Linux内核文件系统挂载分析
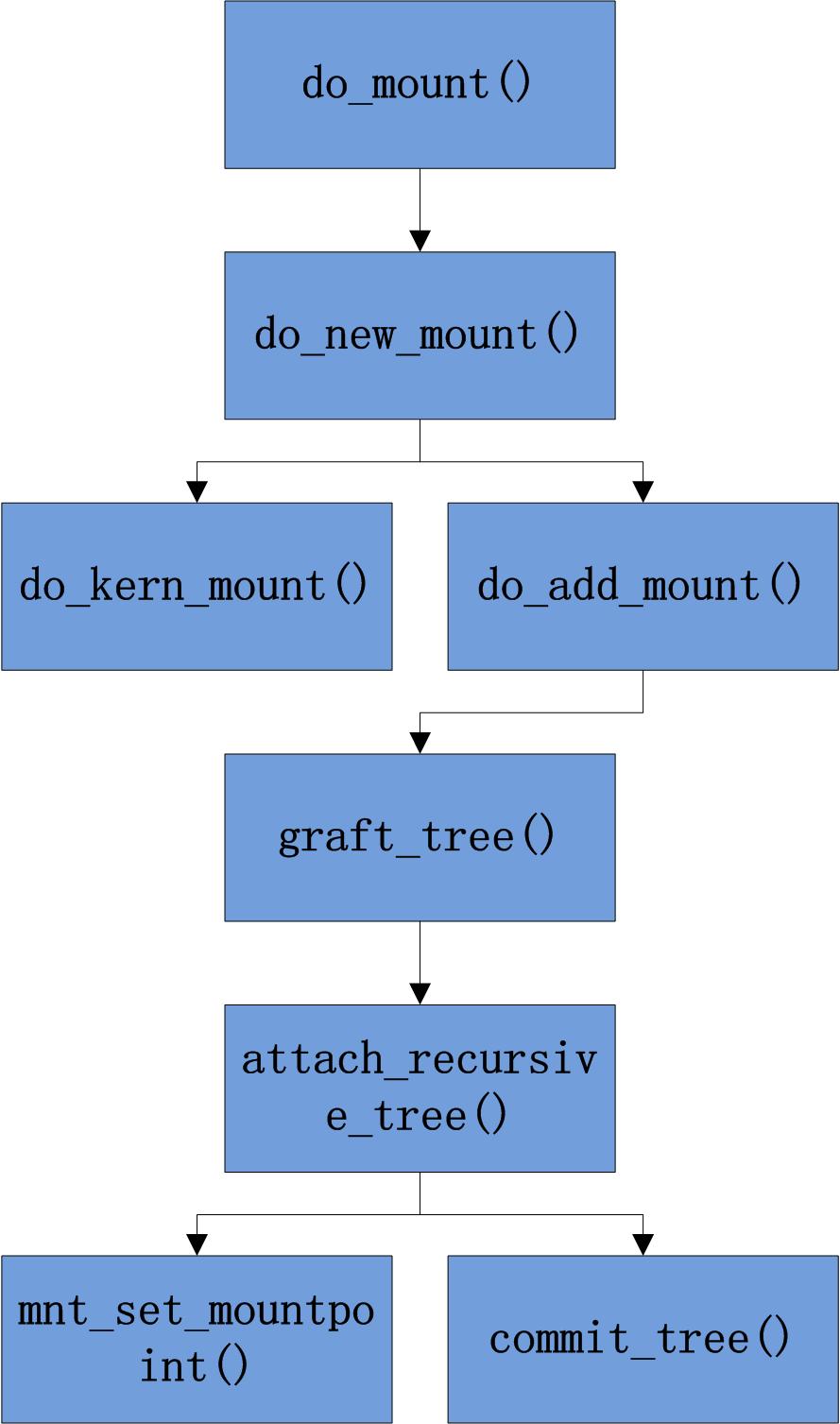
作者从mount系统调用的实现过程入手,聚焦于Linux 3.2.0内核,拆解文件系统挂载的底层机制。文章首先厘清了两个核心数据结构:每个挂载的文件系统都对应一个vfsmount,它维护着文件系统在哈希表、父子关系链表以及名字空间中的位置;path结构则封装了目标挂载点与父文件系统的关联。 核心分析围绕一连串的函数调用展开:系统调用服务例程将参数复制进内核后,便交由do_mount处理。它通过kern_path定位挂载点,随后分发至do_new_mount进行常规挂载。后者的关键步骤是通过do_kern_mount获取源文件系统的vfsmount,并经由do_add_mount执行合法性检查,最终调用graft_tree进行装载。 装载的精髓体现在attach_recursive_mnt中。该函数建立父子映射:让子文件系统的vfsmount指向父vfsmount,并链接到父系统中的挂载点dentry。最后的commit_tree则将这一切“落地”:把新vfsmount置入正确的名字空间链表、全局哈希表以及父文件系统的子文件系统列表中。整个过程清晰地揭示,挂载在内核层面的本质,正是将源文件系统的vfsmount结构以严格的层级关系,嫁接到目标文件系统的目录树之中。
通过call_usermodehelper()在内核态执行用户程序
这篇讲的是如何在 Linux 内核中“跨界”执行用户空间的程序。作者从内核开发者常遇到的需求出发,介绍了 `call_usermodehelper()` 这个内核API。 文章指出了它的核心作用:让运行在内核态的代码(比如模块或驱动)能够主动启动并执行一个用户空间的可执行文件或系统命令,就像在 shell 里敲命令一样。作者还提到了一个关键的实现细节:这个函数最终会调用内核的 `do_execve()`,这和用户态的 `execve()` 系统调用在底层“殊途同归”,但调用路径和上下文完全不同。 为了说明如何使用,文章给出了一个加载函数的代码片段示例,演示了调用该API的基本结构。对于需要在内核逻辑中动态触发外部脚本或工具进行日志收集、环境配置等场景,这个接口提供了一条直接通道,理解它有助于编写更灵活的内核模块。
Linux内核中通过文件描述符获取绝对路径
这篇深入探讨了一个内核开发中具体且实用的场景:当你只知道一个进程的pid和它持有的某个文件描述符fd时,如何在内核里一步步找回该文件在磁盘上的绝对路径。 文章的核心思路是沿着内核的数据结构进行“导航”。它首先通过pid找到进程的task_struct,再从中取出进程打开的文件表files_struct。以fd为索引,就能定位到代表这个文件的内核结构体file。接下来是最关键的两步:从file中获取封装了dentry(目录项)和挂载点信息的path结构,并最终调用内核函数`d_path()`,将这一系列结构解析为人类可读的绝对路径字符串。 整个实现过程清晰展示了Linux内核管理进程与文件系统的精巧层次。这种从进程到文件、再到路径的逆向追踪能力,对于调试内核模块、进行系统监控或编写特定内核功能来说,是一项非常基础且重要的技术。
文件操作函数在VFS层的实现
这是一篇源码分析/实现类的文章,深入内核代码,拆解了open、read、write和close这四个基础文件操作函数在VFS(虚拟文件系统)层的具体实现路径。 文章开篇点明VFS作为统一接口的承上启下作用,随后逐一攻破。例如,对于open,它聚焦于do_sys_open函数,展示了如何从用户空间获取路径、分配文件描述符,到核心的do_filp_open如何查找/创建inode并构建file对象的完整过程。对于read和write,文章对比了它们近乎对称的实现结构:通过fget_light获取file对象,调用vfs_read/vfs_write执行操作,再更新文件偏移量。其中特别剖析了vfs_read如何根据file操作函数集(f_op)中是否存在自定义的read钩子来决定调用驱动层函数还是内核默认的同步读函数,清晰体现了VFS的灵活性与抽象层设计。 最后,close的实现则强调了资源的清理与释放,如调用flush写回缓存、释放锁和file对象。整篇文章通过关键代码段的解析,清晰勾勒出一个系统调用从用户空间下发后,如何在内核VFS层被逐步拆解、调度,最终落地到具体文件系统操作的过程,巧妙之处在于VFS如何通过一套统一的数据结构(如file、inode、f_op函数指针集)和调度逻辑来屏蔽底层差异,为上层提供一致的体验。对于想理解Linux文件I/O内核实现的开发者而言,这篇代码级的走查非常直接且具参考价值。
Linux下访问文件的基本模式
这篇讲的是Linux内核中几种常见的文件访问方式,作者从底层机制出发,对比了普通模式、同步模式、直接I/O、异步模式以及内存映射这五种模式的运作原理与核心差异。 普通模式依赖页高速缓存,读阻塞、写缓存即返回,是默认的平衡选择。同步模式则通过置位O_SYNC标志,强制写操作直到数据落盘才返回,代价是更高的延迟,但确保了数据持久性。直接I/O(O_DIRECT)完全绕过页高速缓存,在用户空间与磁盘间直接传输,适合数据库等需要自主管理缓存的场景。异步模式通过aio系列系统调用实现非阻塞I/O,进程提交请求后可立即返回处理其他任务,提升了并发处理能力。内存映射则通过mmap将文件映射到进程地址空间,把文件操作转化为内存操作,简化了编程模型并可能提升大文件访问效率。 文章清晰地拆解了每种模式下内核标志位的状态与数据流路径,帮助开发者理解不同I/O策略的适用场景——比如高性能存储系统可能倾向于直接I/O或异步模式,而追求开发简便性的应用则更适合内存映射。通过对比这些模式的适用场景和实现机制,文章为开发者提供了选择I/O策略的清晰指引。
Linux下CPU的利用率
这篇讲的是如何真正理解Linux系统下CPU时间的构成,从而看懂利用率背后的含义。文章从内核时间基础切入,解释了HZ(时钟中断频率)、tick(中断间隔)和jiffies(中断累计次数)这几个关键概念,为你打下理解的底子。 核心部分是将CPU时间拆解得明明白白:它并非一个整体,而是由用户态(User time、Nice time)、内核态(System time、Hardirq time、Softirq time)以及等待(Waiting time)、空闲(Idle time)和虚拟机偷取(Steal time)时间共同组成。文章直接给出了计算公式,让你能一一对应`top`命令输出中那些让人困惑的`%us`、`%sy`、`%id`等百分比,原来它们分别代表了不同时间段的占用情况。 作者最后指明,`top`、`iostat`、`vmstat`这些常用工具的数据源头都是`/proc/stat`文件,其中的时间单位就是tick。搞清楚这些组成,当看到系统卡顿时,你才能从高企的`%sy`判断是内核子系统瓶颈,还是从高`%wa`看出是I/O等待拖了后腿,让性能分析有据可依。
CFS中的虚拟运行时间
这篇讲的是Linux内核CFS调度器中最核心也最容易让人困惑的一个概念:虚拟运行时间(vruntime)。作者从对vruntime的不理解出发,在研究cgroup的CPU子系统时,才真正理清了它的原理。 CFS追求的是理想中的“完全公平”,但现实中同一时刻一个CPU核心只能跑一个进程。因此,算法需要一种机制来惩罚当前占用CPU的进程,从而照顾那些等待的进程。这个机制,就是vruntime。简单说,vruntime越小的进程,越值得被调度。 它的精妙之处在于计算方式:vruntime并非进程实际运行的时间,而是结合了进程“权重”后的换算值。权重越大(对应用户态优先级nice值越低),进程实际运行一毫秒所产生的vruntime就越小,这样它在调度队列中的位置就越靠前(内核用一棵红黑树管理,vruntime小的在左端),从而获得更多的CPU时间。 文章还揭示了内核是如何将用户熟悉的nice值映射到内部权重的,那就是通过一个叫`prio_to_weight`的静态数组进行转换。这套机制将“优先级”这个概念,巧妙地转化为“需要运行的紧迫度”,从而在动态调度中实现了对不同重要性进程的公平分配。
页缓存概述
这篇讲的是Linux内核中一个关键性能优化组件——页缓存的工作原理与实现。作者将它比作硬件缓存的软件实现,核心思想是利用快速的主存来缓存慢速的磁盘数据,以此大幅减少I/O等待。 文章首先解释了页缓存的读写机制:读取时先查缓存,若未命中则加载并可能长期驻留;写入时则直接修改缓存中的“脏页”,并不立即写回磁盘,而是采用延迟写回的策略来合并多次修改。 实现上,内核面临两大挑战:如何快速找到特定缓存页,以及如何统一管理来自不同源(如文件、设备)的数据。文章深入剖析了address_space结构如何巧妙地解决这两个问题。它内部维护一棵radix优先搜索树,将所有属于同一所有者的缓存页组织起来,支持高效的查找、插入和删除。同时,通过a_ops钩子函数集,为不同数据源定义了统一的操作接口(如readpage、writepage),让上层逻辑与底层具体设备解耦。 最后,文章列出了内核提供的基本操作函数,如查找、分配、添加和移除缓存页,构成了操作页缓存的程序接口。整体来看,这篇文章从概念到实现,清晰地梳理了Linux内存管理中这一精巧的中间层设计。
malloc()之后,内核发生了什么?
作者从一个常见的用户空间操作出发,即进程调用 `malloc()` 后尝试访问内存,一路追踪到内核空间的真实发生过程。文章的核心在于揭示,用户感知到的“内存分配”在内核层面主要通过 `brk` 系统调用来实现,其背后是一套从修改堆描述符到最终响应缺页异常的精密机制。 讲解路径非常清晰:首先,`malloc()` 会触发 `brk` 系统调用,通过 `SYSCALL_DEFINE1(brk,...)` 服务例程来调整进程的堆边界。文中展示了该例程如何检查资源限制、对齐地址,并根据是扩大还是缩小堆,分别调用 `do_brk()` 或 `do_munmap()`。 文章的巧妙之处在于指出,此时内核通常并未立即分配物理内存。`do_brk()` 的核心工作是在进程的虚拟地址空间中分配或合并一个线性区间(VMA),为后续可能的操作“预留地盘”。真正的魔法发生在第二步:当进程首次访问这块新地址时,CPU 会因页表项无效而触发缺页异常。文章接着深入异常处理流程,从 `page_fault` 入口,到 `do_page_fault()` 判断异常类型,最终由 `handle_mm_fault()` 接手。 在 `handle_mm_fault()` 中,内核才开始真正“分配”物理内存——它确保页目录结构完整,然后调用 `handle_pte_fault()` 完成页框的分配与映射。整个过程生动地体现了 Linux 内存管理中“延迟分配”的核心思想:先给予虚拟承诺,待实际使用时再兑现物理资源,从而优化了内存使用效率。这对于理解内存分配的全链路至关重要。
RPM包的管理
这篇讲的是Linux世界里RPM包管理的那些事儿。文章从RPM(Red Hat Package Manager)这个Red Hat系发行版里的“老大哥”说起,它把软件预编译打包成标准格式,装起来是省心,但也被批评为不够灵活——你的系统环境得和打包时完全一致才行。 为了补上这块短板,SRPM(Source RPM)就登场了。它不光带源码,还贴心附上了依赖说明,安装时能自己检查缺啥。不过对于大多数用户,更常用的其实是YUM这个在线升级神器。它背后连着个服务器仓库,把所有软件和它们“谁依赖谁”的关系图都理得清清楚楚,一键安装就能自动摆平依赖链,和Debian系的apt-get解决的是同一类痛点。 文章后半段还聊了聊怎么自己动手打包RPM。核心工作是写好spec这个“配方文件”,软件叫啥、版本多少、安装时该跑什么命令都得写明白。至于找spec模板,优先级也说得很明白:先翻源码包,不行就找社区现成的改改,实在没有才自己从头写起。整个过程把RPM生态里打包分发的逻辑串了个七七八八。