server: LiteSpeed
Connection: close
X-Powered-By: W3 Total Cache/0.8
Pragma: public
Expires: Sat, 28 Nov 2009 05:36:25 GMT
Etag: "pub1259380237;gz"
Cache-Control: max-age=3600, public
Content-Type: text/html; charset=UTF-8
Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT
X-Pingback: http://net.tutsplus.com/xmlrpc.php
Content-Encoding: gzip
Vary: Accept-Encoding, Cookie, User-Agent
第一行呢被称为“Status Line”,它之后就是http headers,空行完了就开始输出内容了(在这个案例中是一些html输出)。
但你查看页面源代码却不能看到HTTP headers,虽然它们同你能看到的东西一起被传送至浏览器了。
这个HTTP请求也发出了一些其它资源的接收请求,例如图片,css文件,js文件等等。
下面我们来看看细节。
怎样才能看到HTTP Headers
下面这些FireFox扩展能够帮助你分析HTTP headers:
1. firebug


3. 在PHP中:
getallheaders() 用来获取请求头部. 你也可以使用 $_SERVER 数组.headers_list() 用来获取响应头部.文章下面将会看到一些使用php示范的例子。
HTTP Request 的结构

被称作“first line”的第一行包含三个部分:
“method” 表明这是何种类型的请求. 最常见的请求类型有 GET, POST 和 HEAD.“path” 体现的是主机之后的路径. 例如,当你请求 “http://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/”时 , path 就会是 “/tutorials/other/top-20-mysql-best-practices/”.“protocol” 包含有 “HTTP” 和版本号, 现代浏览器都会使用1.1.剩下的部分每行都是一个“Name:Value”对。它们包含了各式各样关于请求和你浏览器的信息。例如”User-Agent“就表明了你浏览器版本和你所用的操作系统。”Accept-Encoding“会告诉服务器你的浏览可以接受类似gzip的压缩输出。
这些headers大部分都是可选的。HTTP 请求甚至可以被精简成这样子:
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1
Host: net.tutsplus.com
并且你仍旧可以从服务器收到有效的响应。
请求类型
三种最常见的请求类型是:GET,POST 和 HEAD ,从html的编写过程中你可能已经熟悉了前两种。
GET:获取一个文档
大部分被传输到浏览器的html,images,js,css, … 都是通过GET方法发出请求的。它是获取数据的主要方法。
例如,要获取Nettuts+ 的文章,http request的第一行通常看起来是这样的:
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1
一旦html加载完成,浏览器将会发送GET 请求去获取图片,就像下面这样:
GET /wp-content/themes/tuts_theme/images/header_bg_tall.png HTTP/1.1
表单也可以通过GET方法发送,下面是个例子:
当这个表单被提交时,HTTP request 就会像这样:
GET /foo.php?first_name=John&last_name=Doe&action=Submit HTTP/1.1
你可以将表单输入通过附加进查询字符串的方式发送至服务器。
POST:发送数据至服务器
尽管你可以通过GET方法将数据附加到url中传送给服务器,但在很多情况下使用POST发送数据给服务器更加合适。通过GET发送大量数据是不现实的,它有一定的局限性。
用POST请求来发送表单数据是普遍的做法。我们来吧上面的例子改造成使用POST方式:
提交这个表单会创建一个如下的HTTP 请求:
POST /foo.php HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: http://localhost/test.php
Content-Type: application/x-www-form-urlencoded
Content-Length: 43
first_name=John&last_name=Doe&action=Submit
这里有三个需要注意的地方:
第一行的路径已经变为简单的 /foo.php , 已经没了查询字符串。新增了 Content-Type 和 Content-Lenght 头部,它提供了发送信息的相关信息.所有数据都在headers之后,以查询字符串的形式被发送.POST方式的请求也可用在AJAX,应用程序,cURL … 之上。并且所有的文件上传表单都被要求使用POST方式。
HEAD:接收头部信息
HEAD和GET很相似,只不过HEAD不接受HTTP响应的内容部分。当你发送了一个HEAD请求,那就意味着你只对HTTP头部感兴趣,而不是文档本身。
这个方法可以让浏览器判断页面是否被修改过,从而控制缓存。也可判断所请求的文档是否存在。
例如,假如你的网站上有很多链接,那么你就可以简单的给他们分别发送HEAD请求来判断是否存在死链,这比使用GET要快很多。
http响应结构
当浏览器发送了HTTP请求之后,服务器就会通过一个HTTP response来响应这个请求。如果不关心内容,那么这个请求看起来会是这样的:

第一个有价值的信息就是协议。目前服务器都会使用 HTTP/1.x 或者 HTTP/1.1。
接下来一个简短的信息代表状态。代码200意味着我们的请求已经发送成功了,服务器将会返回给我们所请求的文档,在头部信息之后。
我们都见过“404”页面。当我向服务器请求一个不存在的路径时,服务器就用用404来代替200响应我们。
余下的响应内容和HTTP请求相似。这些内容是关于服务器软件的,页面/文件何时被修改过,mime type 等等…
同样,这些头部信息也是可选的。
HTTP状态码
200 用来表示请求成功.300 来表示重定向.400 用来表示请求出现问题.500 用来表示服务器出现问题.200 成功 (OK)
前文已经提到,200是用来表示请求成功的。
206 部分内容 (Partial Content)
如果一个应用只请求某范围之内的文件,那么就会返回206.
这通常被用来进行下载管理,断点续传或者文件分块下载。
404 没有找到 (Not Found)
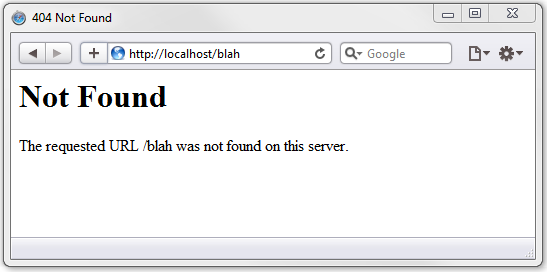
很容易理解
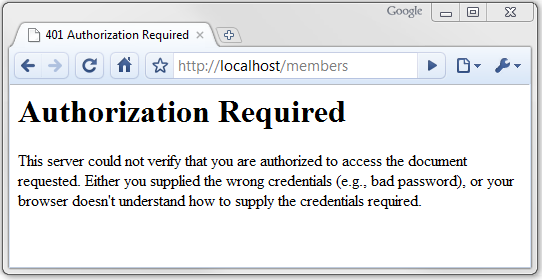
401 未经授权 (Unauthorized)
受密码保护的页面会返回这个状态。如果你没有输入正确的密码,那么你就会在浏览器中看到如下的信息:
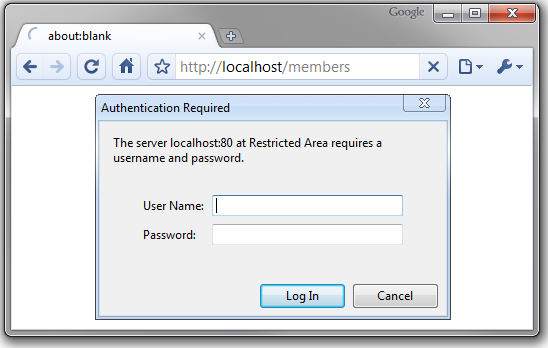
注意这只是受密码保护页面,请求输入密码的弹出框是下面这个样子的:
403 被禁止(Forbidden)
如果你没有权限访问某个页面,那么就会返回403状态。这种情况通常会发生在你试图打开一个没有index页面的文件夹。如果服务器设置不允许查看目录内容,那么你就会看到403错误。
其它一些一些方式也会发送权限限制,例如你可以通过IP地址进行阻止,这需要一些htaccess的协助。
order allow,deny
deny from 192.168.44.201
deny from 224.39.163.12
deny from 172.16.7.92
allow from all
302(或307)临时移动(Moved Temporarily) 和 301 永久移动(Moved Permanently)
这两个状态会出现在浏览器重定向时。例如,你使用了类似 bit.ly 的网址缩短服务。这也是它们如何获知谁点击了他们链接的方法。
302和301对于浏览器来说是非常相似的,但对于搜索引擎爬虫就有一些差别。打个比方,如果你的网站正在维护,那么你就会将客户端浏览器用302重定向到另外一个地址。搜索引擎爬虫就会在将来重新索引你的页面。但是如果你使用了301重定向,这就等于你告诉了搜索引擎爬虫:你的网站已经永久的移动到了新的地址。
500 服务器错误(Internal Server Error)
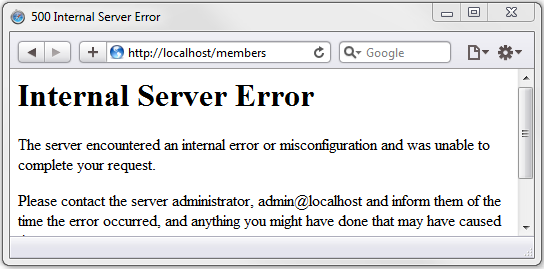
这个代码通常会在页面脚本崩溃时出现。大部分CGI脚本都不会像PHP那样输出错误信息给浏览器。如果出现了致命的错误,它们只会发送一个500的状态码。这时需要查看服务器错误日志来排错。
完整的列表
你可以在这里找到完整的HTTP 状态码说明。
HTTP Headers 中的 HTTP请求
现在我们来看一些在HTTP headers中常见的HTTP请求信息。
所有这些头部信息都可以在PHP的$_SERVER数组中找到。你也可以用getallheaders() 函数一次性获取所有的头部信息。
Host
一个HTTP请求会发送至一个特定的IP地址,但是大部分服务器都有在同一IP地址下托管多个网站的能力,那么服务器必须知道浏览器请求的是哪个域名下的资源。
Host: rlog.cn
这只是基本的主机名,包含域名和子级域名。
在PHP中,可以通过$_SERVER[\'HTTP_HOST\'] 或 $_SERVER[\'SERVER_NAME\']来查看。
User-Agent
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)
这个头部可以携带如下几条信息:
浏览器名和版本号.操作系统名和版本号.默认语言.这就是某些网站用来收集访客信息的一般手段。例如,你可以判断访客是否在使用手机访问你的网站,然后决定是否将他们引导至一个在低分辨率下表现良好的移动网站。
在PHP中,可以通过 $_SERVER[\'HTTP_USER_AGENT\'] 来获取User-Agent
if ( strstr($_SERVER[\'HTTP_USER_AGENT\'],’MSIE 6′) ) {
echo “Please stop using IE6!”;
}
Accept-Language
Accept-Language: en-us,en;q=0.5
这个信息可以说明用户的默认语言设置。如果网站有不同的语言版本,那么就可以通过这个信息来重定向用户的浏览器。
它可以通过逗号分割来携带多国语言。第一个会是首选的语言,其它语言会携带一个“q”值,来表示用户对该语言的喜好程度(0~1)。
在PHP中用 $_SERVER["HTTP_ACCEPT_LANGUAGE"] 来获取这一信息。
if (substr($_SERVER[\'HTTP_ACCEPT_LANGUAGE\'], 0, 2) == ‘fr’) {
header(’Location: http://french.mydomain.com’);
}
Accept-Encoding
Accept-Encoding: gzip,deflate
大部分的现代浏览器都支持gzip压缩,并会把这一信息报告给服务器。这时服务器就会压缩过的HTML发送给浏览器。这可以减少近80%的文件大小,以节省下载时间和带宽。
在PHP中可以使用 $_SERVER["HTTP_ACCEPT_ENCODING"] 获取该信息。 然后调用ob_gzhandler()方法时会自动检测该值,所以你无需手动检测。
// enables output buffering
// and all output is compressed if the browser supports it
ob_start(’ob_gzhandler’);
If-Modified-Since
如果一个页面已经在你的浏览器中被缓存,那么你下次浏览时浏览器将会检测文档是否被修改过,那么它就会发送这样的头部:
If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT
如果自从这个时间以来未被修改过,那么服务器将会返回“304 Not Modified”,而且不会再返回内容。浏览器将自动去缓存中读取内容。
在PHP中,可以用$_SERVER[\'HTTP_IF_MODIFIED_SINCE\'] 来检测。
// assume $last_modify_time was the last the output was updated
// did the browser send If-Modified-Since header?
if(isset($_SERVER[\'HTTP_IF_MODIFIED_SINCE\'])) {
// if the browser cache matches the modify time
if ($last_modify_time == strtotime($_SERVER[\'HTTP_IF_MODIFIED_SINCE\'])) {
// send a 304 header, and no content
header(”HTTP/1.1 304 Not Modified”);
exit;
}
}
还有一个叫Etag的HTTP头信息,它被用来确定缓存的信息是否正确,稍后我们将会解释它。
Cookie
顾名思义,他会发送你浏览器中存储的Cookie信息给服务器。
Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120; foo=bar
它是用分号分割的一组名值对。Cookie也可以包含session id。
在PHP中,单一的Cookie可以访问$_COOKIE数组获得。你可以直接用$_SESSION array获取session变量。如果你需要session id,那么你可以使用session_id()函数代替cookie。
echo $_COOKIE[\'foo\'];
// output: bar
echo $_COOKIE[\'PHPSESSID\'];
// output: r2t5uvjq435r4q7ib3vtdjq120
session_start();
echo session_id();
// output: r2t5uvjq435r4q7ib3vtdjq120
Referer
顾名思义, 头部将会包含referring url信息。
例如,我访问Nettuts+的主页并点击了一个链接,这个头部信息将会发送到浏览器:
Referer: http://net.tutsplus.com/
在PHP中,可以通过 $_SERVER[\'HTTP_REFERER\'] 获取该值。
if (isset($_SERVER[\'HTTP_REFERER\'])) {
$url_info = parse_url($_SERVER[\'HTTP_REFERER\']);
// is the surfer coming from Google?
if ($url_info[\'host\'] == ‘www.google.com’) {
parse_str($url_info[\'query\'], $vars);
echo “You searched on Google for this keyword: “. $vars[\'q\'];
}
}
// if the referring url was:
// http://www.google.com/search?source=ig&hl=en&rlz=&=&q=http+headers&aq=f&oq=&aqi=g-p1g9
// the output will be:
// You searched on Google for this keyword: http headers
You may have noticed the word “referrer” is misspelled as “referer”. Unfortunately it made into the official HTTP specifications like that and got stuck.
Authorization
当一个页面需要授权,浏览器就会弹出一个登陆窗口,输入正确的帐号后,浏览器会发送一个HTTP请求,但此时会包含这样一个头部:
Authorization: Basic bXl1c2VyOm15cGFzcw==
包含在头部的这部分信息是base64 encoded。例如,base64_decode(’bXl1c2VyOm15cGFzcw==’) 会被转化为 ‘myuser:mypass’ 。
在PHP中,这个值可以用$_SERVER[\'PHP_AUTH_USER\'] 和 $_SERVER[\'PHP_AUTH_PW\'] 获得。
更多细节我们会在WWW-Authenticate部分讲解。
HTTP Headers 中的 HTTP响应
现在让我了解一些常见的HTTP Headers中的HTTP响应信息。
在PHP中,你可以通过 header() 来设置头部响应信息。PHP已经自动发送了一些必要的头部信息,如 载入的内容,设置 cookies 等等… 你可以通过 headers_list() 函数看到已发送和将要发送的头部信息
 。你也可以使用headers_sent()函数来检查头部信息是否已经被发送。
。你也可以使用headers_sent()函数来检查头部信息是否已经被发送。
Cache-Control
w3.org 的定义是:“The Cache-Control general-header field is used to specify directives which MUST be obeyed by all caching mechanisms along the request/response chain.” 其中“caching mechanisms” 包含一些你ISP可能会用到的 网关和代理信息。
例如:
Cache-Control: max-age=3600, public
“public”意味着这个响应可以被任何人缓存,“max-age” 则表明了该缓存有效的秒数。允许你的网站被缓存降大大减少下载时间和带宽,同时也提高的浏览器的载入速度。
也可以通过设置 “no-cache” 指令来禁止缓存:
Cache-Control: no-cache
更多详情请参见w3.org。
Content-Type
这个头部包含了文档的”mime-type”。浏览器将会依据该参数决定如何对文档进行解析。例如,一个html页面(或者有html输出的php页面)将会返回这样的东西:
Content-Type: text/html; charset=UTF-8
‘text’ 是文档类型,‘html’则是文档子类型。 这个头部还包括了更多信息,例如 charset。
如果是一个图片,将会发送这样的响应:
Content-Type: image/gif
浏览器可以通过mime-type来决定使用外部程序还是自身扩展来打开该文档。如下的例子降调用Adobe Reader:
Content-Type: application/pdf
直接载入,Apache通常会自动判断文档的mime-type并且添加合适的信息到头部去。并且大部分浏览器都有一定程度的容错,在头部未提供或者错误提供该信息的情况下它会去自动检测mime-type。
你可以在这里找到一个常用mime-type列表。
在PHP中你可以通过 finfo_file() 来检测文件的ime-type。
Content-Disposition
这个头部信息将告诉浏览器打开一个文件下载窗口,而不是试图解析该响应的内容。例如:
Content-Disposition: attachment; filename=“download.zip”
他会导致浏览器出现这样的对话框:
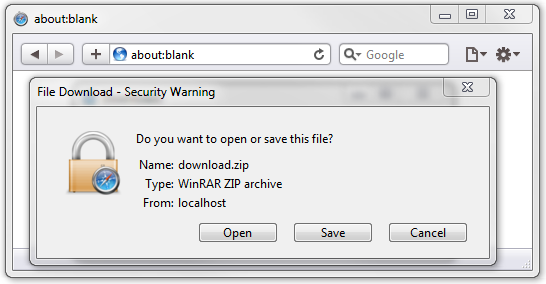
注意,适合它的Content-Type头信息同时也会被发送
Content-Type: application/zip
Content-Disposition: attachment; filename=“download.zip”
Content-Length
当内容将要被传输到浏览器时,服务器可以通过该头部告知浏览器将要传送文件的大小(bytes)。
Content-Length: 89123
对于文件下载来说这个信息相当的有用。这就是为什么浏览器知道下载进度的原因。
例如,这里我写了一段虚拟脚本,来模拟一个慢速下载。
// it’s a zip file
header(’Content-Type: application/zip’);
// 1 million bytes (about 1megabyte)
header(’Content-Length: 1000000′);
// load a download dialogue, and save it as download.zip
header(’Content-Disposition: attachment; filename=”download.zip”‘);
// 1000 times 1000 bytes of data
for ($i = 0; $i < 1000; $i++) {
echo str_repeat(”.”,1000);
// sleep to slow down the download
usleep(50000);
}
结果将会是这样的:
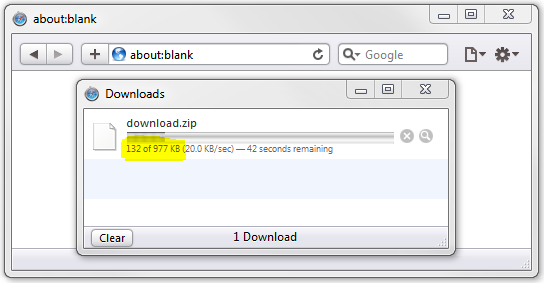
现在,我将Content-Length头部注释掉:
// it’s a zip file
header(’Content-Type: application/zip’);
// the browser won’t know the size
// header(’Content-Length: 1000000′);
// load a download dialogue, and save it as download.zip
header(’Content-Disposition: attachment; filename=”download.zip”‘);
// 1000 times 1000 bytes of data
for ($i = 0; $i < 1000; $i++) {
echo str_repeat(”.”,1000);
// sleep to slow down the download
usleep(50000);
}
结果就变成了这样:
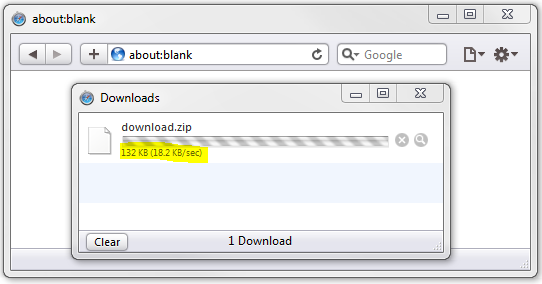
这个浏览器只会告诉你已下载了多少,但不会告诉你总共需要下载多少。而且进度条也不会显示进度。
Etag
这是另一个为缓存而产生的头部信息。它看起来会是这样:
Etag: ”pub1259380237;gz”
服务器可能会将该信息和每个被发送文件一起响应给浏览器。该值可以包含文档的最后修改日期,文件大小或者文件校验和。浏览会把它和所接收到的文档一起缓存。下一次当浏览器再次请求同一文件时将会发送如下的HTTP请求:
If-None-Match: ”pub1259380237;gz”
如果所请求的文档Etag值和它一致,服务器将会发送304状态码,而不是2oo。并且不返回内容。浏览器此时就会从缓存加载该文件。
Last-Modified
顾名思义,这个头部信息用GMT格式表明了文档的最后修改时间:
Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT
$modify_time = filemtime($file);
header(”Last-Modified: ” . gmdate(”D, d M Y H:i:s”, $modify_time) . ” GMT”);
它提供了另一种缓存机制。浏览器可能会发送这样的请求:
If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT
在If-Modified-Since一节我们已经讨论过了。
Location
这个头部是用来重定向的。如果响应代码为 301 或者 302 ,服务器就必须发送该头部。例如,当你访问 http://www.nettuts.com 时浏览器就会收到如下的响应:
HTTP/1.x 301 Moved Permanently
…
Location: http://net.tutsplus.com/
…
在PHP中你可以通过这种方式对访客重定向:
header(‘Location: http://net.tutsplus.com/’);
默认会发送302状态码,如果你想发送301,就这样写:
header(‘Location: http://net.tutsplus.com/’, true, 301);
Set-Cookie
当一个网站需要设置或者更新你浏览的cookie信息时,它就会使用这样的头部:
Set-Cookie: skin=noskin; path=/; domain=.amazon.com; expires=Sun, 29-Nov-2009 21:42:28 GMT
Set-Cookie: session-id=120-7333518-8165026; path=/; domain=.amazon.com; expires=Sat Feb 27 08:00:00 2010 GMT
每个cookie会作为单独的一条头部信息。注意,通过js设置cookie将不会体现在HTTP头中。
在PHP中,你可以通过setcookie()函数来设置cookie,PHP会发送合适的HTTP 头。
setcookie(”TestCookie”, “foobar”);
它会发送这样的头信息:
Set-Cookie: TestCookie=foobar
如果未指定到期时间,cookie就会在浏览器关闭后被删除。
WWW-Authenticate
一个网站可能会通过HTTP发送这个头部信息来验证用户。当浏览器看到头部有这个响应时就会打开一个弹出窗。
WWW-Authenticate: Basic realm=“Restricted Area”
它会看起来像这样:
http://nettuts.s3.amazonaws.com/511_http/401_prompt.png
在PHP手册的一章中就有一段简单的代码演示了如果用PHP做这样的事情:
if (!isset($_SERVER[\'PHP_AUTH_USER\'])) {
header(’WWW-Authenticate: Basic realm=”My Realm”‘);
header(’HTTP/1.0 401 Unauthorized’);
echo ‘Text to send if user hits Cancel button’;
exit;
} else {
echo “
Hello {$_SERVER[\'PHP_AUTH_USER\']}.
”;echo “
You entered {$_SERVER[\'PHP_AUTH_PW\']} as your password.
”;}
Content-Encoding
这个头部通常会在返回内容被压缩时设置。
Content-Encoding: gzip
在PHP中,如果你调用了ob_gzhandler()函数,这个头部将会自动被设置。