“NodeJS在大搜车” 之 应用部署篇
作者从团队实际需求出发,分享了NodeJS应用在大搜车的部署实践。文章的核心在于解决不同环境下Node进程的稳定管理与高效部署问题。 针对工具选型,作者解释了为何线上环境选用功能全面、进程管理更稳定的PM2,而在需要频繁变更端口的测试环境,则采用更轻量灵活的Forever。本地开发则配合nodemon实现代码热更新。这套组合策略平衡了稳定性与灵活性。 在环境划分上,文章详细介绍了测试、预发、生产三套环境各自的作用与配置。生产环境依托阿里云ECS、SLB、RDS等一整套云服务,基本免除了底层运维烦恼。部署流程则通过自定义Bash脚本实现:从代码拉取、打包上传,到服务器上的解压、备份、覆盖及PM2重启,整个过程在预发服务器上执行,并通过间隔部署配合负载均衡,确保线上服务零宕机。 文章最后坦诚,这套部署体系仍在不断进化,未来计划引入Docker优化测试环境,并着手应对多环境自动部署、性能优化等新挑战。
“NodeJS在大搜车” 之 MVC基础结构
这篇讲的是大搜车团队如何在实际项目中落地NodeJS的MVC架构。作者从前端是否适合直接转向NodeJS服务端开发这个话题切入,提出了一个颇具启发性的观点:服务端开发所需的架构、性能、运维等综合能力,可能让一名经验丰富的PHP工程师转型得更顺畅。这其实引出了本文的核心——扎实的服务端思维与架构设计至关重要。 文章随后详细拆解了他们项目中的MVC实践。除了Controller、Model、View这些基本要素,重点阐述了几个关键扩展层。例如,Service层被定义为整个架构中最重的一环,它封装了跨数据库、跨缓存的复杂数据操作,为Controller提供简洁的“服务”。Route层则通过自研的rainbow库,实现了基于文件目录的自动化路由管理与API文档生成,便于维护成百上千个接口。此外,团队还在ORM之上封装了SuperModel,旨在统一MySQL和MongoDB的操作接口,并提供类似Mongoose的链式调用体验。 这些细节不仅展示了一套清晰、可维护的NodeJS项目结构,也体现了团队在工程化方面的深度思考。对于正探索NodeJS服务端开发的前端工程师,或是寻求不同技术视角的后端开发者,文中关于架构分层与工具封装的具体实践,提供了扎实的参考案例。
如何在Angular中使用动画
这篇讲的是如何在AngularJS中为常见指令添加交互动画效果。作者开宗明义,指出Angular本身并不内置动画,需要通过引入ngAnimate模块来赋予动画能力,并且它的高度可定制性是其特点。 文章的核心是梳理了ngAnimate支持动画的具体指令列表,包括ngRepeat的进入、离开和移动动画,ngView、ngInclude、ngIf等的进入与离开动画,以及ngClass、ngShow/ngHide等的添加与移除类动画。这些细节清晰地展示了AngularJS动画机制的作用范围。 最后,文章以列表渲染指令ngRepeat为例,具体演示了如何配置和使用这些动画,帮助开发者理解动画元素进入DOM结构的过程。对于需要在旧项目中提升交互体验的开发者来说,这份针对ngAnimate模块的使用指南提供了直接的参考。
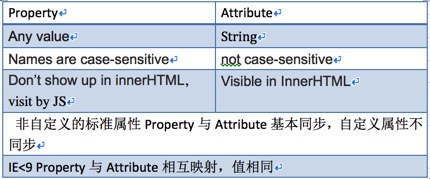
DOM中Property与Attribute的区别
这篇讲的是前端开发中一个经典又容易踩坑的问题:DOM里Property和Attribute到底有什么不同。虽然中文都常被译作“属性”,但它们在JS和HTML中的角色、行为与生命周期有着本质区别。 文章从源头梳理了二者的核心定义:Property是JS对象的属性,可以是任意类型,主要用于JS操作;而Attribute是HTML的特性,值始终是字符串,并通过`getAttribute/setAttribute`方法操作,直接体现在DOM结构上。一个关键背景是,在IE<9时代,浏览器将二者强制映射,这给许多开发者留下了“它们是一回事”的误解。 作者重点剖析了它们之间复杂的同步关系。自定义的Property与Attribute互不干涉;而非自定义的属性(如`id`, `src`, `value`)则有条件同步——例如,用`setAttribute`修改`input`的`value`会同步到Property,但通过`.value`赋值却不会反向同步到Attribute。`href`/`src`等属性的取值方式也不同,`getAttribute`拿到的是原始值,而Property则是完整的URL。 对于开发者而言,理解这个区别至关重要,尤其是在使用jQuery等库的`.attr()`和`.prop()`方法时,混淆二者可能导致难以排查的UI状态同步bug。文章最后用一张关系图清晰总结了这些复杂情况。
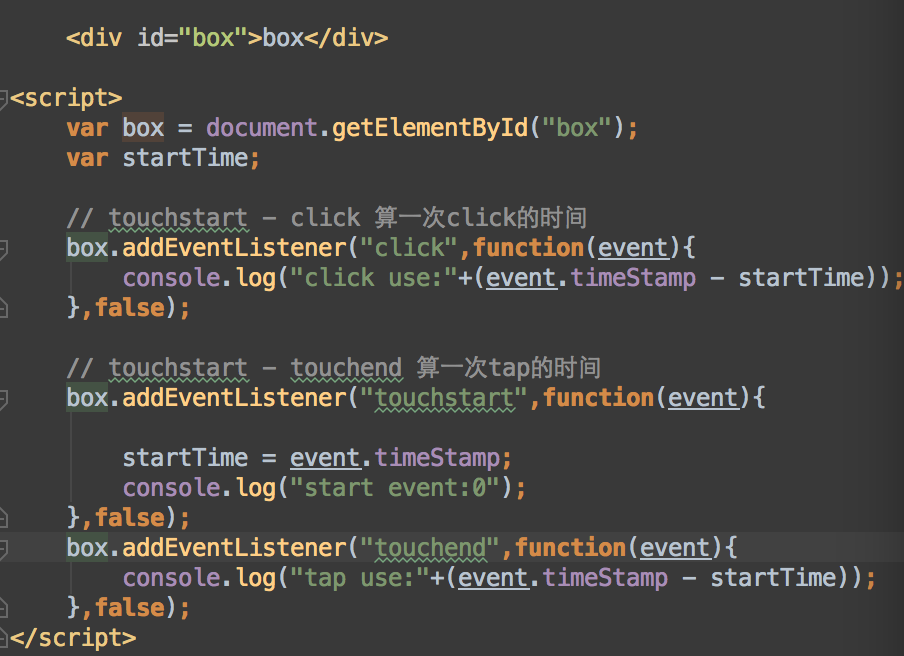
移动端点击、触碰随记
这篇讲的是移动端开发里几个老生常谈却又总踩坑的“事故”:点击延迟、点穿和焦点获取错误。作者从实测数据出发,直观展示了移动端原生click事件为何存在约300ms的固定延迟(为了判断是否双击缩放),以及为何要拥抱更快的tap事件(如zepto的实现)。 文章深入分析了触摸事件与鼠标事件的触发顺序,指出tap和click本质是同一次触碰的不同阶段。针对“点穿”这个经典坑(根源在于事件绑定层级),作者对比了阻止事件流的方法,明确preventDefault是关键大招,并顺势对比了fastclick、Yocto等库的解决方案,分析了它们的原理与适用场景。 最后,文章还深入探讨了在Angular框架下如何处理ng-click点穿问题,以及如何区分处理input、textarea等元素的焦点获取需求,给出了具体的代码思路。全文从现象到原理,再到框架内的实战方案,是一份扎实的移动端触控问题排查指南。
一个“三端”开发者眼中的React Native
这篇讲的是一位常年穿梭于前端、服务端和客户端的“三端”开发者,初次接触React Native时的真实感受与深度观察。作者没有停留在技术介绍,而是从自己饱受iOS开发中代码冗长、布局繁琐、调试耗时等痛点困扰的经历出发,生动地分享了RN如何像一位“校花”般用统一的Component模型、动态绑定、类CSS样式和Flexbox布局,解决了这些长期痛点。 文章直率地列举了RN当前阶段的不足,比如组件不全、性能损耗、仅支持iOS以及代码并非全平台通用等现实问题。但核心价值在于作者提出的理性视角:技术讨论不能脱离场景。他从前端与客户端两个角度分析了RN带来的影响——对前端而言,这是拓展技术栈的有趣方向;对客户端开发者,它简化了开发流程,并带来了更高效的NPM生态。 最后,作者展望了一种未来的协作模式:前端负责表层业务开发,客户端团队则专注于构建和封装底层原生组件。文章结尾鼓励开发者不要止于议论,而应动手实践,在学习中积累。这种从个人实践上升到团队协作模式的思考,为如何看待这类跨平台技术提供了切实的参考。
解读CSS布局之-水平垂直居中
这篇文章从CSS布局的分类入手,系统梳理了水平垂直居中的多种实现路径。作者基于实际项目已无需兼容低版本IE的背景,重点介绍了 `line-height + text-align:center`、盒模型(padding/margin填充)、绝对定位(50%偏移 + transform/负margin)等核心方法,并附有可运行的Demo。 文章的关键在于对比了不同方案的适用场景:`line-height` 方案简单但仅限单行文本;盒模型填充方案性能好、不触发回流,是重要的布局思想,但通常需要预知尺寸;而绝对定位的 `transform` 方案则能实现对未知宽高元素的完美居中,是现代前端的常用技巧。作者通过代码片段与原理解释,清晰地呈现了每种技术的取舍点。 通篇行文从整体布局观出发,落脚于具体实现细节,为开发者在面对“居中”这个高频需求时,提供了清晰的选择图谱和可直接套用的代码参考。
移动端自适应方案
这篇文章探讨了移动端页面适配的核心问题:是否需要动态调整viewport的scale,以及如何选择最合适的自适应方案。作者从css开发者大会的分享出发,深入分析了手淘、天猫和手机携程三家大型网站的实际做法。 手淘方案通过获取设备dpr,动态生成viewport并利用rem进行布局;天猫则采用固定scale=1.0,结合flex布局以iPhone6宽度(375px)为基准;手机携程相对传统,使用固定的scale配合px与百分比布局。 作者针对常见的“1px问题”和“倍图适配”需求进行了实验验证。结论是,虽然动态调整scale能精确还原设计稿的1px边线并匹配不同dpr的图片,但实现成本较高。对于大多数项目,采用固定scale=1.0的“完美视口”,并配合rem管理尺寸、flex构建布局,是一种性价比很高、足以应对多数场景的实践方案。关键在于根据项目对还原度的具体要求,在开发成本与效果之间做出权衡。
大搜车前端开发模式:被动编译和主动编译
这篇讲的是大搜车前端团队如何根据业务发展,演进他们的开发构建模式。作者从团队规模扩大、业务复杂度提升的背景出发,坦诚原有“被动编译”模式开始力不从心。 所谓“被动编译”,核心是源码在被浏览器访问时才通过小型服务器(ads)动态编译,实现了零配置、环境统一和高度灵活的动态应用(如在线换肤)。但随着 AngularJS、React 和 ES6 的大规模使用,这种模式难以处理复杂的打包需求。 因此,团队引入了“主动编译”作为补充。他们选用 gulp 作为构建工具,用于处理较重的前端项目,在本地完成打包后再上传。重要的是,这并非颠覆,而是互补:重项目用 gulp 独立构建,普通页面仍沿用简单高效的被动编译。 文章不仅分享了技术选型的思考,也强调了引入新模式时的风险控制,例如统一项目模板、规范插件使用。这为面临类似技术栈演进与团队协作平衡问题的团队,提供了一个务实且可参考的架构调整思路。
我为什么要使用哈希
这篇讲的是如何用哈希技巧解决一个经典的算法问题:在二叉树中找出所有结构完全相同的子树。 文章从一道大厂面试题切入。问题要求给定一棵二叉树,找出所有彼此完全相等的子树对。作者分享了自己的通过面试的解法,核心思路正是借助哈希。通过后序遍历整棵树,为每个节点计算一个哈希值——叶子节点用一个固定值(比如 md5("")),非叶子节点则将其左右子树的哈希值拼接后再次哈希。这样,任何子树都能被映射为一个唯一的哈希指纹。 计算出所有子树的哈希后,将它们放入哈希表。哈希值相同的子树,其结构“有可能”完全相同,但需要二次验证以排除哈希冲突。验证过程是递归地同时遍历两棵树,检查所有节点的左右子树存在状态是否一致。文章还提到了一个关键的优化:通过记录子树深度,在验证前就能排除掉大量哈希值相同但深度不同的“伪匹配”,极大地减少了不必要的递归检查。 整个过程清晰地展示了哈希作为一种“指纹”技术,在加速查找与比对操作中的强大作用,将复杂问题的复杂度显著降低。