sproxy开发体验
作者分享了开发sproxy代理工具时的一些实战经验。起初是为了解决内网服务需要统一通过代理访问公网的需求,他用Go编写了支持多种协议的sproxy。在后续迭代中,为了能对接Shadowsocks等服务,只需利用golang.org/x/net/proxy库并借助环境变量配置,就能轻松增加SOCKS5链式代理支持。 这次经历虽只涉及少量代码改动,却让他收获了多个实用的排坑心得。例如,在Mac上调试监听443端口的程序时,因权限不足,他通过端口重定向巧妙地解决了问题。更关键的是,他发现本地DNS解析可能被污染,导致调试时访问特定网站不通,将域名解析环节调整到SOCKS5代理之后进行则可解决此问题。文章还简要提及了dnscrypt等更复杂的DNS安全方案,以及对SOCKS5协议特性和Go语言调试环境的观察。 这些来自一线开发的具体细节与思考,对于同样在处理网络代理、开发环境调试的开发者来说,提供了不少可直接参考的路径和启发。
git diff(merge) with beyond compare
这篇讲的是如何在Mac上将Beyond Compare配置为git的差异对比和合并工具。作者从实际需求出发,指出了一个常见问题:macOS版本的Beyond Compare默认并未安装命令行工具,这使得它无法直接被git调用。文章详细说明了通过特定方式安装命令行的过程,并解释了生成的 `bcomp`(等待操作完成)和 `bcompare`(立即返回)两个命令的区别。 核心内容聚焦于git difftool的配置。作者梳理了git支持的各类图形化diff工具列表,并分析了其中 `bc`(即Beyond Compare)与 `bc3` 的关系,指出git虽内置这些工具的配置,但需在图形环境下才能正常工作。文章通过实例,如 `git difftool -t vimdiff` 的指定方式,以及使用 `-x` 选项自定义命令的技巧,展示了配置的灵活性。最终,读者可以借助这些步骤,将强大的Beyond Compare无缝集成到自己的git工作流中。
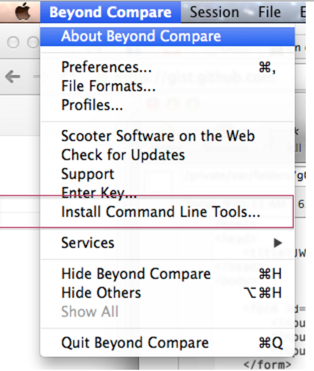
建立私有的 yum 源站
在企业内部运维中,管理统一的软件包源是个常见需求。这篇讲的是如何从零搭建一个私有 yum 源站,非常适合需要集中管控软件分发的团队。作者从最基础的三要素讲起:准备好要发布的 rpm 包、使用 `createrepo` 工具建立索引,最后通过 webserver(或本地/FTP)提供服务。 文章直接给出了可操作的步骤。从安装 `createrepo` 工具开始,到创建分层目录、复制 rpm 包,再到执行 `createrepo` 命令生成索引,每一步都有明确的命令示例。特别提醒了关键细节:每次新增 rpm 包后,都需要重新执行索引生成命令,否则客户端可能无法感知更新。 整个过程聚焦于 yum 源的核心构建逻辑,将 webserver 的具体配置留给读者自行扩展。对于想要快速搭建内部源、减少对外部网络依赖的运维人员,这套方法提供了一个轻量且清晰的起点。
linux 之 mv
这篇文章从一个真实场景切入:同事在使用 `mv` 命令将一个充满小文件的目录移动到另一个磁盘时,发现目标空间在增长,但源空间却迟迟没有释放。作者通过 `lsof` 发现,这是因为文件在移动过程中并未被立即删除,而是全部移完才清理。 那么,关键问题来了:如果移动如此大量的文件过程中发生了中断,已移走的文件会被删除吗?作者猜测可能是“删已移的,留未移的”,但这仅仅是猜测。 真正的答案藏在 `mv` 命令的源码里。作者查看了其核心实现,发现逻辑异常简洁:它只是简单地逐个复制文件,待全部成功后才执行删除操作。源码中并未对“中断”这种意外情况做任何特殊处理。这意味着,一旦中途出错或中断,结果将是:**复制完成了多少就算多少,但不会删除源目录中的任何文件**。 这个结论揭示了 `mv` 在处理大规模文件迁移时的一个重要风险点——它并非原子操作,且中断后状态不确定。对于需要进行此类操作的管理员来说,理解这一底层行为至关重要,它提醒我们务必使用更可靠的工具或脚本(如结合 `rsync` 与检查点)来处理关键数据迁移。
ssh 免密码登录
这篇讲的是如何通过三个关键命令快速配置SSH免密码登录,免去每次连接都输密码的麻烦。作者从实际操作出发,清晰拆解了`ssh-keygen`生成密钥对、`ssh-add`管理密钥、`ssh-copy-id`分发公钥这三个核心步骤。 文章特别指出了一个容易踩坑的细节:`ssh-copy-id`这个方便的工具其实属于`openssh-clients`包,而不是`openssh`包本身。作者通过直接列出两个软件包的文件清单,让读者一眼就能看清这个差异。 掌握这套方法后,无论是日常运维还是脚本自动化,都能更顺畅地连接远程服务器。理解包之间的区别,则有助于在不同Linux发行版上准确找到和安装所需工具。
grep awk 之buffer问题
作者从一个常见的管道命令场景出发,解释了为何当`grep`命令被多级管道串联时,数据不会立即流到下一阶段——比如在`while...done | grep abcd | grep abcd`中,第二条grep似乎没有实时输出。 问题的根源在于,无论是`grep`还是`awk`,它们默认都会对输出进行缓冲(buffer),并非逐行传递。对于`grep`,可以通过添加`--line-buffered`选项来切换为行缓冲模式,让数据即时流出。而`awk`的情况更为棘手,它没有直接的选项来改变这一行为,一个有效的变通方法是在awk的输出语句后执行`system("")`,利用空命令来强制刷新输出缓冲区。 这篇技术笔记精准地指出了管道通信中一个容易被忽略的底层机制,并给出了针对性的、可实操的解决方案。它提醒我们,在处理流式数据时,工具的缓冲策略是一个需要特别注意的细节。
awk之exit
这篇文章从一个具体场景出发:如何从100个总计100GB、按时间排序的日志文件中,快速找出某个特定时间点(如01:02:03)的特定内容(xxx)。作者首先给出了一个基础方案——使用awk逐行匹配并配合grep,但这会完整扫描所有文件,效率低下。 核心优化点在于利用日志的“时间有序”特性。文章展示了关键技巧:在awk中加入类似 `/^01:1/{exit}` 的规则,一旦扫描到目标时间之后的行就立即退出当前文件处理。这个巧妙的“提前退出”策略,能将原本需要扫描整个文件的工作,缩减为只处理文件开头的一小部分,极大提升了效率。文章进一步对比了使用sed实现同样效果(`sed -n '/^01:02:03/p; /^01:1/q}'`)的解法。 通过这几种方法的逐步演进和对比,文章清晰地传达了一个在处理海量顺序数据时的重要思路:了解数据的分布特征,并利用工具特性来避免不必要的计算。对于经常与大型日志打交道的人来说,这种“非全量扫描”的优化思路非常实用。
文件权限之粘滞位
这篇讲的是Unix/Linux系统中一个具体而微小的技术点:粘滞位(Sticky Bit)在可执行文件上的行为。作者从一个实际问题出发——如果给一个root属主的可执行文件设置了粘滞位,那么由它派生的其他进程,其有效用户ID(euid)还会是root吗? 为了验证,作者编写了一个简单的PHP脚本(test.php),其核心就是输出当前进程的euid和uid。随后,他通过给这个脚本文件设置粘滞位并以root身份执行来观察结果。测试发现,新进程的euid并没有如预期那样保持为root。 由此得出一个明确的结论:粘滞位(即使在可执行文件上)并不能在程序执行后被其创建的其他进程所继承。这个发现澄清了对文件权限位作用范围的一个常见误解。

关于http代理
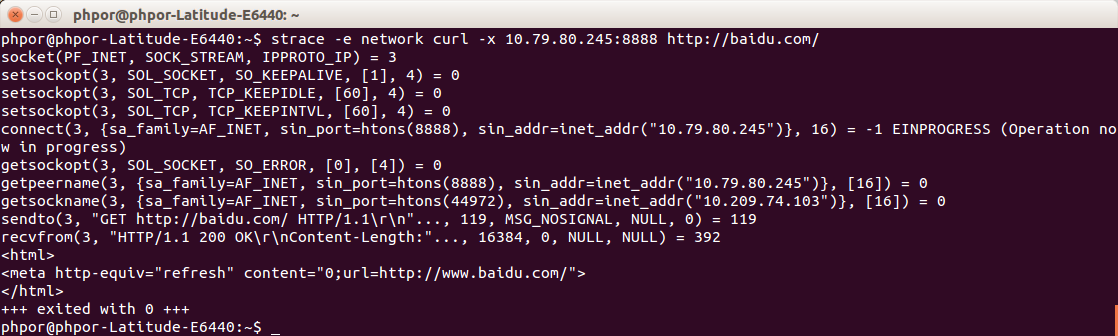
这篇技术文章聚焦于一个网络基础问题:当使用HTTP代理时,目标域名的DNS解析究竟发生在用户客户端,还是代理服务器上?作者从两种典型的代理工作模式展开分析,厘清了其中的关键差异。 第一种是直连模式,常用于HTTP请求,代理服务器直接接收客户端发送的完整URL并转发,因此域名解析由代理服务器完成。第二种是CONNECT隧道模式,主要用于HTTPS,客户端先与代理建立TCP通道,随后在通道内进行TLS握手,此时代理服务器同样负责解析目标域名。 为了验证这一点,作者进一步使用Golang编写了测试代码,并设置环境变量来配置代理。测试结果表明,无论是HTTP还是HTTPS请求,Golang的标准库实现与curl的行为一致,域名解析都发生在代理服务器端。文章还揭示了一个有趣的实现细节:在Golang处理HTTPS请求时,代理的CONNECT握手与后续的数据传输是在不同的线程中完成的。 通过对比和代码验证,这篇文章清晰地解释了不同代理场景下的底层行为,对于理解代理工作机制、进行相关调试或开发都有直接的参考价值。
关于html5本地存储
这篇文章聚焦于HTML5本地存储中的localStorage,以Chrome浏览器为例,深入揭示了其存储机制的细节。作者从存储位置入手,指出在Windows系统下,数据保存在%appdata%\Local\Google\Chrome\User Data\Default\Local Storage\目录中,并通过SQLite命令行工具演示了如何查看本地数据库——例如运行sqlite3命令查询ItemTable表,直观展示数据以键值对形式存储,如示例中的name|phpor。 文章还明确了localStorage的大小限制为5MB,这对于开发者规划前端存储策略具有实际参考价值。参考资料部分列出了多个技术博客链接,包括HTML5中国网、CSDN和ITeye上的相关文章,为读者提供了进一步探索的资源。整体上,这篇内容从实践角度出发,将抽象的HTML5存储概念转化为具体可操作的步骤,帮助开发者快速理解localStorage的底层实现和应用要点。
关于libmemcached中的crc的实现
这篇讲的是作者在尝试用PHP自定义实现memcached客户端时,遇到的一个具体问题:为保证与libmemcached行为一致,需要让PHP中的CRC32算法输出与C库相同。 作者发现,尽管基础算法相同,但PHP内置的`crc32()`函数与libmemcached中的实现存在关键差异。根本原因在于:PHP的`crc32()`返回的是一个32位有符号整数,而libmemcached实际使用的是该结果的高16位,并且忽略了符号位。这意味着简单的结果并不相等。 文章不仅点明了差异,还给出了两种在PHP中模拟libmemcached CRC32行为的方案。一种是利用位运算的高效实现(`(crc32('test')>>16)&0x7fff`),另一种是完整的查表算法模拟。作者通过对比指出,完整的PHP模拟实现(需要大量pack/unpack操作)比位运算方案慢约100倍,这为性能敏感的场景提供了重要参考。文末附上了C语言库的相关源码,便于对照理解。
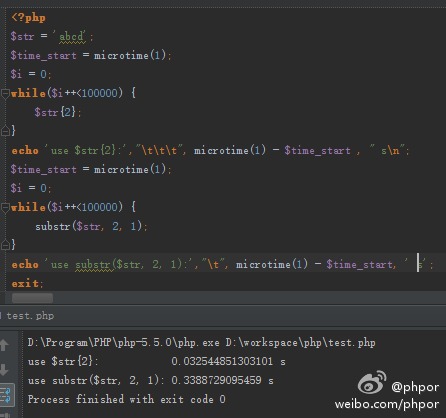
PHP中字符串截取的效率
这篇讲的是 PHP 中一个性能细节:截取单个字符时,`substr()` 函数与直接使用 `$string{$start}` 或方括号访问的效率差异。 作者从算法优化的角度切入,因为在密集循环中,单个操作的微小差异会被放大。他设计了一个简单的基准测试,循环十万次来对比两种写法。结论很直观:直接使用 `$string{$start}` 的方式,执行速度大约是调用 `substr()` 函数的 **10 倍**。 文章还附上了这段测试代码,方法清晰易懂。这个发现意味着,在 PHP 中进行高频字符串操作(例如实现某些算法或处理大量文本)时,优先使用数组式的直接下标访问,不仅能写出更简洁的代码,还能获得显著的性能提升。对于追求代码效率的开发者来说,这是一个值得记住的实用技巧。
关于Cookie长度的思考
这篇讲的是如何在有限的存储空间(比如浏览器的Cookie)里“挤”下更多信息。 作者从一个常见的问题出发:如何让存储的数据变得更小?文章没有停留在理论上,而是直接列举了我们熟悉的“key_len + key + value_len + value”这种存储格式作为分析起点。接着,作者给出了一系列非常具体的“瘦身”技巧:如果字段长度固定,对应的长度标识就能省掉;如果给字段编个号,字段名本身也能缩短;甚至可以完全依赖顺序来定位,连字段名和长度都能一并去除。 更巧妙的是处理变长数据和空值的思路。比如,用一个单独的“元字段”来标记哪些值是空的,从而省掉原本用于表示空值的长度字节。文章还提出了一个很实用的“默认值”策略:把频繁出现的值设为默认,不实际存储,仅用极少的位数(如2比特)来标识当前用的是哪个默认值。 所有这些优化背后有一个统一的原理:信息并没有丢失,而是巧妙地“藏”进了代码逻辑和预设规则之中。这篇文章就像一位经验丰富的工程师在分享他的存储空间优化心得,把看似简单的数据结构玩出了很多节省空间的花样。
jQuery.ajax处理302重定向
这篇文章探讨了一个前端开发者常遇到的坑:使用jQuery.ajax()时,遇到302重定向为什么会“卡住”?作者从底层原理出发,指出问题的核心在于xmlHttpRequest的跨域限制。如果跳转目标是同域,服务器本就不该用302;如果是跨域,则天然会被浏览器拦截。不过,随着现代浏览器对CORS的支持,情况有了变化。在配置得当的前提下,302是能够被处理的。文章给出了一个实用的解决思路:利用ajaxComplete事件来捕获这个“错误”,并手动跟踪重定向。作者特别提醒,如果业务需要携带Cookie,切记要在xhr对象上设置withCredentials为true,否则认证信息可能会丢失。文章最后引用了Stack Overflow等社区的讨论,提供了深入实践的参考。
tailf and tail -f
这篇文章从一个实际使用场景出发:用`tailf`查看大文件的新增日志时,发现没有输出,而改用`tail -f`却能立即显示。由此引出了对这两个命令核心机制差异的深入剖析。 文章指出,二者的关键区别在于读取起点和检测文件变化的系统调用不同:`tailf`从文件开头逐步读取,通过文件名调用`stat`来检查文件变化;而`tail -f`则从文件尾部开始,通过已打开的文件描述符使用`fstat`进行检测。这个底层差异导致了具体行为的不同,比如在文件被删除时,`tailf`能感知到,而默认的`tail -f`则不知道。 此外,文章还详细解读了`tail -F`选项(大写F)的工作原理——它通过周期性地尝试重新打开文件来兼顾对文件名变化的跟踪,是一个在`tailf`和`tail -f`之间的实用折中。最后通过`strace`跟踪的输出,直观展示了`tailf`使用`stat`与`tail`使用`fstat`的调用区别。 对于经常需要监控日志文件的运维和开发人员来说,理解这些区别能帮助他们在不同场景下选择最合适的工具。
关于sqlite的事务的使用
SQLite以读性能出色著称,但写入性能有时会让开发者头疼。这篇来自作者实践经验的文章,就从一个具体问题切入:批量插入500条小记录居然需要20多秒,异常缓慢。 问题的根源是什么呢?作者通过strace工具追踪系统调用发现,高达88.73%的耗时(超过27秒)都花在了`fdatasync`系统调用上,调用次数多达2064次。这正是因为SQLite默认的“每次写入都落盘”的安全策略所致,频繁的磁盘同步成为了性能瓶颈。 文章给出的解法很直接:使用事务。将多次写入操作包裹在一个事务中,使得数据能够一次性批量提交。优化效果立竿见影:`fdatasync`调用从2064次骤降至12次,整体耗时从27.6秒猛降到209毫秒,性能提升了百倍以上。 作者也进一步探讨了相关话题,比如无法批量操作时可选用的nosync版本,以及面对超大数据量时分批提交事务的考量。这篇文章的价值在于,它用非常实证的数据,清晰展示了SQLite写入慢的核心原因以及事务优化带来的巨大提升。
IE6下经典的请求abort问题
作者掉进了一个坑:在IE6下给`a`标签绑定事件来切换验证码图片,但图片总是刷不出来,抓包一看请求状态是**abort**。问题出在IE6对`a`标签的执行顺序上——它先执行`onclick`里的事件处理函数,紧接着就会执行`href`属性定义的跳转。如果你没有在事件里阻止这个默认的跳转行为,浏览器会认为页面即将导航离开,从而把刚才在`onclick`中发起的请求(比如获取验证码的AJAX请求)给强制中止了。 解决办法很直接:在事件处理函数的最后加上`return false;`,或者把`href`属性改成不会跳转的锚点,比如`javascript:void(0)`或`#`。最稳妥的做法是两者结合使用。文章通过这个具体的bug,把IE6下事件流与页面跳转之间的微妙关系讲得很清楚,虽然现在IE6已罕见,但其中关于浏览器默认行为会干扰异步请求的原理,在其他场景下依然值得留意。
文本与二进制方式打开文件的区别
这篇讲的是编程中一个容易被忽略却至关重要的细节:以文本方式和二进制方式打开文件究竟有何不同。 文章首先点明,在Windows系统下,这种差异直接体现在对换行符的处理上——文本模式会默默进行“/n”与“/r/n”的相互转换,而二进制模式则原样读写。在Unix/Linux下,两者则没有区别。作者进一步深入到底层,解释了差异的根源:文本文件是基于字符编码(如ASCII),而二进制文件是基于值的自定义编码。这也决定了文本文件通常有更好的通用可读性(记事本就能打开),而二进制文件则更节省空间且灵活。 文章通过一个生动的例子说明,用记事本打开一个二进制文件(比如包含数字1的二进制表示),会因为解码方式不匹配而显示乱码。而在C语言编程层面,核心区别也仅仅在于换行符的转换,当数据不包含换行符时,两种模式的读写结果其实是一样的。最后,通过展示数字“5678”在两种模式下截然不同的存储形式(ASCII码占四字节,二进制仅占两字节),直观地揭示了它们的空间效率差异。理解这点,能帮助开发者在处理配置文件、日志或跨平台数据交换时,做出更合适的选择。
关于PHP加速器APC的使用
这篇讲的是PHP加速器APC一个容易被忽略的实用功能:`apc_store`。大家通常只知道APC能缓存PHP字节码来提速,但作者将视角转向了它作为通用键值存储的应用。核心场景是:当项目的配置信息(尤其是那个可能无比庞大的多维数组)频繁被读取时,与其每次启动都解析文件,不如直接用`apc_store`将整个配置数组一次性缓存在共享内存里。这相当于给应用启动配置提供了一个极速通道,避免了重复的文件I/O和解析开销,让应用能更快地投入服务。文章聚焦于这个具体实践,点明了从“缓存代码”到“缓存数据”的思维延伸。
关于PHP中配置文件的定义
这篇讲的是PHP中配置文件定义的几种常见方法及其适用场景。作者从实际项目开发出发,详细拆解了定义配置文件的不同方式,比如直接使用数组、常量或通过第三方库如Symfony的Config组件来管理。 核心对比集中在灵活性和性能之间。例如,传统的conf.php文件定义简单直观,适合小型项目或快速原型,但扩展性有限;而基于类或YAML/XML的配置方式则提供了更强的类型检查和模块化能力,更适应大型应用或微服务架构。文章还点出了不同方法在安全性和维护成本上的关键差异,比如硬编码配置可能带来安全风险,但执行效率更高;外部化配置便于动态更新,但需要额外的解析开销。 对于开发者来说,选择哪种定义方式往往取决于项目规模、团队习惯和部署环境。文章通过代码示例和实际案例,帮助读者理解如何平衡这些因素,避免常见的配置陷阱。