用sphinx轻松搞定方便管理的多节点过亿级数据搜索
这篇讲的是作者在面对单节点难以承载、运维繁琐的过亿级数据搜索需求时,如何借助 Sphinx 这个经典工具,搭建出一套既高效又易于管理的分布式搜索方案。 文章并没有停留在 Sphinx 的基础用法上,而是直面真实场景中的痛点:当数据量突破千万并持续增长,单机索引的构建时间、资源消耗和扩展瓶颈都会成为拦路虎。作者的核心思路是“分而治之”——通过设计合理的数据切分与索引路由策略,将海量数据分散到多个节点上进行并行索引与查询。 文中具体拆解了几个关键实现:如何根据业务特点(如按时间或ID范围)制定分片规则,确保查询能精准路由;如何设计主从结构来分担查询压力;以及如何利用 Sphinx 的实时索引功能,平滑处理近实时的数据更新。更重要的是,作者分享了如何通过统一的管理脚本和配置模板,让集群的部署、监控和扩容变得相对简单,避免了“数据虽然分布式了,但管理复杂度却指数级上升”的常见陷阱。 对于正在被大数据量搜索和分布式运维问题困扰的团队来说,这篇文章提供了一套经过验证、可落地的参考架构,它展示的不仅是技术的组合,更是一种化繁为简的工程实践智慧。
在Linux上编译安装PostgreSQL8.3.X
这篇文章讲的是如何在Linux系统中,从源码包开始一步步编译安装PostgreSQL 8.3.x版本。作者没有依赖现成的软件包管理器,而是带读者走完了整个源码编译流程——从解压tarball包开始,包括了配置、编译和安装的完整链路。 对于很多需要特定版本、或者希望对数据库行为有更精细控制的场景,直接从源码构建是一个常见选择。这篇文章的价值在于它把8.3.x这个较早版本的安装细节记录了下来。尽管PostgreSQL已经迭代到更高的版本,但文章里关于处理旧版依赖、配置选项选择,以及可能遇到的编译环境问题的描述,对于维护遗留系统或理解编译原理依然有参考意义。 全文围绕一个具体的命令行操作展开,但隐含了“为什么需要这样做”和“每一步在做什么”的思考。适合那些不满足于简单安装,想深入了解数据库部署底层过程的技术人员。
PostgreSQL与MySQL的区别
这篇讲的是 MySQL 和 PostgreSQL 这两大数据库该如何选择。作者没有罗列枯燥的特性列表,而是直接切入两者最核心的定位差异:MySQL 为了极高的查询速度和易用性,在功能上做出了取舍;而 PostgreSQL 则忠实于 SQL 标准,提供了更丰富、更严谨的功能,比如复杂的查询、完整的约束和更强的扩展性。 文章进一步指出,这种哲学上的不同,直接决定了它们各自最适合的场景。如果你的应用需要处理海量数据、追求极致的读写性能,比如高并发的 Web 应用,MySQL 可能是更直接的选择。反之,如果你从事地理信息系统、数据分析,或者需要处理复杂的数据关系并保证数据的完整性和正确性,PostgreSQL 强大的功能和对标准的坚持会带来巨大优势。最后文章还提到,PostgreSQL 在近年来的版本中性能已有长足进步,而 MySQL 也在通过插件等方式增强功能,但二者底层的设计思想差异依然明确。
Twitter停用Cassandra原因分析
这篇来自Twitter官方工程博客的文章,揭示了一个重要的架构转向:曾经在业界大力推广Cassandra的Twitter,宣布暂停使用它来替代MySQL存储用户Feed。这并非一次技术故障的应对,而是一次深思熟虑的战略调整。 文章从Twitter此前作为Cassandra方向引领者的背景切入,分析了暂停计划的核心动因。关键问题可能在于Cassandra的某些特性(如最终一致性模型或运维复杂度)与Twitter当前Feed系统对强一致性和运维效率的高要求产生了矛盾。文章指出,Twitter的工程师们经过评估,决定暂时回归并优化现有的MySQL架构,以满足业务对稳定性和实时性的迫切需求。 对读者而言,这个案例的价值超越了技术选型本身。它清晰地展示了即使是行业标杆项目,技术决策也必须紧贴业务场景的动态变化,没有一劳永逸的“银弹”。文中对技术权衡的坦诚剖析,为所有在分布式存储领域探索的团队提供了宝贵的现实参考。
Key-Value小数据库tmdb发布:原理和实现
这篇梳理了Key-Value数据库的“前世今生”。从Unix早期的dbm说起,带读者回顾了gdbm、ndbm、sdbm、cdb等一脉相承的经典实现,也提及了功能强大的Berkeley DB与近年备受关注的qdbm。 作者没有止步于罗列,而是指出了一个关键洞察:这类数据库本质上并非传统意义上的“数据库”,其核心价值在于提供一种极其简单、高效的数据存储与读取功能。这种对技术本质的界定,能帮助开发者在项目初期更清晰地判断技术选型的方向。文章虽短,但脉络清晰,点明了这类轻量级存储引擎的定位。
MySQL Query Cache 小结
这篇总结从常见的MySQL Query Cache配置问题和性能影响出发,系统梳理了这项机制的核心原理与适用边界。 文章首先阐明了查询缓存的工作原理:它以SQL语句和结果集的键值对形式缓存数据,并在表发生更新时失效。基于此,作者深入分析了其带来的核心矛盾:对于静态或读密集型表,缓存能极大提升重复查询的性能;然而,在写操作频繁的场景下,频繁的全局失效机制反而会成为显著的性能瓶颈,消耗大量系统资源。 文章不仅解释了原理,还结合了具体场景进行对比。例如,对于同一张表,不同的查询模式和更新频率如何导致截然不同的缓存命中率。最后,文章指出了在MySQL 8.0中该功能已被移除的事实,这进一步强调了理解其本质的重要性——即需要根据业务的实际读写比例来审慎评估其价值,而非盲目启用。 它为开发者提供了一个清晰的决策框架:在启用该特性前,必须仔细衡量业务特征,以避免从性能助力变为性能拖累。
Library cache内部机制详解
这篇文章拆解了Oracle Library Cache的内部工作机制。作者从Library Cache必须解决的三个核心难题入手:如何快速定位海量对象、如何管理复杂的依赖关系、如何进行高效的并发控制。 文章揭示了Oracle的精巧设计:通过Hash Bucket结构实现对象的快速寻址;利用Library Cache Object中的dependency table维护对象间的依赖链,确保一个对象失效时其依赖者能被迅速级联置为失效;并发控制则由Library cache lock和pin机制共同承担,前者在对象句柄上管理进程间访问,后者在数据堆上防止内存内容被意外换出,两者协同实现了读写分离与保护。 文中特别剖析了lock与pin在对象修改和访问时的不同模式,并结合实例说明了依赖对象变更时可能引发的lock/pin等待阻塞问题及其后续版本的优化思路。对于想深入理解Oracle共享内存结构、性能调优或解决硬解析相关故障的DBA和开发者来说,这篇文章对原理的阐述十分清晰透彻。
mysql 主从同步原理
这篇讲的是 MySQL 主从复制背后的工作原理。作者从主从架构的基本形态切入,详细拆解了从主库将数据变更传递到从库的完整过程。核心在于二进制日志(binlog)的写入、从库 I/O 线程的拉取与写入中继日志(relay log),以及从库 SQL 线程的重放执行。文章还对比了基于语句(Statement)与基于行(Row)两种复制模式的差异,指出它们在数据一致性与网络负载上的不同权衡。 更进一步,文章探讨了复制延迟的常见成因,比如大事务、从库性能瓶颈或网络抖动,并提到了使用 GTID(全局事务标识符)来简化故障恢复和拓扑管理的方案。这些细节让读者不仅能理解“怎么做”,还能明白“为什么”以及在实际运维中需要关注什么。 对于需要搭建或维护高可用、读写分离 MySQL 环境的工程师来说,这篇梳理提供了清晰的底层逻辑地图,帮助在设计和排查问题时抓住关键节点。
一条SQL引发的对order by的思考
这篇讲的是,作者从一条实际工作中遇到的、看似简单的SQL查询出发,却意外揭开了MySQL `ORDER BY`机制中不少容易被忽略的深层细节。 文章聚焦于一个核心问题:为什么某些查询在加了`ORDER BY`后,性能会急剧下降甚至导致全表扫描?作者没有停留在表面优化,而是深入到底层,对比了`InnoDB`与`MyISAM`存储引擎在处理`ORDER BY`时的不同策略,特别是利用索引的能力差异。同时,文章还拆解了当排序字段与查询条件字段不一致,或涉及多列排序、不同数据类型时,优化器可能做出的迥异选择。 通过对具体案例的剖析,作者清晰地指出:`ORDER BY`并非一个简单的“结果排序”指令,它与存储引擎的聚簇索引结构、优化器的成本评估紧密相关。理解这些关键差异,才能真正预判SQL的性能,而不是依赖“经验法则”。对于常写SQL的开发者而言,文中对不同场景适用性的分析,提供了一个非常实用的排查思路。
54chen解读NoSQL技术代表之作Dynamo
这篇讲的是 Amazon 传奇系统 Dynamo 的深度技术复盘。作者54chen没有停留在概念层面,而是深入剖析了 Dynamo 如何用一套精巧的设计,在那个年代就解决了高可用与最终一致性的核心矛盾。 他从 Dynamo 的去中心化架构出发,拆解了一致性哈希如何实现数据均匀分布与动态扩缩容,向量时钟如何处理并发写冲突,以及 Gossip 协议如何维护成员状态。这些实现细节揭示了 Dynamo 为了达到“永远可写”这一极端目标,在工程上所做的权衡与创新。 文章不止于描述原理,更结合作者的理解,探讨了这些设计决策背后的思想。比如,为什么 Dynamo 放弃强一致性而拥抱 AP 模型?它所面临的运维挑战是什么?这些思考帮助读者理解技术选择背后的场景约束。 最终,这篇解读清晰地勾勒出 Dynamo 作为奠基性系统的完整面貌。它不仅是 NoSQL 的一次重要实践,其分散化、面向可用性的设计哲学,也持续影响着后来分布式系统的设计思路。

Oracle数据库性能模型
这篇讲的是如何为Oracle数据库建立一个有效的性能模型。作者从DBA的日常挑战出发,探讨如何量化应用对数据库的影响,从而预测风险、保障稳定性。 文章的核心观点是以响应时间为性能评价的中心。它将数据库的响应时间分解为“服务时间”(CPU时间)和“等待时间”,并重点分析了Oracle数据库的时间模型。通过实际AWR报告中的数据示例,文章清晰地展示了“DB time”的构成,例如“sql execute elapsed time”和“DB CPU”的占比情况,让抽象模型变得具体可感。 在深入分析响应时间构成时,文章指出在单机环境下,CPU和IO是决定性能的两大关键要素,而内存与网络的延迟相比之下可以忽略。文中的AWR片段显示,“DB CPU”占到了DB time的87.21%,而“User I/O”等待占了9.12%,这种量化的视角为性能分析提供了明确方向。 最终,作者表明,通过建立这样的时间模型并拆解DB time,DBA能够将性能管理从模糊的感觉提升到可测量、可评估的层面,这正是应用DBA工作的核心价值。
Cassandra运维之道
这篇讲的是Cassandra运维的入门与规划。作者从一个现实痛点切入:相比Oracle、MySQL等传统关系数据库,很多NoSQL数据库的运维文档相对匮乏,而Cassandra在这方面算是例外,能找到不少参考资料。 他基于网上现有材料,并结合自己对部分源码的阅读理解,整理出了这份Cassandra运维的普及性资料。作者坦诚,内容可能还存在一些理解偏差,并将其定义为version 0.1,更像是一个思考的起点和框架。 文章的重点不止于知识梳理,更在于一个清晰的后续规划:随着实际业务开始采用Cassandra,作者计划将理论与未来的运维实践相结合,逐步沉淀、修正,目标是形成一份更具操作性的最佳实践手册。对于正打算或刚开始接触Cassandra运维的读者来说,这份坦诚的初步总结和进阶路径,提供了一个不错的参考方向。
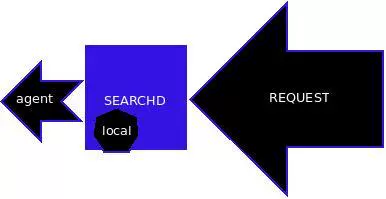
利用Sphinx实现实时全文检索
这篇讲的是如何用Sphinx搭建实时全文检索系统。作者指出,在Sphinx 1.10.1版本之前,要实现“实时”更新索引比较麻烦,通常得靠主索引加增量索引的组合方案,但这只是“准实时”。现在,Sphinx终于原生支持real-time index了。 文章的核心价值在于,它具体展示了如何利用这个新特性,来构建一个“按需索引”系统。作者通过查阅SVN中的文档,一步步说明了配置和使用方法。这意味着你可以更灵活地控制索引更新的时机和方式,让搜索结果的实时性得到真正提升,而不必再依赖那种较为复杂的增量索引合并策略。 对于之前在搜索实时性上受困于Sphinx旧版本限制的开发者来说,这篇文章给出了一个直接且有效的升级路径。
Oracle Index Merge 与 and_equal 的变迁
and_equal作为Oracle的一种索引合并操作,经历了从推荐使用到逐渐淡出的变迁。这篇讲的就是这段“历史”背后的技术细节。 文章详细分析了and_equal的工作原理:它能够将多个单列索引的结果集直接合并,从而避免回表。你可以通过Hints语法强制使用它,但有限制——最少指定两个索引,最多五个,并且作者附上了典型的执行计划来展示其运作方式。 更重要的是,作者梳理了它在不同Oracle版本中的地位变化,以及在现代执行计划中,基于成本的优化器(CBO)更倾向于哪种路径选择。这对于理解优化器的行为模式很有帮助。 对于需要处理复杂查询的DBA或开发来说,理解这段历史有助于在调优时判断,是否值得尝试这种“复古”的手段,还是应该完全信任优化器的现代决策。
Cassandra之Token
作者在等待世界杯开幕的间隙,阅读了Cassandra中关于分布式哈希表(DHT)的核心源码,这篇笔记便由此而来。他从生产系统运维的实际关切切入,探讨了Cassandra中数据如何通过Token机制被可靠且均匀地分布到集群的各个节点上。 文章深入Cassandra的源码层面,解析了Token的生成与分配逻辑。其核心思路是为每个节点分配一个唯一的Token值(通常是一个巨大的整数),这个值定义了该节点在环形数据空间中的位置。所有数据也通过哈希函数映射为Token值,并顺时针查找到达的第一个节点进行存储,由此构成了“一致性哈希”的基础。作者在代码中特别关注了Token的计算算法与节点加入、退出时的数据迁移过程,揭示了系统如何通过巧妙的设计,在保证数据高可用的同时,尽可能实现负载的均衡。 这不仅仅是理论推导,更是对生产环境中数据分布策略的细致考量。理解Token机制,就是理解Cassandra如何在大规模集群中实现优雅扩展和故障容忍的根基。
mysql 查看服务器端配置记得加global
这篇文章源于作者处理的一个实际问题:产品人员反馈新手卡录入后台出现报错,紧急寻求技术支持。作者从这个报错入手,一步步拆解排查过程,最终指向了一个容易被忽略的MySQL配置细节。 在排查中,作者发现问题可能出在数据库配置查看的环节。MySQL中,使用SHOW VARIABLES命令默认只返回当前会话的变量值,而非服务器全局配置。这意味着,如果在检查服务器端设置(比如字符集、连接数限制)时没有指定global参数,看到的只是临时会话配置,与全局实际值不符,从而导致业务逻辑异常或配置误解。根因就是,开发者在查看配置时习惯性地省略了global关键字,误将局部设置当作全局状态处理。解决方法很直接:在命令中显式加上global,例如执行SHOW GLOBAL VARIABLES LIKE '变量名';,确保获取的是持久化的服务器级配置。文章还可能延伸到如何区分会话与全局变量的实际应用场景,帮助读者在类似问题中快速定位。 这个提醒看似微小,却在实际运维和开发中频繁引发隐蔽的坑。作者通过一个具体案例,强调了细节严谨性对系统稳定性的价值,尤其在快速迭代的环境下,多敲一个关键字就能避免不必要的故障排查时间。
过滤部分字段重复的数据
这篇讲的是在处理数据库查询时,一个看似简单却很实际的需求:如何过滤仅部分字段重复的记录。很多开发者习惯性地使用 `SELECT DISTINCT`,但它判断的是整行数据的唯一性。文章正是从这个常见的认知起点出发,点明了当业务要求基于特定字段(如姓名、电话)来去重,而允许其他字段(如ID、创建时间)不同时,`DISTINCT` 就无能为力了。 作者接着对比了两种关键的解决方案。一种是传统的 `GROUP BY` 结合聚合函数(如 `MAX`、`MIN`)来选取每组中的特定记录,这适用于明确需要保留哪条数据的场景。另一种是更现代的窗口函数方法(如 `ROW_NUMBER()`),它能为每组重复数据按规则排序并打上编号,再筛选编号为1的记录,这种方式在逻辑上更灵活,尤其适合复杂排序或需要保留“最新”、“第一条”等场景。 文章没有停留在语法层面,而是强调了选择哪种方案背后的思考:你需要明确“去重”的业务标准究竟是什么,以及对性能和结果完整性的要求。对于想要精准控制去重逻辑的开发者来说,理清 `DISTINCT`、`GROUP BY` 和窗口函数之间的差异与适用边界,是写出高效且正确查询的关键一步。
DBA工作初体验之死里逃生
这篇讲的是作者作为职场新人,初入DBA岗位时经历的一场“生死时速”般的亲历记。 文章以一段端午节的回忆开篇,温馨的家常味道与即将到来的紧张工作形成鲜明对比。真正的挑战发生在节假日前夕——一个本该轻松收尾的时刻,线上突发故障。作者详细描述了面对警报时的心慌、排查过程中的辗转反侧,以及最终定位并解决问题的全过程。这不仅是一次技术操作的记录,更是一次对新手DBA心理承压能力的严峻考验。 故事的高潮在于“死里逃生”后的反思:如何避免因疏忽或经验不足导致的险情?作者分享了自己从这次事件中总结出的关键认知与工作习惯的调整。对于刚入行或正面临类似压力的技术人员而言,这份从慌乱到从容的切身成长轨迹,或许比单纯的技术点更能带来共鸣与启发。
MyISAM和InnoDB两种“引擎”的区别
这篇讲的是MySQL里最经典的两种存储引擎——MyISAM和InnoDB的对比。作者从“存储引擎到底是什么”这个基础概念切入,直接拆解了两者在底层设计上的核心差异。关键区别包括事务支持、锁的粒度(表锁 vs 行锁)、外键约束以及崩溃恢复能力。文章还特别提到了一个容易被忽略的细节:在旧版MySQL中,MyISAM其实是默认引擎,而InnoDB后来居上成为主流,这背后是业务对数据安全性和并发性能要求不断提升的体现。 具体到场景选择,文章给出了很清晰的结论:如果你的应用是读多写少、对事务完整性要求不高(比如日志或统计表),MyISAM的简单高效可能更有优势;但凡是涉及订单、用户等需要事务、行级锁和高并发写入的核心业务,InnoDB几乎是必选项。理解这些差异,能帮助开发者在设计数据库表时做出更合理的技术选型。
oracle 子查询写法
这篇讲的是Oracle数据库中子查询的几种典型写法与适用场景。作者从实际查询需求出发,梳理了IN子查询、EXISTS子查询、以及从FROM子句中提取子查询作为临时表的不同用法。 文章重点对比了IN与EXISTS在执行逻辑和性能上的差异:IN通常适合子查询结果集较小的场景,而EXISTS在外部表较小时效率更优。通过简单的执行计划对比,作者展示了优化器对两种写法的不同处理方式。此外,文章还提及了“标量子查询”在SELECT列表中的巧用,以及如何避免“笛卡尔积”这类常见陷阱。 对于需要编写复杂查询的开发者或DBA,这篇文章给出了清晰的决策路径——根据数据量、索引情况和业务逻辑来选择最合适的子查询形式,而不仅仅是依赖语法习惯。结尾处提到的“先在小数据集上测试”这一建议,也体现了工程实践中的务实态度。