SmartPerfetto 已经完整开源。打开仓库能看到当前可运行的主干工程:Perfetto UI fork、后端 agentv3、MCP 工具、YAML Skill、场景策略、脚本和文档。没有保留私有核心模块,也没有只放一层 demo 壳。
这个项目来自一个很具体的日常场景:手里有一条 trace,Perfetto 已经把事实摆出来,但从事实到判断还要翻表、写 SQL、对线程、看 FrameTimeline、找 Binder 对端,再回到时间线上确认一遍。SmartPerfetto 想把这些重复动作固化成工具,让性能工程师把时间花在判断上。
它还处在开发阶段。现在放出来,是因为 trace 分析靠真实样本长出来:真实设备、真实厂商差异、真实业务 trace、真实 PR,都会改变 Skill 和策略该怎么写。等所有能力都稳定后再单向发布,反而会错过最需要样本的阶段。
如果你日常会打开 Perfetto 看滑动卡顿、启动、ANR、Binder、CPU 调度或渲染管线,SmartPerfetto 提供的是一个带 AI Assistant 的 Perfetto UI:加载 trace 后,用自然语言提问,后端查询 trace_processor_shell、调用 YAML Skill、组织证据,再把结论和数据表格流式显示在浏览器里。
项目地址:
- 主仓库:https://github.com/Gracker/SmartPerfetto
- Perfetto UI fork:https://github.com/Gracker/perfetto
普通试用只需要看主仓库。Gracker/perfetto 是 perfetto/ submodule 对应的前端 fork,主要给需要改 AI Assistant 插件 UI 的开发者使用。
前两篇技术文档更适合想看工程细节的读者:
- 从 Trace 到洞察:SmartPerfetto AI Agent 的 Harness Engineering 实战:SmartPerfetto AI Agent 的架构和 Harness Engineering 过程。
- SmartPerfetto 架构文章 Q&A:8 个深度技术问答:围绕 Agent、Workflow、YAML Skill 的问答。
前两篇把内部架构讲得比较细,但源码放出来以后,读者更关心的是仓库里到底有什么、能不能跑、哪些地方还没稳。这篇主要补开源这件事:开放了什么、当前能做什么、内部怎么分工、怎样在本地跑起来、哪些地方适合一起改。
开源的是什么
SmartPerfetto 开源的是从 UI 到分析规则的一整套工程。它保留 Perfetto 的时间线、SQL 和 trace 可视化能力,在 UI 里增加一个 AI Assistant 面板,再由 TypeScript 后端负责 Agent 编排、MCP 工具调用、Skill 执行、报告生成和 SSE 流式输出。
仓库里包含这些部分:

- Perfetto UI 插件和预构建前端:
perfetto/submodule 里集成com.smartperfetto.AIAssistant,仓库同时提交frontend/预构建产物,日常试用不需要重新编译 Perfetto UI。 - 后端 Agent 运行时:
backend/src/agentv3/下的场景路由、Prompt 构建、MCP Server、Verifier、Artifact Store、SSE Bridge。 - YAML Skill 系统:
backend/skills/下当前有 165 个*.skill.yaml,覆盖滑动、启动、ANR、内存、CPU、GPU、Binder、渲染管线等方向。 - 场景策略:
backend/strategies/下有 12 个.strategy.md,用于给不同问题注入不同分析步骤和输出约束。 - 工程脚本和文档:Docker Hub Compose、源码构建 Compose、
start.sh、前端插件开发脚本、MCP 工具参考、Skill 指南、技术架构文档、渲染管线参考文档。
这次开放的是全部工程。如果某个能力目前还不够好,那就是开发阶段的真实状态。仓库外没有另一套私有核心实现。UI、后端运行时和 Skill 系统已经可用,公开 API 和内部协议还会继续调整。
为什么现在开源
Perfetto trace 分析很依赖样本。不同 Android 版本、不同厂商、不同渲染框架、不同业务场景,会让同一类卡顿呈现出不同数据形态。一个人或一个团队很难覆盖这些分支。
SmartPerfetto 在开发里反复遇到的情况是:SQL 能查到事实,但事实不会自动变成结论。很多分析错误看起来像模型“不够聪明”,实际原因常常是 Skill 少了一条分支、某张表没覆盖、trace 样本太少、策略里默认了某种设备行为。
现在开源,是希望先把三类东西放出来,让它们接受真实 trace 的考验:
- 可运行的工具:让读者能在本地加载自己的 trace,验证 AI Assistant 对真实数据的处理方式。
- 可审查的规则:YAML Skill、场景策略和 MCP 工具都放在仓库里,结论背后的 SQL 和策略可以被检查、修改和复用。
- 可积累的样本:复杂性能问题需要 trace 样本和回归测试长期积累,开源仓库更适合长期保存这些案例。
对 Android 性能工程师来说,一条能复现问题的 trace、一个更准的 Perfetto SQL、一个更可靠的 Skill 分支,或者一次指出错误归因的 review,常常比大段功能代码更有用。
开发阶段开源的意义也在这里:SmartPerfetto 不需要等到每条分析路径都成熟后才接受外部反馈。越早接触真实设备、真实厂商差异和真实业务 trace,越容易把 Skill、策略和回归样本补到该补的位置。
它解决的是哪类问题
Perfetto 的数据很强,但分析 trace 的工作并不轻松。一个几十 MB 到几百 MB 的 trace 里可能有数百万条事件,线程、slice、counter、FrameTimeline、Binder、CPU 频率、SurfaceFlinger 合成状态分散在不同表和 track 里。
最耗人的部分通常出现在中间:看到一帧超预算以后,要判断是主线程排队、RenderThread 忙、GPU 慢、SurfaceFlinger 合成卡住,还是 Binder、调度、IO 把前面的阶段拖慢了。
SmartPerfetto 把重复的数据收集和初步判断交给工具系统,把需要经验的归因留给 Agent 和工程师共同完成。
适合它处理的问题包括:
- 滑动卡顿:识别掉帧帧、VSync 超预算、App/SF/GPU 责任侧、主线程和 RenderThread 状态。
- 启动性能:拆分冷启动、温启动、生命周期阶段、主线程耗时、Binder、类加载、GC、IO。
- ANR:定位主线程阻塞、Binder 对端、锁等待、调度延迟和系统负载。
- 交互延迟:从 input event 到 frame production,再到 display 的时间分解。
- 内存和 GC:观察 GC pause、内存压力、LMK、dmabuf、系统内存状态。
- 渲染管线:识别 Standard View、Compose、Flutter、WebView、SurfaceView、TextureView、游戏、Vulkan 等路径。
它不替代性能工程师。trace 采集质量、业务上下文、设备差异、复现条件仍然要人判断。SmartPerfetto 更像一个能稳定跑 SQL、整理表格、按策略检查遗漏项的分析助手。
运行截图
实际运行时,AI Assistant 可以作为 Perfetto UI 里的浮动窗口出现,也可以和时间线、场景标记、分析报告一起工作。用户加载 trace 后,在同一个界面里完成提问、工具调用、证据展开和结论复核。
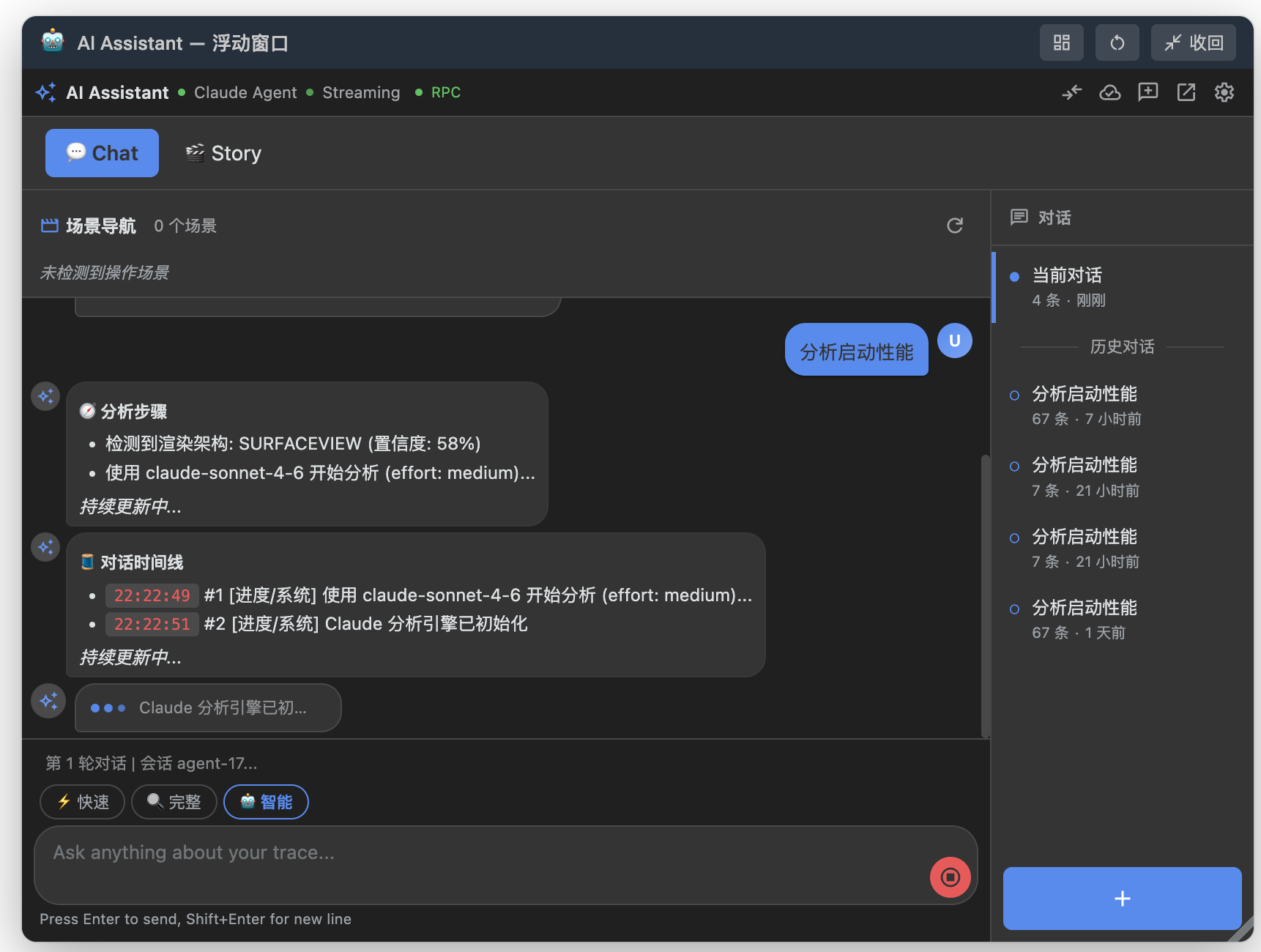
浮动窗口适合在不离开 Perfetto 时间线的情况下追问。窗口里保留当前对话、场景入口、历史会话和输入框,适合边看 trace 边确认下一步分析方向。
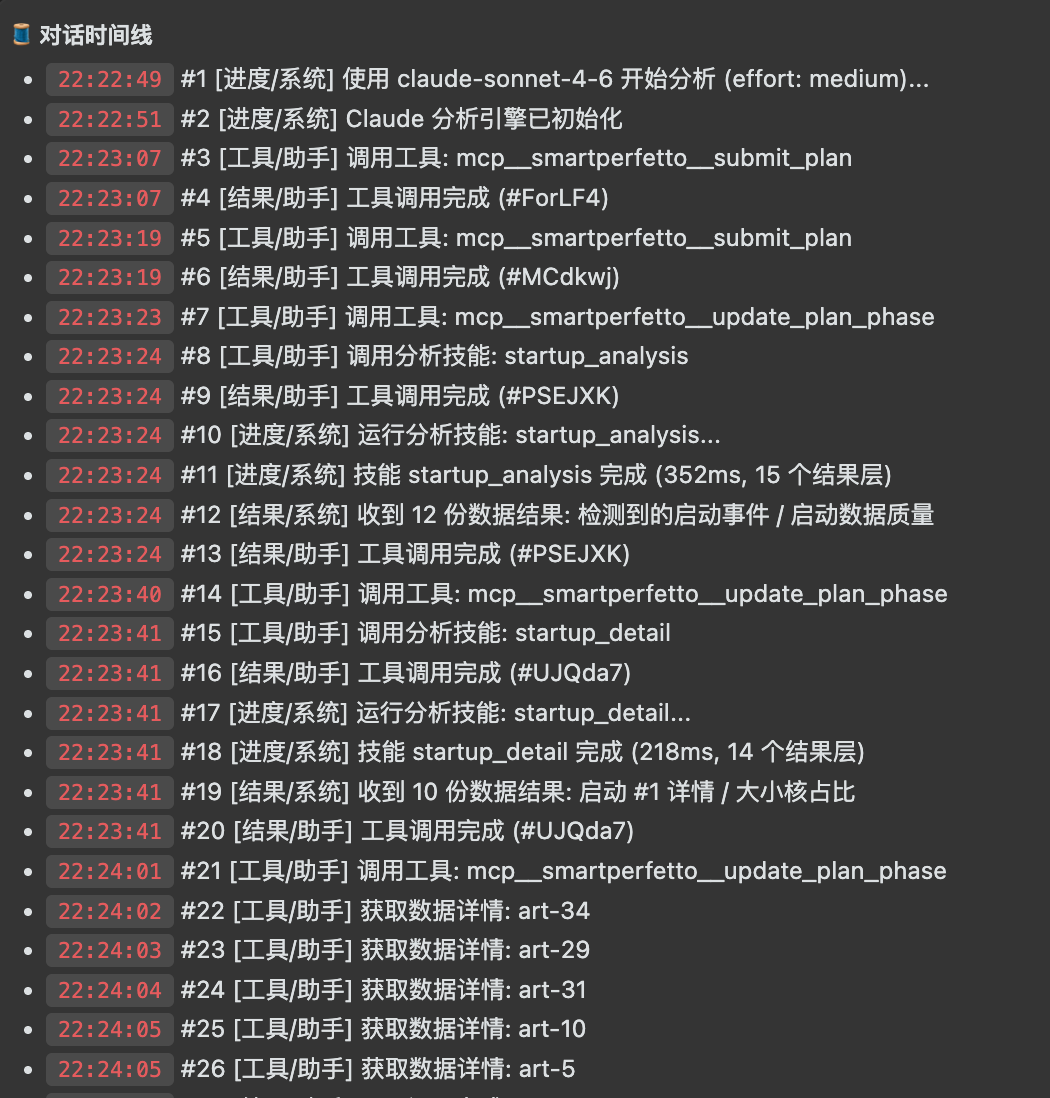
对话时间线会记录 Agent 初始化、计划提交、Skill 调用、SQL 查询和数据详情获取。最终结论之外,中间动作也能回看。
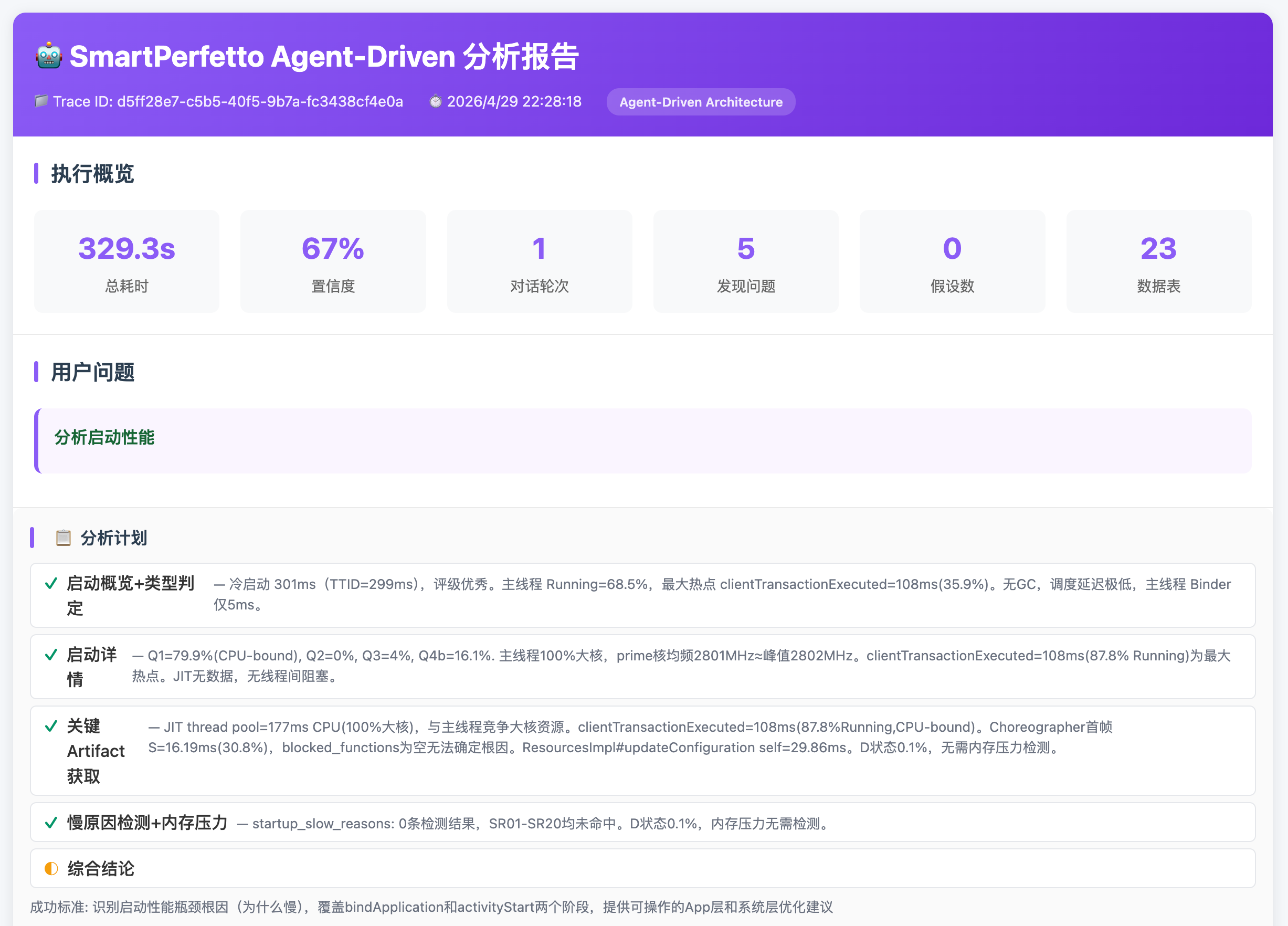
分析报告会把启动事件、数据质量、阶段耗时、可疑片段和建议整理到同一份结果里,方便从自然语言结论回到具体证据。
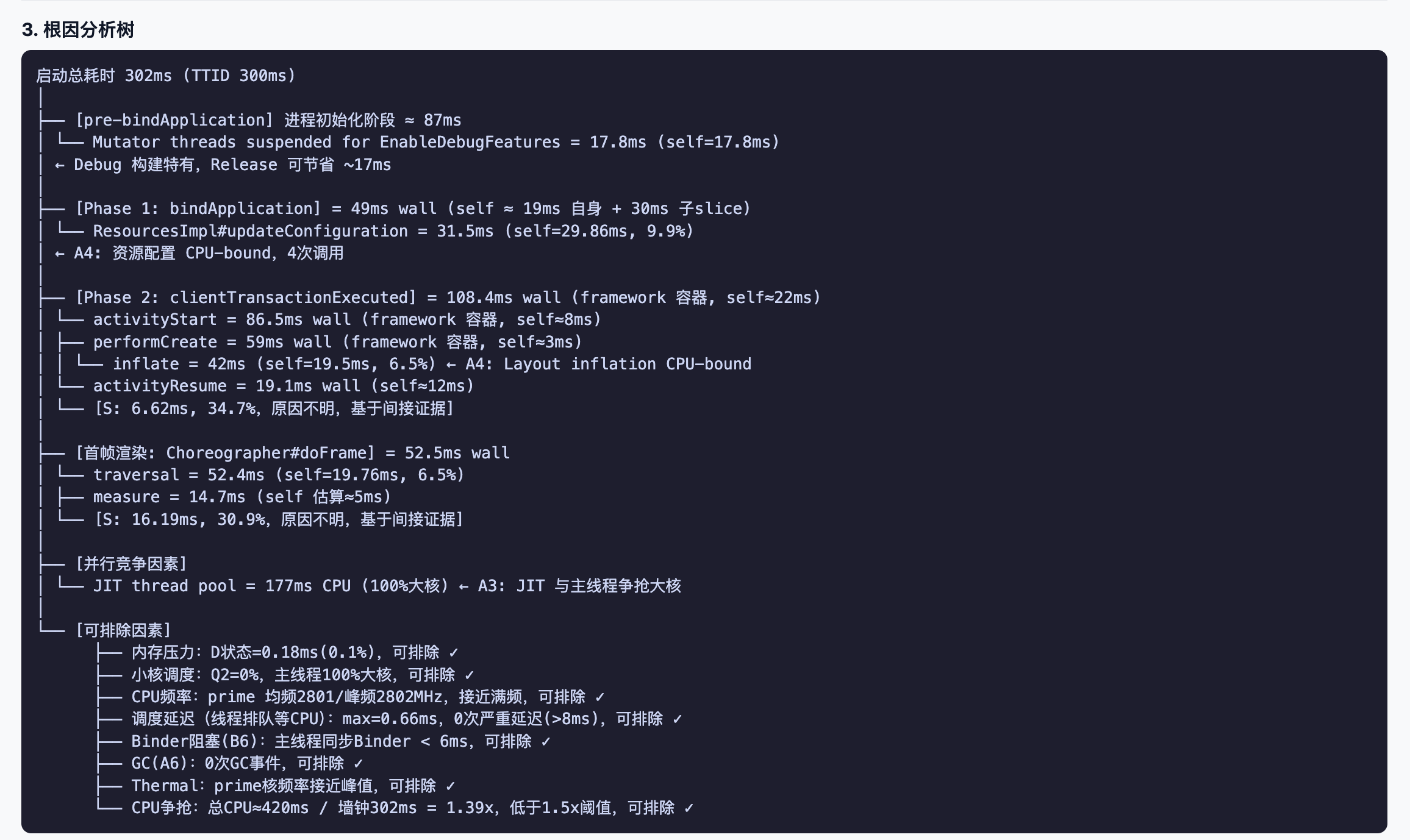
根因定位会尽量把判断落回线程、时间、SQL 结果和 trace 片段。工程师仍然需要结合业务上下文复核,但不用从空白 SQL 开始翻。
整体架构
SmartPerfetto 的主干架构可以分成三层:前端仍是 Perfetto UI,后端负责编排 Agent 和工具,数据查询交给 Perfetto 官方的 trace_processor_shell。
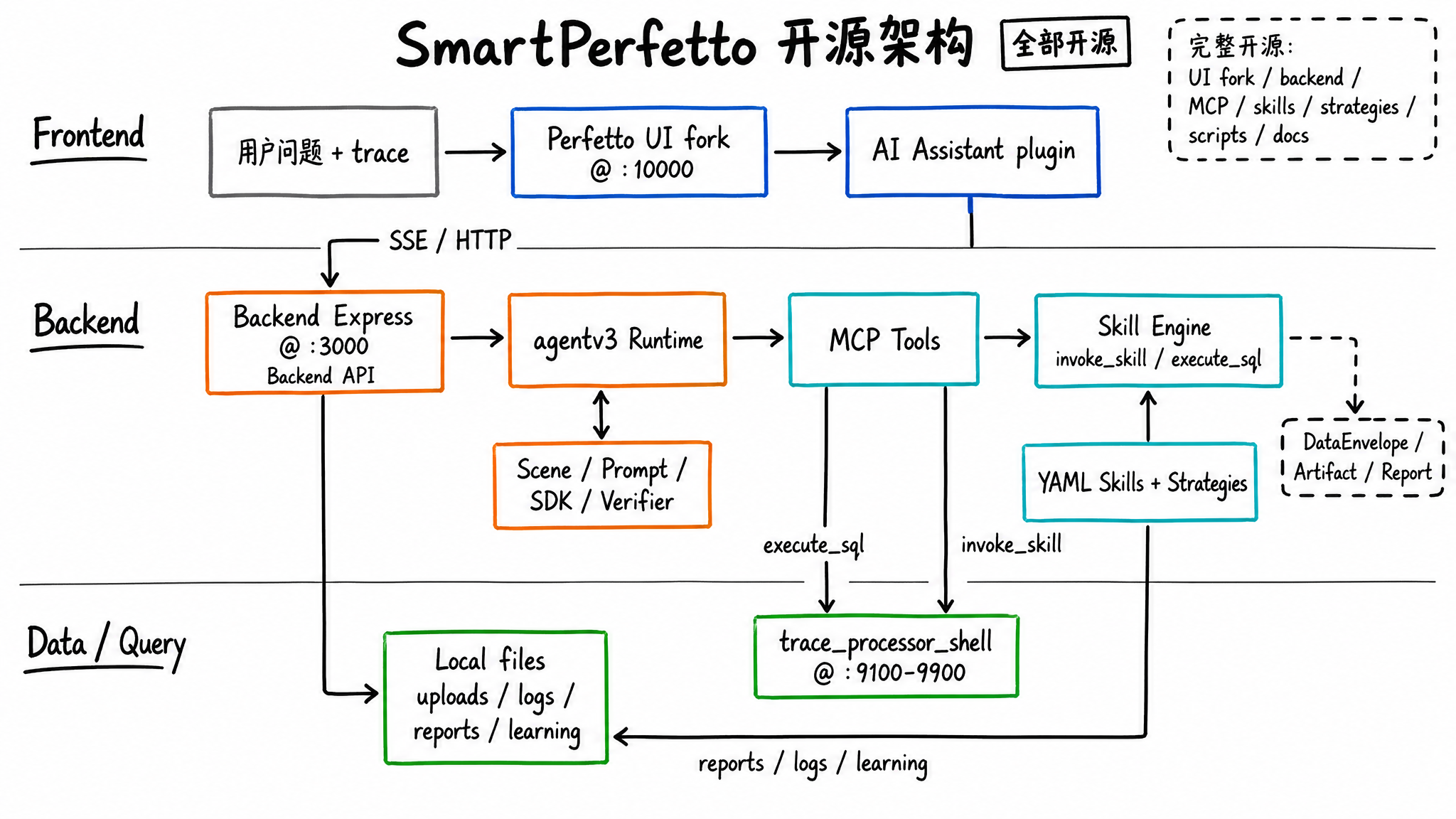
这张架构图里有几条边界要看清:
- 前端不直接分析 trace,只负责加载 trace、展示时间线、发送问题、接收 SSE 事件和渲染结果。
- 后端的
agentv3是主运行时,负责场景识别、Prompt 组装、MCP 工具注册、Verifier 检查和报告生成。 trace_processor_shell仍然是数据查询引擎,所有性能数字都来自 SQL 或 Skill 里的确定性计算。- YAML Skill 负责把常见分析流程封装成可复用单元,Agent 不需要每次从零写复杂 SQL。
这个设计背后的判断很直接:大模型适合理解问题、选择方向、组织因果关系;数据库和 Skill 适合做查询、统计、分页、格式化和重复执行。
Skill:把性能经验写成可执行分析单元
SmartPerfetto 没有把所有分析逻辑都写进 TypeScript,也没有让大模型自由拼 SQL。大量领域逻辑放在 YAML Skill 里。
一个 Skill 可以声明输入参数、前置表、SQL、显示列、分层输出、条件分支、iterator 和并行步骤。Agent 只需要调用:
1 | invoke_skill("scrolling_analysis", { process_name: "com.example.app" }) |
后端的 Skill Engine 会执行对应的 SQL 和组合步骤,并把结果包装成前端能渲染的 DataEnvelope。这样做有三个好处:
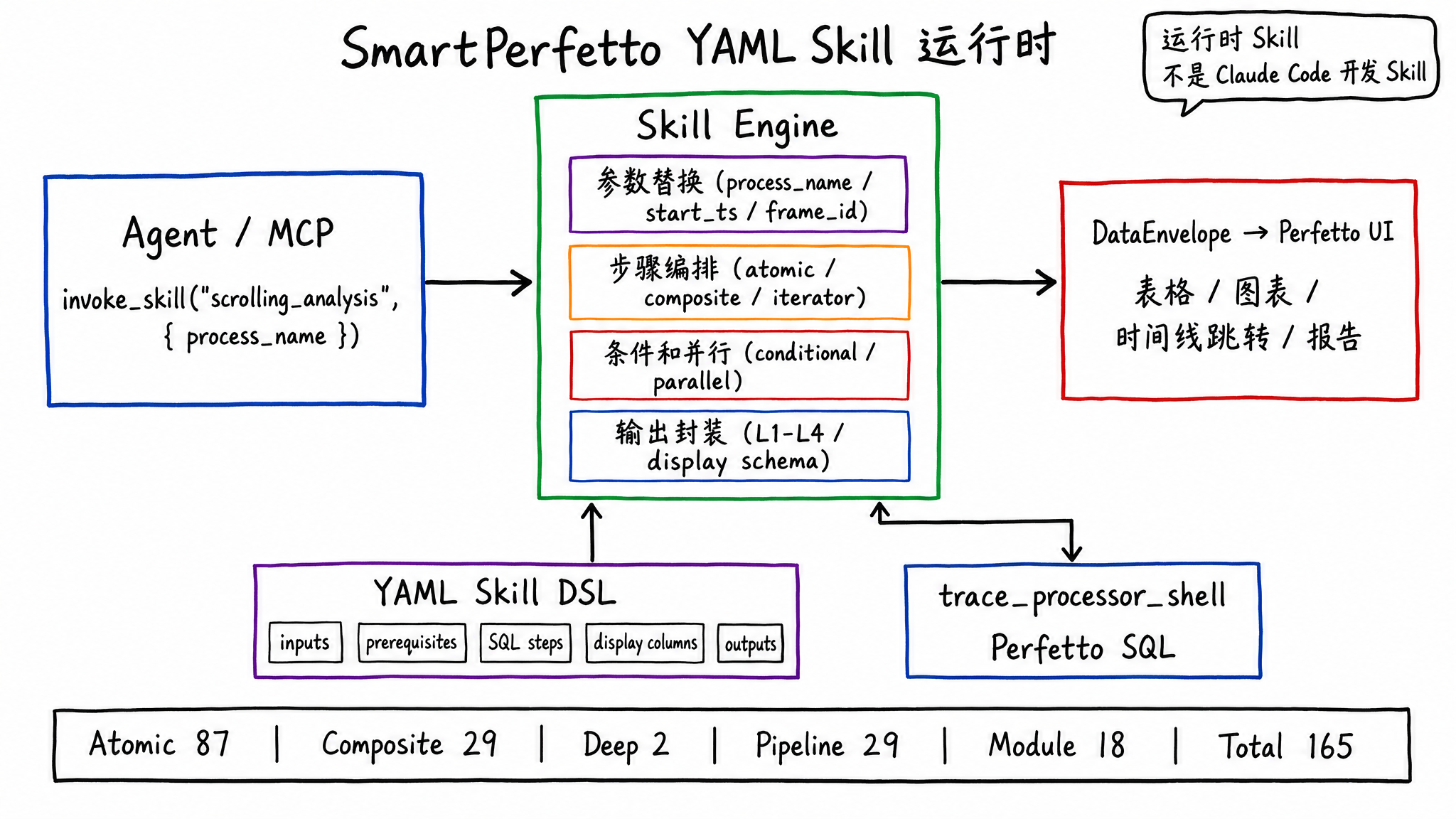
- 结果可重复:同一个 trace、同一组参数,Skill 的计算路径稳定。
- 输出可展示:列名、数据类型、时间戳跳转、duration 格式化都在 Skill 里声明。
- 贡献成本低:熟悉 Perfetto SQL 的性能工程师可以改 YAML 和 SQL,不必先理解完整后端代码。
当前 Skill 分布是:
| 类型 | 数量 | 位置 | 用途 |
|---|---|---|---|
| Atomic | 87 | backend/skills/atomic/ | 单项 SQL 查询,例如 CPU 频率、Binder、GC、FrameTimeline |
| Composite | 29 | backend/skills/composite/ | 多步骤分析,例如 scrolling_analysis、startup_analysis、anr_analysis |
| Deep | 2 | backend/skills/deep/ | 调用栈和 CPU profiling 等深度分析 |
| Pipeline | 29 | backend/skills/pipelines/ | 渲染管线检测和教学内容 |
| Module | 18 | backend/skills/modules/ | app/framework/kernel/hardware 分层专家模块 |
这套 Skill 系统属于 SmartPerfetto 运行时能力,和开发工具里的 Skill 分开看。Claude Code Skill 帮开发者写 SmartPerfetto;SmartPerfetto YAML Skill 帮用户分析 trace。两者名字相近,运行位置、输入输出和目标都不同。
MCP:让 Agent 只通过工具接触 trace
SmartPerfetto 通过 MCP (Model Context Protocol) 给 Agent 暴露工具。Full 模式下最多 20 个工具,Fast 模式下只保留 3 个轻量工具。
常用工具分几类:
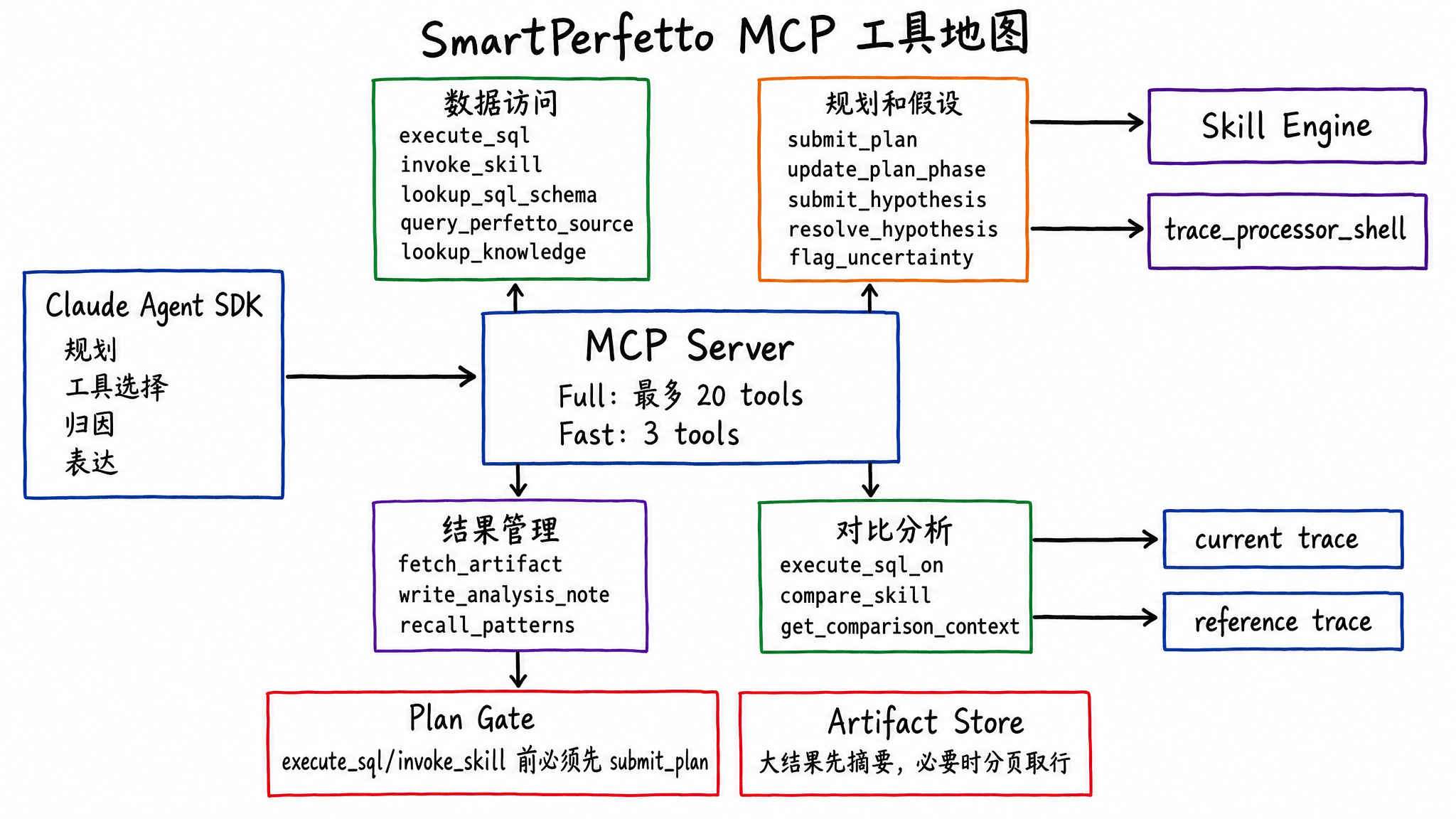
- 数据访问:
execute_sql、invoke_skill、list_skills、lookup_sql_schema、query_perfetto_source、list_stdlib_modules、lookup_knowledge、detect_architecture。 - 规划和假设:
submit_plan、update_plan_phase、revise_plan、submit_hypothesis、resolve_hypothesis、flag_uncertainty。 - 结果管理:
fetch_artifact、write_analysis_note、recall_patterns。 - 对比分析:
execute_sql_on、compare_skill、get_comparison_context。
其中 execute_sql 和 invoke_skill 有计划门控。Agent 必须先提交分析计划,才能开始查数据。这个门控不追求把流程写死,而是要求 Agent 在动手前声明阶段、目标和预期工具,后续 Verifier 再检查关键动作是否缺失。
工具返回的数据也会被压缩和分层。大结果会进入 Artifact Store,Agent 先拿摘要,必要时再分页取行。这样可以避免一次 Skill 输出几十万 token,把上下文耗尽。
从提问到结论的流程
用户输入一句「分析滑动卡顿」后,SmartPerfetto 不会直接把 trace 发给大模型。trace 文件不会进入 prompt,Agent 接触到的是工具返回的结构化结果。
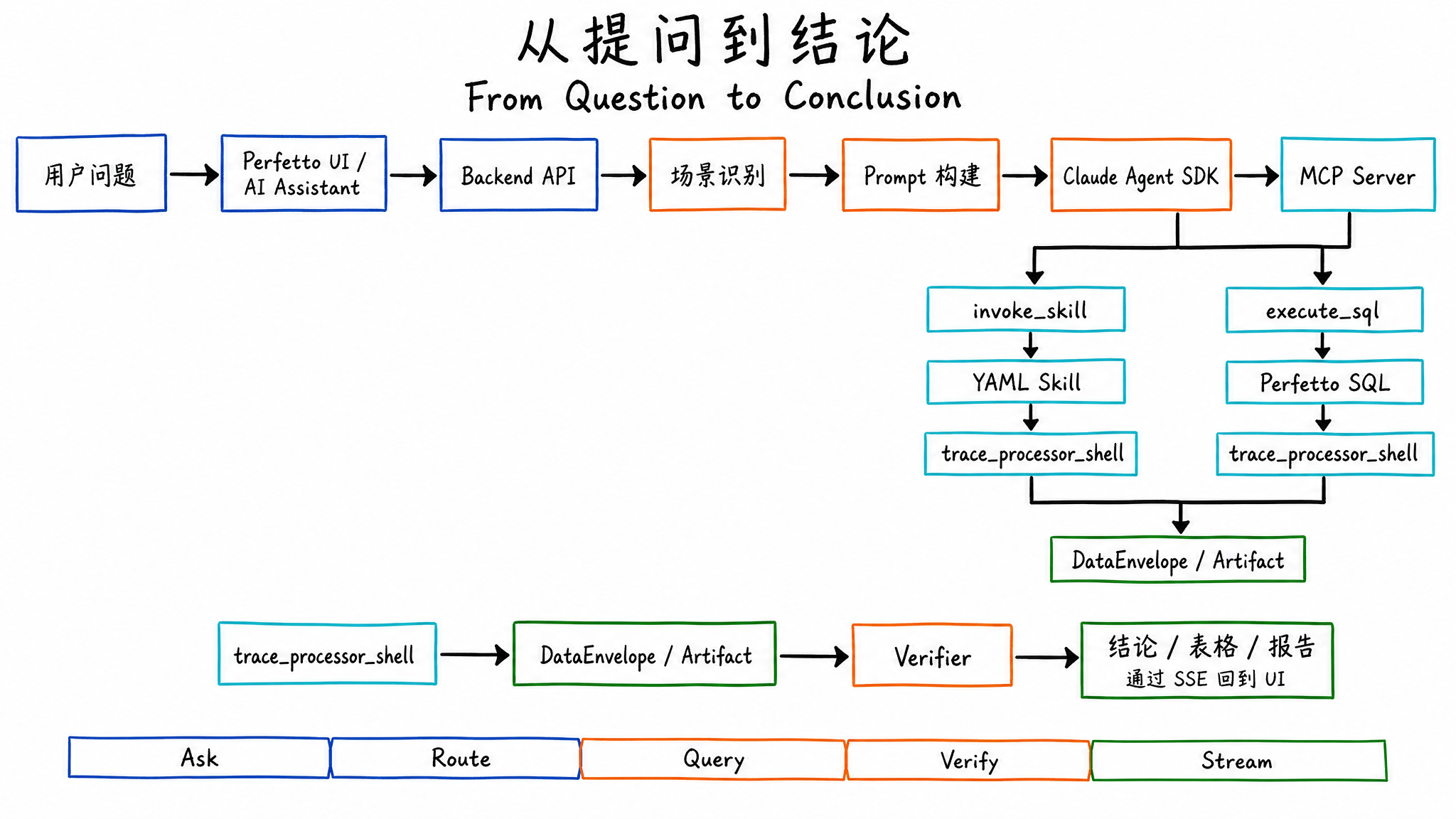
一条滑动卡顿分析通常会经过这些步骤:
- 前端把问题、traceId、分析模式发给后端。
- 后端判断场景,例如
scrolling、startup、anr、memory、pipeline、general。 - Prompt Builder 注入对应的
.strategy.md、架构模板、输出格式和必要知识。 - Agent 先提交计划,再调用 MCP 工具。
- 首选
invoke_skill跑预定义分析;Skill 不覆盖时再用lookup_sql_schema和execute_sql补查询。 - Skill 和 SQL 结果以 DataEnvelope、Artifact、表格或摘要形式返回。
- Verifier 检查证据支撑、假设状态、场景覆盖和常见遗漏项。
- 后端通过 SSE 推送进度、工具结果、answer token、conclusion 和最终 report。
最终用户会看到自然语言结论,也会看到表格、时间戳跳转、报告 URL 和可继续追问的 session。
怎么跑起来
想试一条自己的 trace,按最短路径跑起来即可。仓库已经带了预构建 Perfetto UI,普通试用不需要初始化 perfetto/ submodule,也不需要本机准备 C++ 构建环境。
1 | git clone https://github.com/Gracker/SmartPerfetto.git |
当前默认开发环境按 macOS 梳理。Windows 用户建议使用 Docker Desktop,并启用 WSL2 backend;如果要从源码跑开发脚本,也建议放在 WSL2 里,不要用原生 Windows shell。Ubuntu 等 Linux 发行版还缺少充分测试,遇到问题可以带上环境信息提 Issue 或 PR。
只想先跑起来,推荐使用 Docker Hub 镜像。这个路径只需要 Docker Desktop/Engine 和一个大模型 API Key,不需要安装 Node.js;镜像内已经包含后端、预构建前端和固定版本的 trace_processor_shell:
1 | cp backend/.env.example .env |
启动后打开 http://localhost:10000,加载 .pftrace 或 .perfetto-trace 文件,再打开 AI Assistant 面板。后端健康检查地址是 http://localhost:3000/health。上传文件和日志保存在 Docker volume 中,容器重启后仍会保留。
如果要停止容器:
1 | docker compose -f docker-compose.hub.yml down |
只有测试 Dockerfile 改动,或者构建还没发布到镜像的本地代码,才需要走源码构建:
1 | cp backend/.env.example backend/.env |
源码构建仍然使用仓库里的 frontend/ 预构建产物,不会重新编译 perfetto/ submodule。
本地从源码 checkout 启动,用 ./start.sh。这个脚本会使用仓库里的 frontend/ 预构建产物,并在需要时下载固定版本的 trace_processor_shell:
1 | cp backend/.env.example backend/.env |
只有要改 AI Assistant 插件 UI,例如 ai_panel.ts、styles.scss,才需要初始化 Perfetto submodule 并使用前端开发脚本:
1 | git submodule update --init --recursive |
两种本地脚本都会启动两个服务:
- 前端:
http://localhost:10000 - 后端:
http://localhost:3000
日常改后端、Skill、策略或普通文档,优先用 ./start.sh;改 Perfetto 插件 UI,再切到 ./scripts/start-dev.sh。
模型接入以 Anthropic 直连或 Anthropic Messages 兼容代理为主。第三方模型需要通过代理层适配,并稳定支持 streaming 和 tool/function calling;如果模型只能聊天,不能稳定调用工具,SmartPerfetto 的 SQL 查询和 Skill 调用就跑不完整。
适合从哪里贡献
如果这个项目后续能变得可靠,最需要的是可复现的 trace、能跑的 SQL、能解释失败原因的 Skill 和持续补进来的回归样本。
可以从这些地方开始:
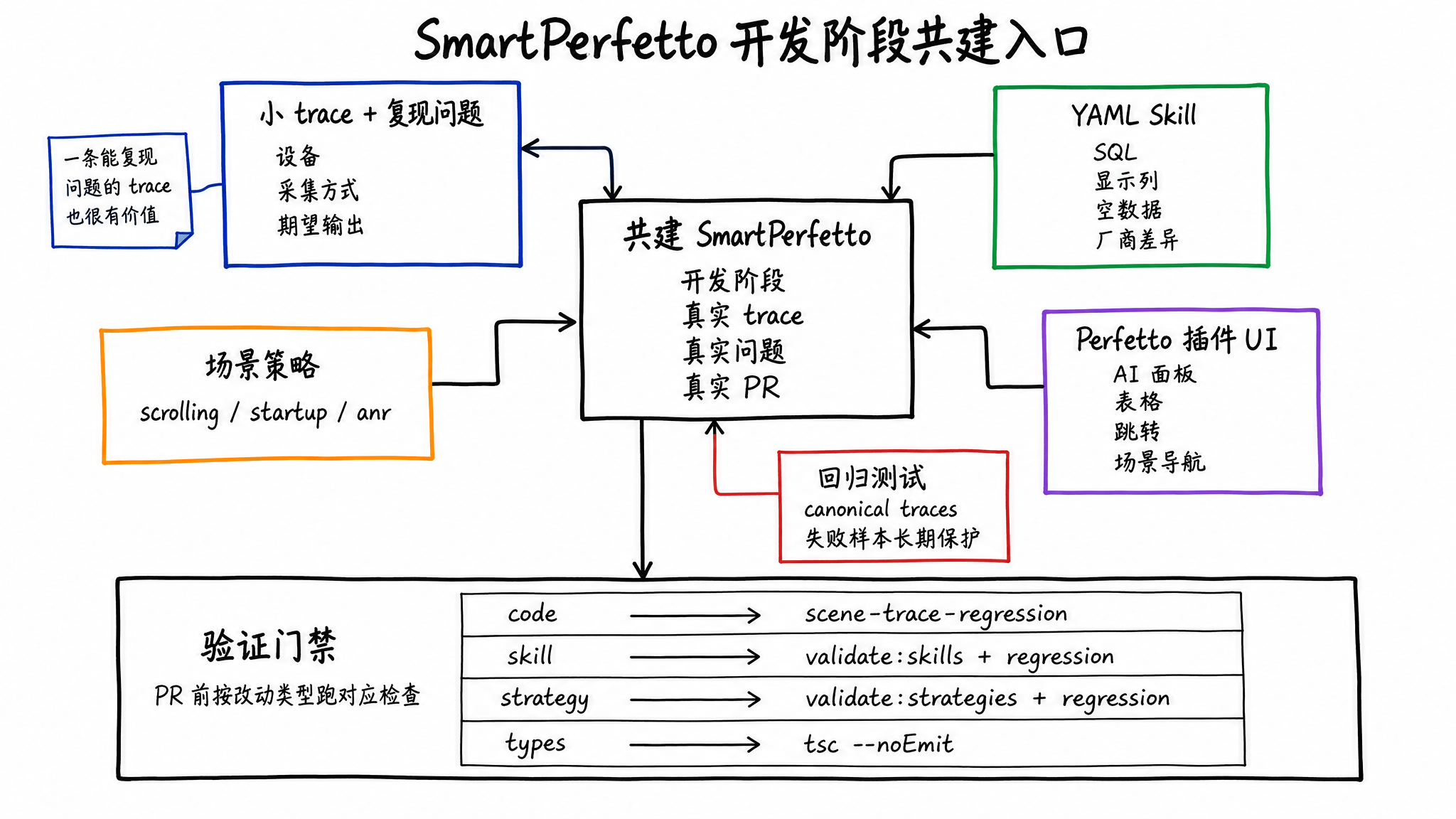
- 提供小 trace 和复现问题:一条能说明问题的 trace,比一段抽象描述更容易转成测试和 Skill。
- 改进 YAML Skill:补充 SQL、显示列、空数据提示、厂商差异、边界条件。
- 改进场景策略:让
scrolling、startup、anr等策略覆盖更多常见分析步骤。 - 修 Perfetto 插件 UI:AI 面板、表格、图表、跳转、场景导航都在前端插件里。
- 补回归测试:项目已有 6 条 canonical trace 回归门禁,新的失败样本可以变成长期保护。
开发阶段更新很快。参与开发前先同步 SmartPerfetto 主仓库;如果改 AI Assistant 插件 UI,再同步 perfetto/ submodule。发现问题、改进项,或者已经在 fork 里修了 bug,优先开 Issue 或 PR,把复现 trace、期望输出和测试结果写清楚。
如果想长期参与 Skill、Agent 或前端开发,可以通过 README 里的联系方式沟通协作,附上 GitHub 账号和邮箱,方便后续加到核心开发协作里。
提交 PR 前,按改动类型跑对应检查:
1 | cd backend |
不同 PR 跑的检查不一样。代码改动至少跑 scene trace regression;Skill 改动跑 validate:skills 加回归;策略和模板改动跑 validate:strategies 加回归;类型或构建问题要补 npx tsc --noEmit。
许可证和当前边界
SmartPerfetto 核心代码使用 AGPL-3.0-or-later。perfetto/ submodule 是 Google Perfetto 的 fork,继续使用 Apache-2.0。企业内部改造、对外提供服务、商业集成前,需要认真理解 AGPL 的义务;如需不受 AGPL 义务约束的商业授权,可以通过 README 里的联系方式沟通。
把项目完整开源,不代表每条分析都已经完成。运行层面还有几条边界:
- 最适合 Android 12+ 且包含 FrameTimeline 数据的 trace。
- 模型需要稳定支持 streaming 和 tool/function calling。
- 第三方模型兼容性还需要更多真实测试,当前更建议先走 Anthropic 直连或稳定的 Anthropic 兼容代理。
- trace 采集缺字段时,很多结论只能降级为缺数据说明。
- Agent 输出仍要由工程师复核,尤其是厂商定制、非标准渲染路径和复杂跨进程等待。
开源后,SmartPerfetto 把可重复的 trace 查询、场景步骤、数据展示和质量检查都放到仓库里。性能分析不会变成一句 prompt,复杂问题仍然要回到 Perfetto、SQL、trace 证据和工程经验上。
SmartPerfetto 想做的是把这些经验变成可以被修改、审查、复用、回归的工程。
讨论群组
如果你正在试用 SmartPerfetto,或者想反馈 bug、讨论 trace 分析结果、提交 PR、共建 Skill/Agent/前端能力,可以扫码加入讨论群:

如果群二维码已满或过期,可以加我微信 553000664,备注 SmartPerfetto,我拉你进群。