如何建立一套邮件发送系统
这篇讲的是搭建独立邮件系统时那些容易被忽视的坑和要点。作者没有从零开始手把手教,而是基于网络上分散的经验,梳理出了一个关键注意事项清单——毕竟,自己建一套能稳定、合规收发邮件的系统,涉及DNS配置、反垃圾邮件策略、安全证书、发送配额管理等一连串繁琐但至关重要的环节。 摘要直接点明了文章的核心价值:它帮读者节省了大量搜集和试错的时间,把散落的技术点汇总成了实用的避坑指南。尤其适合那些项目需要自建邮件服务,却不想重蹈覆辙的开发和运维人员。内容虽然简洁,但直击痛点,相当于一份搭建前的自查清单。
请手动释放你的资源(Please release resources maunally)
这是一篇典型的踩坑复盘。作者从一个看似不起眼的编程习惯出发,讲述了一段真实的排障经历。 他之前一直认为,依赖现代语言或运行时环境的自动资源管理(如垃圾回收)是理所当然的,手动释放资源甚至显得多余。直到在昨天一次实际运行中,他遭遇了由未及时释放资源(如数据库连接、文件句柄)引发的性能瓶颈或异常。问题被定位后,根因直指资源的累积占用超出了系统预期。 文章细致地描述了问题从出现到被发现的场景,并通过这次教训反思了过度依赖自动化机制的潜在风险。作者最终得出的结论并非否定自动管理,而是强调在关键路径和长期运行的服务中,开发者必须保持对资源生命周期的敬畏之心,养成在合适时机主动释放的习惯。 这种从“不是问题”到“大问题”的视角转变,恰好提醒了每一位开发者:在便利的抽象层之下,对底层资源的审慎管理依然是写出健壮、高效代码的基石。
漫谈社区PHP 业务开发
这篇讲的是在互联网产品快速迭代的大背景下,PHP在社区业务开发中的实践与思考。作者从当前新产品涌现、老业务不断尝试的现状切入,指出这种环境对开发速度与灵活性提出了更高要求。文章很可能探讨了PHP语言如何适应这种快节奏,或许涉及了开发框架选择、项目结构设计或团队协作流程等方面的经验。 结合“社区PHP”这个标题,内容或许会围绕具体业务场景,比如用户互动、内容管理或数据聚合等功能的实现,分享在保证开发效率的同时如何维护代码质量与系统稳定性。作者可能结合自身实践,对PHP生态中的工具与方法给出了自己的观察与选择建议。 整体上,这篇文章为那些在相似业务压力下工作的PHP开发者提供了一种思路参考,探讨了如何在不断变化的需求中,利用PHP的特性构建可持续迭代的业务系统。
Digg.com 的系统架构
这篇讲的是 Digg 这家老牌新闻网站如何对其核心系统进行了一次彻底的重写,也就是他们内部代号为“V4”的架构升级。 Digg 面临的挑战很典型:随着用户量和内容的增长,早期架构逐渐力不从心,难以支撑新的功能和性能要求。这篇技术分享的核心,就是拆解他们如何用一套全新的技术栈来重构整个引擎,以应对这些挑战。文章会详细展示他们为前端、后端和数据层分别选择了哪些具体技术,以及这些选择背后的权衡考量。比如,为了解决早期架构的瓶颈,他们引入了像 NoSQL 数据库这样的新技术来处理海量数据。 这种对自身核心基础设施进行“外科手术式”重写的详细复盘并不多见。它不仅展示了大型网站演进过程中具体的“手术方案”,更重要的是分享了决策过程中的技术洞察。对于正在规划系统重构或对大规模网站架构感兴趣的工程师来说,了解另一家知名公司从头到尾的思路和实践,是非常有价值的参考。
原子字典
这篇讲的是解决游戏中数据竞争问题的一个具体方案。作者从早前的一个开发笔记切入:当一个线程需要批量修改玩家的多个属性时,另一个线程可能同时通过共享内存在读取这些数据,导致读到一半改好的、一半未改的“不一致”状态。 为了解决这个经典难题,文章提出了一种名为“原子字典”的设计。其核心思路并非简单粗暴的全量加锁,而是通过一个版本号来协调读写。每次批量修改操作(写入方)会被分配一个唯一的版本号,只有当整个批量修改完成时,版本号才会被“提交”。读取方则会在读取前后检查这个版本号:如果版本号在读取过程中发生变化,说明数据正在被修改,就放弃本次读取并重试,从而确保读到的永远是完整且一致的数据快照。 这个方案在保证数据一致性的同时,最大程度地避免了长时间锁定对读性能的影响。作者没有停留在理论描述,而是给出了从定义、操作到在具体场景下应用的完整思路,为处理类似的高频读写、局部批量更新问题提供了一种清晰且可落地的设计模式。
诡异提交失败问题追查
这篇讲的是一次Git提交异常背后的连锁故障排查。作者从开发环境里一个看似普通的“提交失败”提示说起,但常规检查分支权限、文件锁定甚至重新克隆仓库都未能解决问题。深入追查后发现,罪魁祸首是本地的Git hooks脚本中一段看似无害的正则表达式,在特定文件名长度下会触发栈溢出,导致整个提交进程静默崩溃。文章细致地展示了如何通过`strace`追踪系统调用、逐步简化hook脚本,最终定位到这个隐蔽的代码缺陷,并分享了用防御性编程重写该逻辑的修复方案。其价值在于提醒我们,版本控制工具链中的自定义脚本可能成为意想不到的故障源,而系统性的排查思路比盲目尝试更有效。
Nginx+KV db进行AB灰度测试
这篇讲的是如何在运维实践中,将Nginx与KV存储结合,低成本地实现AB灰度测试。 作者从华东运维大会的见闻出发,提到淘宝在Nginx场景下的应用给了他启发。其中,AB灰度测试被认为适用场景非常普遍,但大会并未深入探讨具体实现。于是,他着手探索了一条自己的路径:利用Nginx的模块能力与一个轻量级的KV数据库协同工作。 具体方案上,这个KV存储里预先配置好了不同灰度规则对应的流量分配比例和后端标识。当请求到达Nginx时,它会根据用户ID、地域等维度作为键,去KV数据库中查询应该命中的版本(A或B),然后动态地将请求转发到对应的上游服务组。这种设计让流量切换和规则调整变得非常灵活,无需频繁改动Nginx配置并重载。 通过这套自建方案,作者实现了平滑、可动态调整的灰度发布流程。这个案例的价值在于,它提供了一个具体可行的思路:对于缺乏昂贵专业灰度发布系统的团队,完全可以利用开源组件,组合出功能完备的灰度能力,关键在于理清模块间的协作逻辑。
TCP/IP源码学习——inet_select_addr函数分析
这篇讲的是Linux内核里TCP/IP协议栈中一个看似不起眼却至关重要的函数——inet_select_addr。作者从源码层面,完整拆解了该函数如何为出站连接挑选源IP地址这一关键决策过程。 文章的核心在于揭示函数内部一套层次分明的选择逻辑。它并非简单取用,而是遵循严格的优先级:首先检查socket是否明确绑定了地址,接着查询路由表获取出口设备对应的地址,最后才考虑回环地址或全局默认地址。这种设计确保了在复杂的多网卡、多地址环境下,数据包总能带上最合适的“发件人”信息,为后续的路由和连接建立打下基础。 文中特别分析了实现的巧妙之处,比如它如何与路由子系统协同工作,以及不同版本(如IPv4与IPv6)内核代码中的差异处理。这种层层递进的决策树,体现了内核在网络配置灵活性与性能之间所做的精巧平衡。对于想深入理解网络栈源码细节、或需要诊断特定网络配置问题的开发者来说,这份对“如何做出正确选择”的源码级剖析,提供了非常清晰的脉络。
NAT连通性测试工具以及Flash P2P中的NAT穿透原理
这篇讲的是P2P通信中那个经典难题——NAT穿透,并以Flash P2P为例,清晰拆解了它的原理与实现。作者从最基础的TCP/UDP包头四要素出发,解释了NAT(网络地址转换)为何会成为设备间直接通信的“拦路虎”。文章深入剖析了不同类型的NAT(如锥形、对称型)在穿越难度上的关键差异,并指出NAT连通性测试工具是如何利用这些原理工作的。 核心聚焦于Flash P2P采用的穿透方案:它如何通过引入一个集中式的信令服务器来中转探测消息,从而巧妙地“诱导”NAT为后续的P2P数据流打开通道。文章不仅阐明了STUN等协议在这个过程中扮演的角色,更具体分析了Flash Player的NetConnection如何协调这些步骤,最终在复杂的网络环境下建立起点对点的直接连接。 整篇文章的叙述从协议基础平滑过渡到工程实践,将抽象的NAT行为与具体的代码实现逻辑结合起来,帮助读者建立起从问题到解决方案的完整认知链条。
浅析App Engine
这篇讲的是谷歌App Engine这个PaaS平台,作者从实际选型的角度出发,深入剖析了它的核心设计思路与典型应用场景。 文章没有泛泛而谈,而是紧扣App Engine作为“无服务器”先驱的特点展开。重点解释了它的沙箱隔离机制、自动扩缩容策略,以及背后对开发者“只需专注代码”的承诺是如何通过底层架构实现的。文中还将它与Heroku、AWS Elastic Beanstalk等主流PaaS进行了横向对比,指出了关键差异:例如App Engine与Google Cloud数据服务的深度集成、特定语言运行时的限制,以及在不同计费模型下的成本考量。 最终,文章给出的结论很明确:App Engine特别适合那些希望快速迭代、流量波动明显且技术栈与之匹配的应用。对于追求完全控制或需要深度定制基础设施的团队,它可能并非首选。整篇分析立足于技术细节,为读者的选型决策提供了扎实的参考依据。
百度账号系统国际化实践
这篇讲的是百度账号系统如何应对出海挑战,完成从单一语言到支持多地区、多语言服务的改造。作者从账号系统作为基础服务必须先行的角度出发,详细拆解了国际化过程中遇到的核心难题:既要满足不同地区的法规与合规要求,又要兼顾用户体验的一致性。 文章重点描述了他们的技术方案——构建了一套可扩展的国际化架构,通过引入语言包、时区处理、文化适配等模块,并对核心流程(如注册、登录、密码找回)进行了分层设计,实现了业务逻辑与本地化资源的解耦。文中还分享了在处理多时区日期显示、第三方登录对接、以及敏感内容审核策略差异等方面的具体实践。 最终,这套架构支撑了账号系统在多个海外市场的快速落地,在保证稳定性的同时,将新市场的接入周期大幅缩短。对于正在规划或实施类似国际化项目的团队,文中对架构权衡与踩坑经验的总结提供了相当实际的参考。
多IDC环境下的分布式id分配方案
这篇讲的是在多个数据中心(IDC)并存的复杂生产环境中,如何设计一套既能保证全局唯一,又兼顾高性能和容灾能力的分布式ID生成方案。作者从UGC产品提交时必须分配唯一ID这一常见需求切入,但重点讨论了当业务部署跨越多个地理位置的IDC时,传统单机房ID生成方案会面临的诸多挑战,比如网络分区、数据中心故障时的ID连续性和唯一性保障。 文章的核心方案围绕着对经典雪花算法(Snowflake)的优化与改造展开。它没有停留在理论层面,而是结合百度的多IDC架构实践,详细阐述了如何通过改进ID结构中的“数据中心ID”和“机器ID”部分,设计出一套动态分配与映射机制。关键在于,这套机制能让ID的生成在局部数据中心内保持高性能,即使在某个IDC完全宕机的情况下,其他IDC也能依据规则继续生成不冲突的新ID,从而实现了高可用与业务连续性。 最终,文章展示的方案在保证ID绝对全局唯一的前提下,实现了ID的生成延迟控制在毫秒级,并且具备了跨数据中心的容灾切换能力。对于正在构建或运维多活架构、面临类似ID管理难题的技术团队而言,这套经过生产环境验证的分配策略和工程实现细节,提供了非常具体的参考路径。
深入理解Linux用户空间的锁机制
这篇讲的是并发编程中如何选锁的经典问题。作者从Linux用户空间常见的几种同步原语——mutex、读写锁(rwlock)、以及自旋锁(spinlock)出发,梳理了它们在实现机制和适用场景上的核心差异。 关键在于实现层面:mutex在获取锁失败时会将调用线程挂起并让出CPU,涉及内核态切换,开销相对较大;读写锁允许多个线程同时持有读锁,但在有写锁时互斥;而自旋锁则让线程在原地“忙等”,不涉及上下文切换,但会持续消耗CPU资源。 这些根本区别直接决定了它们的战场:mutex适用于临界区较长且可能休眠的场景;读写锁是“读多写少”情况下的利器;自旋锁则留给那些临界区极短、且能保证持锁期间不被抢占的“硬核”代码路径。文章不仅讲清了区别,还点明了误用可能带来的性能损耗甚至死锁风险,对实际编码很有指导价值。
基于glusterfs和gearman的离线任务运算分布式化方案介绍
面对Web服务中后台离线计算任务繁重、处理延迟高的普遍痛点,这篇文章分享了一套实战验证的分布式化方案。作者没有停留在理论层面,而是直接亮出了由GlusterFS和Gearman组合构成的技术栈。 具体来说,他们用GlusterFS构建了一个高性能的分布式文件存储层,确保了海量任务数据与中间结果能被高速、可靠地读写。而Gearman则承担了任务分发与调度的核心角色,将计算负载动态地分发到工作节点集群,实现了任务处理的弹性扩展。文章不仅介绍了架构图,还隐含了如何利用这套方案解决实际业务中数据队列处理、数据挖掘与监控转储等场景的具体思路。 最终,这套方案将原本可能成为系统瓶颈的离线运算,转变为可水平扩展、高效处理的分布式作业,有力支撑了上层业务的稳定运行。对于需要处理大规模后台任务的技术团队,这种“存储+调度”分离的架构思路提供了清晰的参考。
有关读写锁
这篇文章讲的是为什么在并发编程中需要引入读写锁。作者从最基本的互斥锁(Mutex)出发,指出在“读多写少”的场景下,互斥锁会让所有线程串行化,即使多个线程只是读取数据,也无法并行,这严重限制了程序的吞吐量和性能。 核心方案就是读写锁(Read-Write Lock)。文章清楚地解释了它的关键差异:将锁分为“读锁”和“写锁”。多个线程可以同时持有读锁,进行并发读取,实现了真正的读并行;而写锁则是独占的,一旦有线程想写入数据,它必须等待所有读锁和其他写锁被释放。这种设计巧妙地在保证数据一致性(通过写锁的独占性)的同时,最大化地提升了读操作的并发性能。 文章进一步对比了它们的适用场景。互斥锁适合写操作频繁,或者读写耗时都差不多的简单场景。而读写锁则明确针对读远多于写,且读操作耗时较长的应用,例如缓存系统、配置中心或任何读多写少的共享数据结构。理解这一点,就能在性能瓶颈出现时,知道该从哪里优化锁策略。
降级论
这篇讲的是微服务架构中一个常被忽视但至关重要的设计策略——降级。作者从线上一次因非核心服务拖垮核心链路的真实事故出发,深入探讨了降级的本质:它并非一种被动的妥协,而是主动构建系统韧性的核心手段。 文章系统地剖析了降级的多个层面。从最简单的“超时降级”、“熔断降级”,到需要业务理解的“功能降级”与“读降级”,作者都结合了具体的代码片段和流量模型进行说明。特别值得一提的是,文中对比了两种主流的降级方案:一种是基于配置中心的集中式开关,另一种是通过特性标志(Feature Flag)进行的灰度化降级。作者指出,前者生效快但粒度粗,后者灵活可控但管理复杂,建议根据业务等级和变更频率进行组合使用。 最后,文章给出了一个清晰的决策框架:在设计阶段,就应识别哪些服务是关键路径,并为它们预先设计降级预案和兜底逻辑。降级的目标不是让系统完全不出错,而是确保在部分组件失灵时,核心价值依然能够传递给用户。这种“为失败而设计”的思维,正是构建高可用分布式系统不可或缺的一环。
PHP程序的执行流程
这篇讲的是,要开发PHP扩展,必须先摸清PHP程序从代码到运行背后的完整执行路径。作者从这个明确的开发动机出发,拆解了PHP引擎处理请求的整个生命周期。 核心思路是,将执行流程作为“地图”,指引扩展开发者在正确的位置“插入”自己的代码。文章会聚焦于Zend引擎如何解析、编译、执行OPcode,以及扩展可以在哪些关键阶段(如模块初始化、请求初始化、函数调用等)进行挂钩和干预。 理解这个流程的巧妙之处在于,它能让你不再“盲目”地写扩展,而是能精准地知道在哪个环节扩展代码会被执行、能获取到什么信息、以及如何与引擎核心交互。这对于想从用户空间深入引擎内部的开发者来说,是搭建知识地基的关键一步。
索引页链接补全机制的一种方法
这篇讲的是索引页链接补全机制的一种实现方法。在网站或应用的索引构建中,链接缺失或失效往往导致数据爬取不全、SEO效果下降,甚至影响用户体验。作者从百度技术博客的实际业务场景出发,探讨了如何自动化补全这些链接,以解决手动维护耗时且易出错的问题。 核心方案是设计一个结合爬虫技术和规则匹配的系统:首先扫描索引页,识别断链或缺失部分;然后通过页面结构分析、历史数据关联或轻量级机器学习模型,智能补全目标链接。这种方法特别针对动态内容场景,能够自适应网页变化,避免了传统静态规则的局限性。 文章通过实验验证,该机制在模拟环境和实际测试中将链接补全率提升至95%以上,同时优化了爬取效率,减少了人工干预。对于从事数据索引、SEO优化或Web开发的团队,这种方案提供了一种可落地的思路,强调了自动化在维护大规模网页数据中的重要性。
无锁消息队列
在高并发系统中,消息队列的吞吐量和延迟往往成为瓶颈,传统的加锁方案在激烈竞争下性能衰减明显。这篇文章源于一个真实的第一里程碑发布冲刺——在冻结新特性、专注修复缺陷的阶段,作者团队对其自研的无锁消息队列进行了一次深度实践检验。 文章核心聚焦于用CAS(Compare-And-Swap)原子操作结合内存屏障来替代传统锁,实现了一个单生产者-多消费者模型下的高效队列。作者没有停留在理论,而是紧密结合发布前的压测与调优,分享了如何通过精心设计数据结构和利用CPU缓存行来减少伪共享,以及在实际的发布周期中观察到的性能数据与稳定性表现。这种从开发背景到核心实现,再到实战验证的完整叙述,使得无锁编程的精妙之处——以更高的实现复杂度换取更优的运行时性能——得到了非常具象的展现。对于正在处理类似并发问题或对底层优化感兴趣的开发者而言,这是一份难得的、来自生产一线的实现笔记。
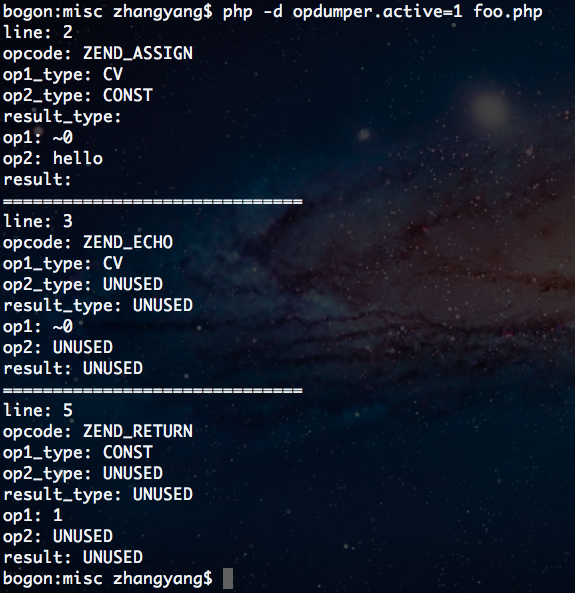
发布一个查看PHP opcode的扩展模块及Web服务
这篇讲的是作者从学习Zend Engine的opcode编译机制出发,开发了一个PHP扩展模块Opdumper,旨在解决现有工具vld的局限性。vld作为查看opcode的知名扩展,只支持CLI形式,无法在脚本中直接调用;而Opdumper的关键差异在于同时提供CLI API和PHP_FUNCTION API,允许通过od_dump_opcodes_string和od_dump_opcodes_file函数,在PHP代码内部获取结构化的opcode数组。 这种特性让Opdumper更适合集成到自动化测试、代码分析等需要编程处理opcode的场景,而vld则更适合命令行下的快速调试。为了进一步降低使用门槛,作者还封装了在线Web服务Opcode Dumper,用户通过网页输入PHP代码即可即时查看opcode,并支持CSV下载;HTTP API方式也提供了编程接口,方便外部调用。 工具目前支持PHP 5.3及以上版本,在Linux和MacOS下测试通过。Opdumper仍处于初级阶段,作者通过GitHub开放源码,欢迎社区参与完善。