使用python/casperjs编写终极爬虫-客户端App的抓取
这篇讲的是在JavaScript动态渲染盛行的今天,如何有效抓取那些传统爬虫无能为力的“客户端App”型网页。作者以自动化获取Google Adwords关键词搜索量为实际案例,详细对比了两种实现路径。 文章首先回顾了经典的Selenium WebDriver方案。它像一位稳重的老兵,功能全面,能操控真实浏览器。作者分享了在无图形界面的服务器上配置它的技巧,并演示了如何通过分析页面结构、模拟登录、处理动态等待(如`implicitly_wait`)来一步步完成任务,最后用XPath提取出结果。方案虽可靠,但步骤相对繁琐。 随后,作者转向更现代的JavaScript Headless方案,重点介绍了CasperJS(基于PhantomJS)。这条路子轻快灵活,执行速度可达Selenium的三倍,代码也更直观——可以直接在浏览器控制台逻辑下编写。作者用它演示了几乎相同的功能,但指出CasperJS在进程间通信(IPC)方面存在局限。 最终,文章提供了一个完整的CasperJS爬虫脚本示例,读者替换账号即可运行。对于需要应对复杂JavaScript渲染的爬虫场景,这篇文章提供了从传统到现代的清晰路线图和实用代码。
服务器间同步/镜像/备份配置备忘录
这篇文章讲的是作者在从VPS迁移到独立服务器后,面对没有现成备份的困境,如何一步步摸索并比较各种文件同步方案,以实现可靠、实时备份的实战经历。 作者首先解决备份服务器的选型,找到了高性价比的大容量VPS。核心的挑战在于文件同步:基础的rsync配合cron定时任务虽然方便,但面对海量小文件和对“实时性”的追求,显得力不从心。于是,作者依次尝试了基于inotify机制的inotify-tools和sersync。文章详细记录了每一步的配置和遇到的真实问题:inotify-tools的过滤规则在实践中不顺手,日志混乱;而国产的sersync虽然整合了failover机制,看似更顺手,却暴露了多线程下大文件同步不完整、资源占用高等新问题,且文档和日志功能缺失。 最终,作者回归到inotify-tools,通过编写自定义脚本来解决文件过滤问题,找到了更可控的解决方案。整篇文章像一份技术人的踩坑笔记,清晰地对比了rsync、inotify-tools、sersync在功能、易用性、稳定性和资源消耗方面的差异,其价值不在于给出一个标准答案,而是为读者提供了在选择实时同步方案时,需要考量哪些实际维度——是稳定性、资源效率,还是配置的简洁性。
使用python/casperjs编写终极爬虫-客户端App的抓取
这篇讲的是在现代动态网页和移动应用面前,传统爬虫如何“进化”的实战指南。作者从抓取Google关键词工具这个真实需求出发,指出如今大量数据藏在通过Ajax动态加载、JavaScript混淆渲染的客户端App后面,用常规方法根本拿不到内容。 文章核心对比了两种让浏览器“动起来”再抓取的方案。先是详细推演了如何用Selenium WebDriver在无图形界面的服务器上,模拟用户登录、等待JavaScript渲染完成,最终提取到数据,并给出了完整代码。随后,文章转向更轻量的JavaScript原生方案,介绍了如何用CasperJS(基于PhantomJS的无头浏览器)来实现相同功能,并指出其速度约为Selenium的三倍,代码也更直观,但同时也坦诚了它在系统通信能力上的局限。 作者不仅给出了“怎么做”,更解释了“为什么”——为什么需要等待特定元素出现,如何解析混淆后的结果。最后,文章将这套方法论升华为“终极爬虫”思路:用真实的浏览器引擎去执行JavaScript,从而绕过所有复杂的反爬机制。对于需要处理现代富JavaScript应用数据抓取的开发者,这提供了非常直接且可复现的路径。
使用python爬虫抓站的一些技巧总结:进阶篇
这篇讲的是Python爬虫技巧的进阶实战。作者坦言,之前的基础总结停留在“只是能用”的层面,而这次的目标是实现从“能用”到“用得省事省心”的跨越。这意味着将介绍一系列能让爬虫更高效、更稳定、更易维护的实践方法。 文章并非罗列零散技巧,而是围绕着“提升质量”这一核心,分享从初级到进阶的思维转变与具体优化。内容预计会触及如何更智能地处理页面解析、应对反爬机制、管理请求与数据存储等常见痛点,帮助开发者构建更稳健的抓取流程。对于已经能写基本爬虫、但希望代码质量和运行效率更上一层楼的开发者来说,这些从实践中总结出的经验,能让代码不仅跑得通,还能跑得稳、跑得久。
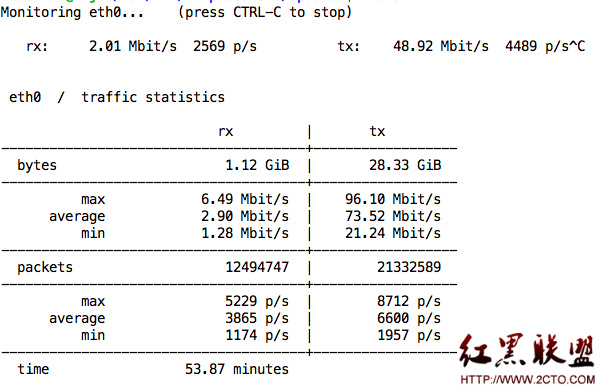
服务器间同步/镜像/备份配置备忘录
这篇讲的是作者从VPS转向独立服务器后,面对备份策略完全自主的新挑战时,如何梳理和记录自己的一系列配置实践。文章的核心出发点很实际:经济型VPS虽然简陋,但服务商通常会提供基础的RAID1+0硬盘冗余,硬件故障尚有一线希望;而独立服务器出于成本考虑可能没有RAID保护,一旦疏于备份,数据风险便完全由自己承担。 作者并没有展开一个宏大的备份架构,而是像一份贴心的备忘录,记录了自己在“服务器间同步、镜像与备份”这个具体任务中,反复搜索、尝试并最终固定下来的一系列配置方案。这些内容包括具体的工具选择、配置命令和注意事项,旨在为自己省去日后重复折腾的麻烦。对于同样从托管服务转向自管理服务器的技术人员,尤其是那些预算有限、需要亲自上手维护数据安全的读者来说,这些凝聚了踩坑经验的配置笔记,提供了一份可以直接参考或借鉴的实战清单,避免了从零开始的盲目摸索。
防DDoS脚本 in python
面对网站因意外流量暴增而陷入的“人肉DDoS”困境,作者分享了一个用Python编写的自动化防御脚本。当100Mbps带宽被持续占满、服务器响应严重迟滞时,作者没有选择被动承受。该脚本的核心思路是通过定期解析系统连接数,对同一IP超过阈值的并发连接使用iptables进行自动封禁,并利用SQLite数据库记录封禁时间,实现24小时后自动解封,形成了一个简单的闭环管理。 作者坦诚地记录了初期效果:脚本单独运行时,封禁了500多个IP却依然无法缓解流量压力。这揭示了此类“笨蛋式”抓取或下载导致的流量洪水,其源头分散且顽固,单一维度的拦截难以根治。真正的转折点出现在结合了脚本与架构调整——将部分站点迁移至另一服务器分流之后,问题才得以平息。这个实战案例提醒我们,应对异常流量需要监控、拦截与架构弹性等多重手段的组合,而脚本正是其中快速响应的第一道自动化防线。
一年米国VPS使用经验总结
这篇总结是作者在使用了多家美国VPS服务商后,对自己过去一年体验的全面梳理。文章没有停留在单一产品的测评,而是横向对比了不同服务商在配置、网络线路、稳定性及性价比上的实际表现。 从内容看,作者从建站、开发到日常使用的多个维度,记录了各款VPS的“脾气”与长板。比如哪家的线路对国内访问更友好,哪款在突发流量下更抗压,以及在不同预算下如何做出权衡。这些基于长期、多场景使用得出的经验,构成了文章的核心干货。 对于正在挑选或刚刚接触海外VPS的读者,这份汇总相当于一份“避坑”与“优选”参考。它跳开了营销宣传的套路,直接呈现了真实运维中的细微差别——哪些标称的“高性能”是实打实的,哪些低价套餐则存在隐性门槛。这种基于实践的横向对比,能帮助读者更快地锁定与自己需求匹配的选项。
网站广告投放策略研究 (一) 轮播以及效用最大化
这篇关于网站广告投放策略的研究,从互联网广告的基础类型科普切入,梳理了CPC、CPM、CPA、CPS和CPV等常见模式,明确了它们各自的计费方式和应用场景。文章聚焦于轮播广告这一具体策略,探讨如何在动态展示中最大化广告效用,核心问题在于平衡
使用python爬虫抓站的一些技巧总结:进阶篇
作者从自身爬虫技术的成长历程出发,坦承早期总结的“基础篇”仅达到“能用”的程度。这篇进阶篇正是为了系统性地将爬虫实践提升到“省事省心”的层次。文章不满足于功能实现,而是深入探讨如何让爬虫代码更健壮、更高效、更易维护。 具体技巧方面,作者分享了应对反爬机制的实战心得。例如,如何更优雅地处理验证码(如使用打码平台或OCR识别),如何通过设置合理的请求头、使用代理IP池来规避封禁,以及如何应用多线程或异步IO来显著提升抓取效率。这些内容直击爬虫开发者在实际项目中必然遇到的痛点,提供的不是理论,而是经过验证的“怎么做更好”的解决方案。 总的来说,这是一篇承上启下的经验之谈,它将零散的爬虫知识点串联成更系统的工作流。对于已经具备Python爬虫基础,希望优化代码质量与运行效率的开发者来说,文中这些关于健壮性、速度与维护性的具体建议,能带来切实的提升。
防DDoS脚本 in python
这篇讲的是,一个Python项目如何应对突如其来的DDoS攻击。作者直言不讳地指出,被攻击并非偶然,而是因为另一场“VC悲剧”后,大量流量意外涌入了这个名为simplecd的服务。 面对这种突发流量导致的崩溃风险,作者没有选择复杂的防御系统,而是动手写了一个轻量级的Python脚本。从描述来看,这个脚本的核心思路应该是实时监控接入的请求,通过分析访问频率、来源IP特征等数据,快速识别并拦截异常流量,从而在服务器资源被耗尽可能之前,就将恶意的DDoS请求过滤掉。这种解决方案特别适合中小型项目在紧急情况下的快速部署,成本低且见效快。 文章没有停留在理论层面,而是直接分享了从发现问题、分析根因到动手实现防御脚本的完整过程。对于那些可能同样面临类似流量压力或资源有限的开发者来说,这种直接、可复现的实战经验,比一套庞大的安全理论体系更具参考价值。
服务器间同步/镜像/备份配置备忘录
这篇备忘录从实际运维中“服务器间文件同步”这一高频需求出发,讨论了使用 `rsync` 进行文件同步的几种主要方式。作者对比了通过直连、SSH 隧道以及搭建 Rsync daemon 这三种连接方式在认证、安全性和适用场景上的区别,并明确指出了各自的优缺点。 文章的重点在于提供一份清晰、可操作的配置参考。它详细列举了 `rsyncd.conf` 配置文件中的关键参数,比如用于认证的 `auth users` 和 `secrets file`,控制访问的 `hosts allow/deny`,以及影响传输性能的 `timeout` 和 `max connections` 等选项,并解释了它们的作用。对于需要快速搭建或优化 rsync 同步流程的技术人员来说,这份备忘录直接给出了经过验证的配置思路和参数细节,省去了反复查阅文档的时间。
用javascript来摧毁你所访问的网站
这篇讲的是,JavaScript 这本用于构建网页的“无害”脚本语言,如何能在客户端被武器化,对网站自身发起攻击。作者没有泛泛而谈,而是具体展示了多种攻击向量:比如,诱导用户浏览器执行恶意代码,来对第三方或目标网站发起分布式拒绝服务攻击(DDoS);利用精心构造的脚本,从同源页面中窃取用户凭证或敏感数据;甚至通过注入恶意脚本,破坏页面的完整性和功能,实现界面劫持。 文章的核心观点在于揭示了一个常被忽视的盲区:传统防御侧重于服务端和网络层,而客户端JavaScript环境却成了防御薄弱的新攻击面。其巧妙之处在于,这些攻击往往利用了合法的浏览器特性和用户信任,使得检测和拦截变得更加困难。 对于开发者和安全工程师而言,这是一份重要的警示。它提醒我们,不能只关注后端安全,必须对前端代码进行严格的审计和限制,警惕第三方脚本的风险,并考虑实施如内容安全策略(CSP)等机制来缓解此类攻击。
30分钟3300%性能提升――python+memcached网页优化小记
这篇讲的是作者在对比Python与PHP网页渲染速度时,意外挖到的一个性能优化“土办法”。 作者之前苦于不知如何系统性地优化网页性能,直到他借鉴了Discuz等PHP应用的做法:直接在生成的网页里打印出“本页面生成时间”。这个看似简单、甚至有些“白痴”的改动,却让性能调优变得异常直观。通过反复刷新页面并观察时间变化,什么操作导致了瓶颈、如何调整能见效,都一目了然。 文章核心就围绕这个发现展开。作者从自己一次无心的性能对比实验出发,记录了如何将这个“笨”方法付诸实践,并最终实现了高达3300%的性能提升(耗时从数秒降至零点几秒)。整个过程强调的是:有时候最有效的优化手段,未必是复杂的理论或高深的框架,而可能只是一个能让你“看见”问题的具体指标。 这种“让瓶颈可视化”的思路,对很多陷入优化迷雾的开发者来说,或许是个值得借鉴的起点。它跳出了单纯讨论代码效率的范畴,提供了一种更工程化、更直觉的问题定位方法。
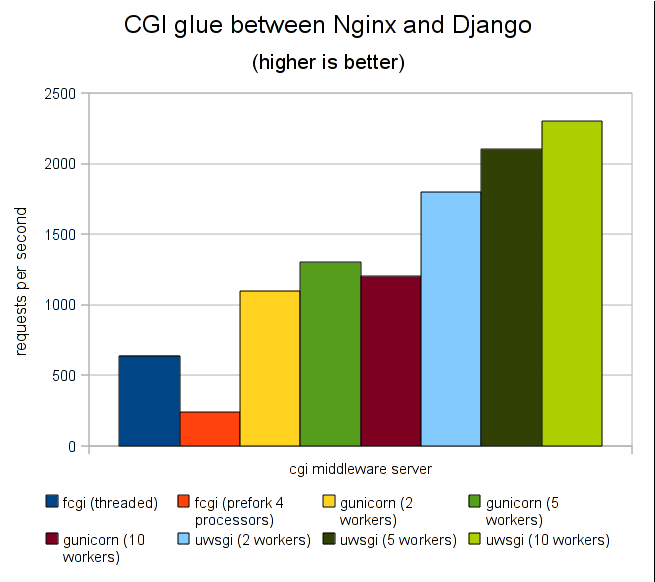
配置Nginx+uwsgi更方便地部署python应用
这篇指南详细讲解了如何通过结合Nginx和uWSGI,来搭建一个更专业、高效的Python Web应用生产环境。作者首先指出了直接使用Flask或Django内置服务器在并发和稳定性上的不足,从而引出了这个经典的“反向代理 + 应用服务器”组合。 文章的核心是手把手配置过程。它首先解释了Nginx作为前端服务器负责处理高并发连接和静态文件请求,而uWSGI则作为后端应用服务器,通过WSGI协议与Python应用(如Flask或Django)通信。文中提供了从安装到详细配置的完整步骤,包括如何为应用编写uWSGI的配置文件(.ini)、在Nginx中设置反向代理,以及如何通过进程管理工具(如systemd或supervisor)来可靠地管理uWSGI服务。 除了基础配置,文章还触及了一些实践要点,比如如何设置日志路径与级别、处理静态文件请求以减轻应用负担,以及调整Worker进程数以适配不同负载。采用这种部署方式,最终能让你的应用获得更好的性能、更清晰的职责分离和更稳定的运行状态。
SQL vs NoSQL:数据库并发写入性能比拼
这篇讲的是在并发写入场景下,SQL与NoSQL数据库的性能差异。作者以典型的MySQL(SQL代表)和MongoDB(文档型NoSQL代表)为例,搭建了测试环境,模拟了高并发的写入请求。 测试数据揭示了显著的性能鸿沟。在同等硬件和并发压力下,MongoDB的写入吞吐量常常能高出MySQL一个数量级。这并非简单的“谁更快”,而是源于根本的设计哲学差异。文章深入剖析了背后的原因:MySQL使用B+树索引、行级锁和严格的事务保证,每一次写入都伴随着复杂的检查与持久化流程;而MongoDB的内存映射文件、集合级锁和更宽松的一致性模型,使其能以更“轻”的方式处理大量写入。 当然,性能不是唯一标尺。文章也指出了各自的主战场:当你需要强一致性、复杂事务关联和丰富的SQL生态时,MySQL依然是可靠的选择;而若应用场景追求极高的写入吞吐,且能接受最终一致性或灵活的数据模型,NoSQL的优势便不可忽视。 最后的结论很实际:选择取决于业务需求。文章通过实测数据和原理剖析,帮你厘清了两者在并发写入这一关键维度上的真实能力边界。