打造高性能高可靠的块存储系统
作者从为云计算提供底层支撑的角度出发,分享了如何构建一个高性能、高可靠的块存储系统。文章指出,为了解决云主机创建缓慢、物理硬件维护困难以及OpenStack原生架构中存储资源内耗等问题,他们选择了基于Ceph来搭建统一的分布式块存储。 方案的核心是将OpenStack的计算(Nova)、镜像(Glance)和云硬盘(Cinder)三大服务的后端存储统一到Ceph。这带来了显著的收益:虚拟机创建时间从分钟级大幅缩短至10秒以内,并支持了快速热迁移。同时,系统提供了灵活的云硬盘类型(性能型与容量型),单盘性能可达6000 IOPS、延迟低于2ms,并通过三副本机制实现了高达10个9的持久性。 文章还详细介绍了他们在软硬件选型(如全面转向SSD)、最小部署架构(12节点起步)以及集群平滑扩展方面的实践经验。通过这一系列改造,他们成功打造了一个既满足云主机快速供给,又能承载高性能数据库需求的存储基础设施。
编程珠玑番外篇-Q 协程的历史,现在和未来
这篇讲的是协程这个概念如何从解决上世纪60年代一个具体工程难题中诞生,并在编程思想的变迁中沉浮的故事。 作者从COBOL编译器的编写困境出发,指出在依赖磁带存储、无法做中间文件随机读写的年代,词法与语法解析必须协同推进,这直接催生了“让出”与“恢复”控制流的协程思想。然而,协程在随后数十年并未成为主流命令式语言的“一等公民”,因为它与当时奉行的“自顶向下”设计哲学格格不入——在层次化的子过程调用范式下,协程独特的控制流切换机制显得无用武之地。 文章的核心观点在于,协程的复兴与现代动态语言(如Python)和异步编程的兴起密切相关。Python的生成器就是协程思想的典型体现,通过一个简洁的`yield`关键字,就实现了状态的保存与恢复,并能优雅地串联起复杂的数据处理流水线。作者认为,无论实现形式是“有栈”、“无栈”还是基于通道,其内核都是控制流的协同调度,这正是协程在并发编程和流处理中展现强大生命力的原因。 文章最后指出,随着硬件并行性能的提升和用户态任务调度模型的普及,协程这种轻量、高效的抽象正重新变得至关重要。理解其历史脉络,有助于我们更好地把握现代编程语言中各类协程模型设计的本质。
关于FIN_WAIT1
这篇讲的是TCP连接关闭过程中FIN_WAIT1状态持续时间的问题。作者从TCPCopy社区的一个讨论切入,先通过经典的四次挥手流程图帮我们回忆TCP关闭的步骤,重点解释了主动关闭方在发出FIN包后所处的FIN_WAIT1状态。 文章核心是纠正一个常见误解:很多资料会说tcp_fin_timeout控制FIN_WAIT1的超时,但实际上这个参数控制的是FIN_WAIT2状态的持续时间。真正的关键参数是tcp_orphan_retries,它决定了当FIN包的ACK确认未收到时,系统会进行多少次重试。作者通过一个用netcat和iptables搭建的实验,清晰地展示了FIN包被丢弃后的重试行为——每次重试间隔翻倍(约200ms,400ms,800ms...),并引用了Linux内核源码来证明当tcp_orphan_retries设为0时实际生效值为8。 因此,对于线上出现大量FIN_WAIT1连接的服务器,解决方案很明确:根据网络状况适当调低tcp_orphan_retries的值。文章最后还延伸了一点,讨论了FIN_WAIT1状态可能被利用进行DoS攻击的风险,使话题更深入。
大规模Hadoop集群在腾讯数据仓库TDW的实践
这篇讲的是腾讯数据仓库TDW如何将多个小集群合并为单个超大规模Hadoop集群的实战。作者从集群碎片化导致的数据共享困难、资源利用率低以及运维成本高等痛点出发,剖析了从400台节点扩展到4000台时遇到的核心挑战——Hadoop的单点瓶颈。 为解决JobTracker的调度瓶颈,他们借鉴YARN和Corona,将计算引擎重构为三层架构。关键优化包括将单路心跳拆分为任务和资源两路心跳,引入细粒度的资源管理概念,并将调度模式从基于心跳的拉取变为ClusterManager主动下推。这使平均调度时间从80ms降至1ms,极大提升了扩展性与效率。 针对存储层的NameNode单点风险,TDW设计了“一主两热备”的高可用方案,通过日志同步保证热备节点能随时接管,将计划内服务停止时间从近2小时大幅缩短。 整个改造在未大幅变动外围调度系统的前提下,成功支撑了数千节点规模的单集群,体现了在工程复杂度与系统收益间的务实权衡。
Feed消息队列架构分析
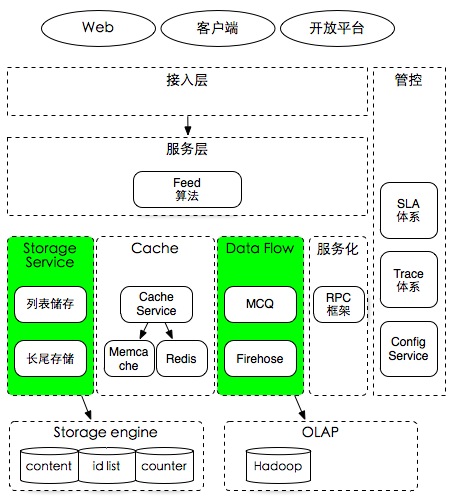
这篇讲的是微博为应对实时Feed流挑战而构建的消息队列架构。作者从数据流处理从离线走向实时的行业趋势切入,详细拆解了支撑海量社交信息流的底层架构。 核心是一个由三部分构成的体系:中间是feed主流程处理,通过MQ worker异步写入缓存和数据库,完成核心的削峰填谷;左侧是流式计算,用于大数据实时分析;此外还有负责多机房数据同步的“虫洞”模块。整个系统建立在几个关键单元上:单机队列MQ、支持一对多投递的统一通道Firehose(具备基于社交关系的fan-out能力),以及无状态的Worker。 架构设计上,文章强调了其高实时性(要求100ms内处理完成)、线性可扩展性与超高可用性(99.999%)。最后,文章还对比了LinkedIn Databus、Apache Storm和Kafka等技术路线,解释了为何其业务主动写入事件的方案在复杂分库场景下,比数据库触发方案更具原子性和简洁性。
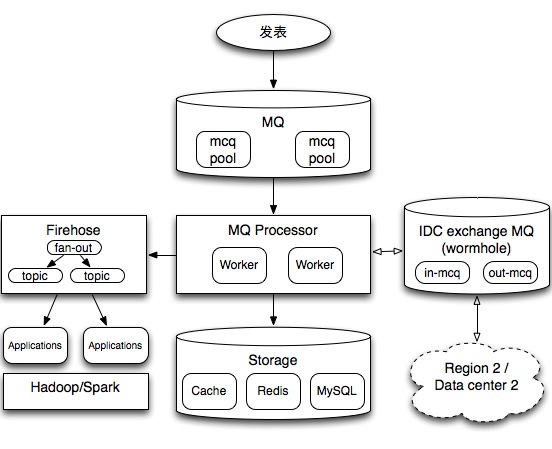
Feed架构-我们做错了什么
这篇讲的是微博技术团队在Feed架构演进中的一次坦诚复盘与反思。作者从团队过去几年成功解决的工程挑战切入——包括通过冷热分区设计应对长尾数据访问、利用数据库拆分实现存储扩展、依托缓存分级支撑百万级QPS,以及建设高可用的SLA体系。 但文章的重点不在这些成就,而是深入剖析了基于用户关系的分发架构在用户侧引发的“信息过载”问题。核心观点是:架构在解决了可扩展性与性能问题后,却造成了内容组织与消费效率上的新瓶颈。具体表现为:当前架构天然基于用户关系维度组织数据,这很难服务于更高效的“兴趣阅读”需求;同时,低质内容识别、实时反垃圾算法仍面临巨大技术挑战;此外,社交关系带来的“可解释性”要求(用户期望看到好友内容)也与纯粹的算法排序存在矛盾。 作者通过这次复盘,揭示了一个关键认知:Feed架构的难题已从纯粹的后端扩展性问题,转向了如何通过技术更好地理解与满足用户兴趣,同时平衡产品体验的复杂层面。这对于思考推荐系统与社交产品架构的未来方向,提供了很有价值的视角。
php调试利器之phpdbg
这篇文章详细介绍了PHP的轻量级调试工具phpdbg。作者指出,phpdbg作为一个SAPI模块,最大的优势在于无需修改代码、几乎不影响性能,就能对PHP程序进行断点调试、单步跟踪和代码分析,非常适合线上或性能敏感场景下的排查。 文章核心讲解了phpdbg的主要功能与使用方法。功能上,它不仅支持按文件行号、函数方法设置断点,还能精确到opcode层级进行断点设置,这对深入理解PHP执行流非常有帮助。安装部分给出了清晰的编译指令示例,并强调了从PHP 5.6版本开始的集成变化。基本使用则通过具体代码示例,展示了如何启动工具、加载脚本、设置/查看/删除断点,以及单步执行等常用调试操作,过程与GDB等工具思路相似,但更贴合PHP特性。 总体而言,这是一篇实用性很强的工具指南。对于PHP开发者来说,掌握phpdbg能提供一个轻便且强大的本地调试方案,尤其适合那些不便于使用Xdebug等重型工具,或需要最小化环境干扰的调试场景。
Linus:为何对象引用计数必须是原子的
Linus在这篇长文里,用一个具体的编程细节,撕开了“并行计算很简单”这个流行错觉的口子。他聚焦于一个看似基础的问题:为什么在多线程环境下,对象的引用计数必须是原子操作。 文章的核心论证在于区分两种完全不同的锁机制:一种是保护“对象数据”的锁,另一种是保护“查找对象”这一过程的锁。Linus指出,引用计数的原子性之所以关键,是因为在复杂的对象图(graph)中遍历时,为了避免死锁(特别是经典的ABBA死锁),你必须在持有对象A的锁时,安全地转向对象B。此时,原子性地增加对象B的引用计数,就成了确保对象B在解锁后不会“消失”的唯一安全绳。如果你认为引用计数不需要原子化,这恰恰暴露了你对锁机制复杂性的无知。 通过这个精巧的例证,Linus抨击了那些只看到简单数组并行排序、却无视真实世界中对象动态分配与释放复杂性的乐观论调。他用这个例子揭示,许多被宣传为“容易并行化”的案例,其实都巧妙回避了并发编程中最棘手的部分。这篇文章最终指向一个硬核结论:并发设计本质上是困难的,而许多关于并行未来的讨论,建立在对这种困难严重低估的基础上。
nginx反向代理做克隆采集小偷垃圾站,还能翻墙
这篇讲的是如何利用Nginx反向代理快速搭建一个网站内容镜像或代理站。作者从一个具体的配置文件入手,展示了核心步骤:通过`proxy_pass`将本地域名请求指向目标站点IP,并配合`proxy_set_header`伪装访问头,使对方服务器记录的是代理IP。文章特别强调了两个实用技巧:一是通过`subs_filter`规则(需安装第三方`nginx_substitutions_filter`模块)在返回页面前动态替换文本内容,可用于清理广告或修改版权信息;二是通过设置`Accept-Encoding`为空来禁用压缩,确保替换模块能正常工作。 作者还手把手演示了如何在已有NginX基础上,通过重新编译添加该模块的完整流程,从下载源码、查看原编译参数、执行`make`到平滑替换二进制文件,步骤清晰。整个方案相当于用NginX作为“中间人”,低成本实现了内容抓取、过滤与转发,对于需要快速搭建本地化内容镜像或进行页面预处理的开发者来说,是一套直接可用的技术脚本。
Django框架ORM操作详解
这篇详解聚焦于Django ORM的操作实践,从基础的CRUD到查询集的深度使用都有覆盖。作者以一个博客系统模型为例,清晰地展示了如何通过Python对象与数据库交互:用`save()`写入数据,用`filter()`与`exclude()`构建查询,以及如何通过点号语法优雅地链接多个过滤条件。 文章特别强调了QuerySet的两个核心特性。一是“延迟执行”,即便堆叠了多个过滤条件,只有在真正需要结果(如遍历或打印)时,Django才会生成并执行最终的SQL语句。二是查询结果集的独立性,每次筛选都会返回一个全新的QuerySet,方便复用与组合,这是构建复杂查询的基石。 此外,内容还深入到了字段查找的语法细节和跨关系查询(如通过`ForeignKey`和`ManyToManyField`)的具体方法。整体上,它不仅仅是一个API列表,更揭示了ORM背后高效、Pythonic的设计思路,帮助开发者写出既简洁又性能良好的数据访问代码。
好的API设计
这篇文章从一次实际的中间件重构经历出发,探讨了“什么样的API才算是好API”。作者指出,API一旦发布便难以更改,因此在设计之初就需格外审慎。 文章清晰地界定了API不仅限于函数或接口,还包括调用方式、约定与依赖等。其核心部分总结了优秀API应具备的六大特点:易于学习、无文档也易用、不易误用(降低使用者心智负担)、使使用者的代码更易维护、能完备且正交地满足需求,以及易于扩展。 针对如何实现,文章提炼出八条精炼的设计原则:功能单一、体量尽可能小、减少外部依赖、设计不被实现细节所影响、谨慎暴露接口、采用自描述的命名、配套完善的文档,并始终考虑性能。文末附有多个跨语言的参考资料来源,为这些原则提供了扎实的理论依据。 整篇文章没有空谈理论,而是从“发布即定型”的现实约束出发,将API设计拟人化,强调其“秉性”的稳定。它为开发者提供了一份清晰可操作的自查清单,提醒我们在敲下第一行实现代码前,先思考如何设计一个“好相处”的接口。
多线程下的fork及写时复制导致的性能问题
这篇讲的是贴吧在将服务从PHP-FPM迁移到HHVM(多线程模型)后,遭遇CPU使用率异常飙升的故障排查过程。问题的根源在于,程序中某个基础库调用exec执行shell命令时,会先fork进程。由于HHVM是多线程架构,其他线程在fork期间的内存写入,会频繁触发Linux内核的“写时复制”机制,导致大量不必要的内存拷贝,从而耗尽CPU资源。 作者详细剖析了写时复制的工作原理,指出在单进程模型(如PHP-FPM)下,fork后立刻exec的场景几乎不会触发复制,效率很高。但在多线程环境中,共享的地址空间让这一优化失效,成为了性能杀手。 为了解决这个问题,HHVM采用了一个巧妙的方案:提前创建一个代理进程池。当需要执行外部命令时,主线程通过管道将任务分派给处于单线程环境的代理进程,由后者去完成fork/exec操作。这样就将可能引发写时复制的操作,安全地隔离在了独立进程中,从根本上规避了性能陷阱。文章从实战故障出发,清晰揭示了多线程与操作系统机制交互时容易被忽视的深水区问题。
HashMap解决hash冲突的方法
这篇讲的是 HashMap 如何巧妙处理哈希冲突。作者直接从 put 方法的源码切入,展示了当不同 key 通过哈希算法映射到同一个数组索引(即“桶”)时,HashMap 采用的“链表法”解决方案。 核心思路很清晰:当发生冲突时,新的键值对并不会替换旧的,而是像插入单链表一样,通过 `addEntry` 方法被添加到该桶的链表头部。文章特别指出,这个新插入的 Entry 对象会指向原先位于该桶的 Entry,从而形成一条单向链表。这就解释了为什么在冲突严重时,get 操作会从直接定位退化为需要遍历链表,最坏情况下复杂度会达到 O(n)。 文章还点出了一个关键的设计权衡——负载因子。默认的 0.75 是空间与查询效率之间的折中:过大会节省内存但查询变慢,过小则查询更快但更耗内存。 总的来说,这篇分析没有停留在概念层面,而是通过源码把链表如何形成、负载因子如何影响性能这些细节讲透了,适合想弄懂 Java 集合框架底层原理的开发者阅读。
标准化与可复用杂谈
这篇讲的是从一次具体的线上问题排查说起,引申出对软件工程中“标准化”与“可复用”的思考。作者描述了一个典型场景:用户反馈的问题经过层层传递,工程师最后发现是某台服务器在特殊情况下启动了错误版本,导致返回数据异常。这背后暴露的是从代码测试、服务调用到上线发布的全流程中,处处依赖人工细心所潜藏的高风险。 文章的核心观点在于,将全流程中那些不易变的单元(如测试、服务交互规范、发布步骤)进行标准化,并用程序来控制,可以从源头减少低级错误。作者以一个深度使用消息队列但因标准化和抽象不足,导致经验难以复用的团队为例,说明了这一点。同时,文章也对比了国内外对工程师严格要求的差异,指出在业务驱动、快速交付的压力下,形成高质量代码共识与推动标准化建设的不易。 文章的启发在于,它并非空谈架构,而是从运维和开发的共同痛点出发,论证了标准化对于解放工程师精力、提升系统可靠性的实际价值,尤其适合那些正被重复性故障和低效协作困扰的技术团队反思。
server日志的路径分析
这篇讲的是如何通过分析Web服务器日志中的路径信息,理解用户访问行为。作者从日常遇到的疑问出发——有人误以为服务器日志来自数据库,借此清晰界定了服务器日志的本质:它是客户端与服务器间所有通信(包括IP、时间、访问路径、状态等)的忠实记录。 文章以Nginx日志为例,逐条拆解了其看似杂乱的格式,对应到日志字段如请求URL、状态码等。核心在于,作者分享了利用Shell命令(awk和sed)从海量日志中提取、清洗并统计访问路径的实战过程。具体来说,通过awk按分隔符切割出URL字段,再结合sort和uniq进行排序计数,最终形成每个路径的访问次数统计。整个分析链条从原始日志文件到生成结构化的路径统计表,步骤清晰。 为了让结果更直观,作者还将统计输出为表格和图表形式,并强调了数据可视化在提升分析体验和洞察效果上的关键作用。整个分享聚焦于“如何做”,是一次从原始数据到可视化结论的完整实践演示。
PHP7 VS HHVM (WordPress)
这篇文章从PHP7与HHVM的性能争议出发,在WordPress站点上进行了一场直接的压测对比。作者使用ab工具,对两套环境(PHP7-FPM与Nginx+HHVM-3.2.0)分别进行了预热后100并发、1万次请求的测试。 结果显示,PHP7达到了258.22 QPS,略高于HHVM-3.2.0的230.97 QPS。作者据此指出,在真实Web场景下,PHP7的性能已与HHVM相当,甚至在某些情况下有所超越。更关键的是,文章深入分析了HHVM在运维层面的潜在风险:其多线程模型意味着单个线程崩溃可能导致整个服务宕机,且依赖JIT编译,在服务重启后需要预热,冷启动性能较差,调试也更为复杂。 作者最终抛出一个核心问题:当PHP7性能已然足够,且更稳定、易于维护时,我们是否还有充分的理由选择HHVM?文章同时回应了此前一些针对HHVM的性能对比案例,认为其对比方法存在缺陷,结论缺乏普适性。

Web编码总结
作者从一次AJAX请求中变量编码不一致的“踩坑”经历出发,引出了Web开发中一个常见却容易被忽视的核心问题:编码。文章并未停留于问题本身,而是系统梳理了从编码简史到实际应用的完整脉络。 它简要回顾了ASCII、GB系列到Unicode/UTF-8的演进,并点出国内大厂网站(如百度、淘宝、QQ.com)在文件编码选择上的历史现状。重点剖析了网页显示中,HTML编码由HTTP头、meta标签和浏览器默认设置共同决定的权重关系,以及CSS文件通过`@charset`指令声明编码的机制。文中穿插了关于操作系统换行符差异等实用小贴士,使技术知识更接地气。 这篇总结的价值在于,它将编码这个看似底层、枯燥的话题,与日常前端开发的具体环节(HTML、CSS、JS文件)紧密结合,帮助开发者建立清晰的排查思路,理解乱码问题的根源往往在于编码声明的不一致或缺失。对于希望夯实基础、避免低级错误的开发者来说,这是一份很好的实践指南。
NAS解决方案实现多媒体文件共享播放
这篇讲的是,如何用家里闲置的台式机,自己动手搭一个家庭影音中心,让笔记本、平板也能像访问本地硬盘一样,流畅播放电脑里的高清大片。 作者从日常存储空间不足的痛点出发,尝试了HTTP、FTP等流媒体方案,但都不够完美。最终,他利用Windows系统自带的SMB文件共享功能,将台式机改造成了家用NAS。 文章的核心在于一步步打通整个共享链路。服务端需要确保Server、TCP/IP NetBIOS Helper等关键服务处于开启状态,正确设置网络属性的NetBIOS选项,并为想共享的文件夹配置好访问权限。客户端则可以映射网络驱动器,直接获得一个类似本地磁盘的盘符。 配置完成后,作者发现直接播放1080P视频仍有卡顿。根因在于顺序读取时对瞬间传输速率要求过高。通过在共享设置中勾选“启用缓存以提高性能”选项,问题得到解决,播放变得流畅。 这个方案不仅限于Windows设备间互联,通过安装相应的应用,类Unix系统或其他终端也能访问这个共享服务。它把一台普通电脑变成了家庭的多媒体文件枢纽,实用性很强。
面试题 – 为什么我的朋友圈不见了?
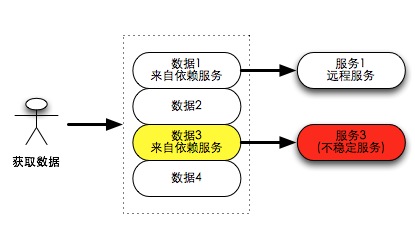
这篇文章从一个常见但棘手的分布式系统问题切入:当一个数据聚合服务需要从多个远程服务获取数据,而其中一个服务不可用时,架构师应该如何选择容错策略? 作者详细剖析了三种典型方案。方案一是直接忽略失败的部分数据(优雅降级),虽然损失最小,但可能导致用户体验不确定。方案二是遇到任何失败就返回整体错误(503),完全依赖调用方的缓存与容错能力,否则用户会看到白屏。方案三则是自定义返回格式,显式告知哪些数据加载成功、哪些失败,但这大大增加了前后端的复杂度。 文章并未止步于此,而是进一步引入了“未读数”这一常见功能,将问题场景变得更复杂:即使主数据列表因服务不稳定而缺损,如果能单独提供一个准确的未读数,用户体验和系统效率会如何变化?这使得对三种方案的权衡更加微妙。 整篇文章的核心价值,不在于给出唯一答案,而是系统性地呈现了架构师在“数据完整性”、“用户体验”、“系统复杂度”和“服务可靠性”之间必须进行的现实权衡。它启发我们思考,在微服务架构下,如何设计既健壮又不过度复杂的容错机制。
PHP优化杂烩
很多PHP开发者习惯通过优化代码来提升性能,但这篇讲的是另一个同样重要的维度:如何配置一个高效的PHP运行环境。 作者从几个常被忽视的配置项出发,系统地梳理了它们对性能和稳定性的影响。首先提到了“进程池”的价值,通过创建独立的池来隔离故障,避免一个慢请求拖垮整个服务。在Nginx与PHP通信的“listen”方式上,文章对比了TCP与Unix Socket,并指出后者虽更高效,但需要调大 backlog 等参数以保证高并发下的稳定。 对于“pm”进程管理,文章明确推荐了静态模式以应对高并发,避免动态模式频繁创建进程带来的开销。最后,也是最实际的:如何设置“pm.max_children”进程数?作者指出这并非一个固定公式,而需要综合考虑CPU类型(IO密集还是计算密集)与内存限制。他通过“RES减SHR”计算出单个PHP进程的实际内存占用(约10MB),从而推导出在有限内存下能承载的最大进程数,并建议结合状态接口进行动态监控。 这篇内容的价值在于,它把性能优化从单纯的代码层面,引向了可系统配置的运行时架构层面,提供了具体可操作的参数调整思路和决策依据。