网站分析感悟:无细分,毋宁死!(一)
这篇探讨的是网站数据分析中常被忽视却至关重要的维度——细分。作者以“无细分,毋宁死”为切入点,直指许多分析报告流于表面、结论模糊的痛点。他从实际工作中的观察出发,强调了如果只看整体流量或转化率的总览数据,往往无法洞察真正的问题所在或增长机会。 文章很可能通过对比案例说明,当数据被按用户来源、设备类型、行为阶段等维度切片后,截然不同的故事便会浮现。比如,整体转化率平稳的背后,可能是新用户大幅流失与老用户忠诚度提升这两种趋势的相互抵消。作者想传递的核心观点是,细分不是分析的“可选步骤”,而是让数据产生指导意义的“必要前提”。这提醒每一位数据从业者,在急于得出结论前,先问自己:我的数据是否已经足够细分?

警惕网站分析监测实施的陷阱(下)
这篇讲的是网站分析监测实施中容易被忽视的系列陷阱,作为系列下篇,它聚焦于那些看似配置完成却可能导致数据失真或效果评估偏差的“隐性坑”。作者从具体的项目实践出发,指出了三个典型问题:一是跨域追踪配置不全导致的用户行为断裂,二是事件埋点命名混乱引发的分析报表难以解读,三是UTM参数误用造成的渠道归因失真。文章不仅剖析了每个问题背后的技术实现疏漏,更重要的是给出了经过验证的排查思路和修正方案,比如通过浏览器开发工具实时模拟追踪请求、建立统一的事件命名规范文档等。最后,作者强调,分析工具的价值不在于安装本身,而在于实施过程中对每一个细节的严谨把控,这直接决定了后续数据驱动决策的可靠性。对于负责数据采集和基础建设的工程师或产品经理而言,文中提到的自检清单具有很高的实用参考价值。
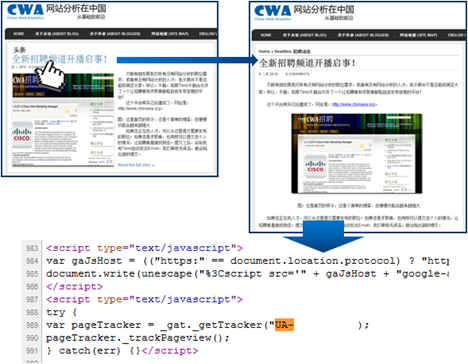
警惕网站分析监测实施的陷阱(上)
这篇讲的是,很多团队在上线网站分析监测系统时,如何因为一系列看似微小却致命的“陷阱”,最终导致收集到的数据失真,分析模型完全失效。作者从真实的咨询案例出发,点出问题的根源往往不在于工具本身,而是在于实施前的规划与实施中的细节把控缺失。文章具体拆解了几个常见坑点:比如因为页面异步加载或技术迭代导致代码部署错位,造成数据源从一开始就不准确;或是对“转化事件”的定义模糊不清,使得团队后续的决策基于完全不同的度量标准。它提醒读者,一个稳健的监测体系,核心在于实施时的严谨与前瞻性思考,而非事后对“垃圾数据”的复杂清洗。作为系列文章的开篇,它把焦点放在了问题的识别与预防上。

服务器日志网站分析的原理及优缺点
这篇讲的是网站分析两大技术流派之一——服务器日志分析的来龙去脉。作者从最基础的原理出发,解释了它如何直接处理Web服务器(如Apache、Nginx)生成的原始日志文件,通过解析其中的每一行记录来追踪用户行为。这种方法的最大优点在于数据自主可控,不依赖第三方脚本,且能捕捉到爬虫、系统错误等客户端分析工具容易忽略的信息。然而,它的短板也很明显:在动态网站和复杂客户端交互面前,实现精准的用户会话识别和页面流分析非常困难,且对服务器性能有一定影响。文章的核心价值在于理清了这种“经典”方案的适用边界——它特别适合需要全量原始数据、关注爬虫或基础技术监控的场景,但在追求精细化用户行为分析的今天,它往往需要与JavaScript标记法等其它技术结合使用。

网站分析“高考”答案
这篇文章用一个有趣的方式切入了网站分析中一个看似简单却容易引发分歧的计算规则:当一次用户访问(Visit)的时间跨越了午夜零点,系统该如何界定它的“归属日”?对应的页面浏览量(PV)又该如何统计? 作者从一位博友提出的这个“出其不意”的问题出发,探讨了不同网站分析工具(如Google Analytics等)在处理跨天访问时可能出现的差异。文章深入解释了访问会话(Session)的“超时”机制通常是基于用户最后一次活动后的固定时长(如30分钟)来断开,而并非严格按日历日切割。因此,一次从昨晚开始的访问,即使跨过了零点,只要用户活跃状态持续,就仍可能被算作一个连续的“访问”,并全部归入开始的那一天。 对于页面浏览量(PV)的计算,文章也指出,工具会按实际发生的时间戳记录每一次页面查看。所以,即使整个访问被算在“昨天”,在“今天”凌晨打开的页面也会被精确地记录到今天的PV中。这种看似矛盾的统计逻辑,背后是工具为了保持用户行为会话完整性而采用的设计。 文章通过解答这个具体问题,实际触及了网站分析工具中时间窗口设定的底层逻辑,帮助运营者避免因统计口径误解而导致的数据分析偏差。

五个实用的Google Analytics过滤设置
这篇写给GA新手的文章,直接分享了五个能立刻提升数据质量的过滤设置。作者从日常咨询最多的问题入手,重点讲解了如何过滤内部团队访问、清理垃圾引荐来源、处理跨子域名跟踪,以及统一网页路径大小写等实操技巧。这些设置看似基础,却是获得干净、可靠分析数据的前提,能有效避免内部数据干扰和无效流量污染。 文章特别强调了这些设置的“实用性”,避免了复杂理论,直接给出配置步骤和注意事项。作者也预告了后续将会有更深入的高级过滤功能解析,为想进一步提升数据处理能力的读者指明了学习路径。

网站分析常用英语名词速览
这篇文章聚焦于网站分析领域中那些看似熟悉、实则容易被误解或混淆的专业英语名词。作者没有重复Page View、Visit这些基础概念,而是另辟蹊径,将笔触伸向了从业者日常工作中可能产生疑惑的“知识盲区”。 全篇按字母顺序梳理术语,像一份精心准备的“排雷指南”。它的价值不在于罗列,而在于解析——帮助你厘清那些日常挂在嘴边、却未必完全理解其精确定义的词汇。对于需要严谨对待数据、进行跨团队沟通的分析师、产品经理或市场人员而言,厘清这些基础概念是确保分析框架一致、避免结论偏差的第一步。 读下来,它更像是在为你清理“专业语言”中的模糊地带,让你在与国际同行讨论或阅读英文文档时,能更准确、自信地运用这些术语。
Avinash:什么是目标、度量、KPI、维度和细分
周末出门闲逛前,阿维纳什(Avinash)惯例地先完成了本周的“作业”——一篇旨在厘清数据领域基础概念的实用指南。这篇讲的是,为什么很多人(包括不少从业者)会搞混“目标、度量、KPI、维度和细分”这些看似基础却至关重要的术语。 作者的出发点很直接:在实际工作中,这些概念经常被交替误用,导致沟通低效甚至决策偏差。他指出,“目标”是具体、可衡量的意图(比如“将用户留存率提升5%”);“度量”是用于追踪目标进展的广义指标(如“日活跃用户数”、“会话时长”);而“KPI”则是其中最关键、能直接反映业务健康的少数几个核心度量。至于“维度”和“细分”,则是分析这些数据的不同“切面”:维度是观察数据的角度(如按设备类型、地区),细分则是在某个维度下进行的更精细切分(如在“移动设备”维度下,细分出iOS和安卓)。 文章最巧妙的地方,在于将这些抽象概念与“逛超市”的日常场景进行了类比,并用一个清晰的对比表格将它们的定义、例子和适用场景并置,让差异一目了然。作者强调,理解这些基础是进行有效数据驱动决策的第一步,能避免团队陷入“度量虚荣”的陷阱,真正聚焦于对业务有意义的洞察。

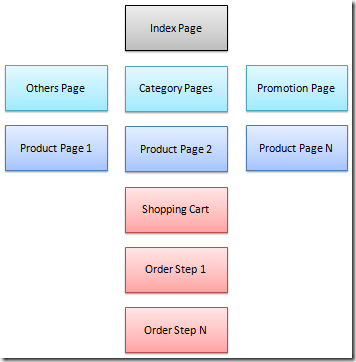
Advanced Segments 快速诊断电子商务网站
这篇讲的是作者如何利用Google Analytics的高级细分功能,对电子商务网站进行快速诊断。作者从一次周末的思考中获得启发,进而将分析工具应用到实战中。文章核心围绕如何通过设置和应用不同的数据细分维度(例如用户来源、行为路径、转化状态等),从看似繁杂的流量数据中,精准定位影响转化率或用户体验的具体环节。例如,针对购物车放弃率高的问题,通过创建“已加入购物车但未结账”的用户细分,能够深入分析这部分用户在网站上的后续行为、停留页面乃至设备特征,从而找出流程断点或体验痛点。文中分享的操作思路和洞察方法,能帮助运营和技术人员跳脱出总体数据的迷雾,直接聚焦于关键用户群体,让数据驱动决策变得更具象、更可执行。