海量数据处理专题(六)――双层桶划分
这篇讲的是海量数据处理中的一种高效分治策略——双层桶划分。文章从单层桶在处理极大规模数据时可能遇到的内存瓶颈出发,引出了双层桶的核心思想:通过两级映射,将海量数据“化整为零,逐个击破”。 具体来说,作者首先阐述了如何根据数据的分布范围设计第一级“粗桶”,将数据初步映射到有限的桶空间中。随后,针对数据量仍然巨大的个别桶,再设计第二级“细桶”进行二次划分。这样做的好处在于,无论原始数据量多大,每一级处理时,我们面对的都是一个可控的小规模子集,从而极大地降低了内存消耗和I/O压力。 文章的重点在于阐述这种两级映射的实现逻辑与关键细节,比如如何确定桶的数量、如何设计映射函数以确保均匀分布,以及在桶内数据排序或统计时如何优化。这种方法的巧妙之处在于,它用相对简单的两次划分,优雅地解决了单次划分无法兼顾数据规模和内存限制的矛盾,是分布式计算和外存算法中一个非常经典且实用的思路,尤其适用于排序、去重等基础操作。
图说浏览器战争:火狐、微软、谷歌那些事
这篇讲的是浏览器战争的图片史,作者用一系列趣味插图串起了火狐、IE和Chrome之间的恩怨情仇。文章从经典的火狐(Firefox)咬IE画面切入,展示了两者早期激烈的竞争:从各种“咬”姿到“烤”和“顶”,幽默地呈现了浏览器市场上的硝烟味。 随后,焦点转向Chrome的诞生与崛起。图片描绘了Chrome如何“身手不凡”地加入战局,与IE、火狐形成三足鼎立的僵持局面,甚至出现了“恐怖袭击”般的对抗隐喻,凸显了Google介入后竞争的新维度。 文章进一步通过“混战”场景,展现了浏览器战争的白热化阶段,各种“武器”上场,画面堪称壮观。最后,以IE 6的衰落收尾——从被冷落到“伤痕累累”,最终“入土为安”,生动回顾了这款曾经的霸主如何被时代淘汰。 整体上,文章以轻松的方式复盘了浏览器发展的关键节点,通过视觉叙事让技术竞争史变得鲜活。它不仅回顾了历史,也让读者感受到技术迭代背后的趣味与必然。
人脸识别算法综述-(LPP,PCA,K-L,SVM)
这篇综述直面人脸识别领域的核心问题:如何从庞杂的算法中理清脉络,并评估其实际效果。作者没有停留在理论介绍,而是直接以工业界世界级人脸测试数据为基准,点明了当前技术发展的真实水平。 文章的技术剖析从二维与三维两个视角系统展开。在二维特征提取层面,详细对比了PCA(主成分分析)通过全局降维捕捉主要特征、LPP(局部保留投影)侧重维护数据局部几何结构的差异,并阐释了K-L变换在特征选择中的作用。对于分类决策环节,则重点剖析了SVM(支持向量机)如何有效处理高维特征并实现精准分类。这些经典算法构成了现代人脸识别系统的基石。 更难得的是,文章不仅横向对比了算法特性,还纵向梳理了从二维到三维的技术演进路径,最终落脚于对算法发展趋势的判断。这种结合了客观测试数据、关键技术拆解与未来视野的写作方式,为读者提供了一个既扎实又清晰的认知框架,能有效帮助工程师在项目选型时做出更合理的权衡。
m进制转换为n进制-任意进制转换算法
这篇文章聚焦于编程面试中频繁出现的任意进制转换问题,即如何将m进制数高效转换为n进制数。作者没有停留在简单的十进制转换案例上,而是直击核心:提出一套通用的算法思路,能处理从二进制到三十六进制等任意基数间的转换。 算法的核心在于将问题拆解为两个可复用的步骤。首先,将输入的m进制字符串按照“权值叠加”的原理,逐位计算并累加,转化为一个中间十进制数值。紧接着,再将这个十进制数通过经典的“除基取余”法,不断对目标基数n取模并逆向拼接,得到最终的n进制字符串。巧妙之处在于,这套两步走的流程将一个复杂问题标准化,无论基数如何变化,底层逻辑都保持一致。 这种实现不仅思路清晰,也极大地提升了代码的通用性和可维护性。文章通过这道经典的面试题,实际上深入浅出地讲解了数制本质与编码思维,对巩固算法基础很有帮助。
ERWin教程(包括如何注册)
这篇讲的是专业数据库设计工具ERWin与更通用的Visio之间的对比选择。作者从实际设计场景出发,指出虽然ERWin的学习曲线比Visio更陡峭,界面选项也更复杂,但在应对模型层次深、数据对象关系繁杂的大型项目时,ERWin的优势就显现出来了。它专注于ER模型设计,并提供了强大的数据库正向与逆向工程能力,能直接将设计转化为实际数据库或反向读取现有库结构,还能自动定义格式生成设计文档。这些功能是通用工具Visio难以企及的。对于追求设计严谨性和工程化落地的数据库开发者而言,ERWin显然是更趁手的利器。文章最后也附带了ERWin的具体注册步骤,为有需要的读者提供了入门指引。
百度日本-四面楚歌
这篇文章讲述了百度进军日本市场的坎坷历程。从2007年筹措日本分公司时斥资12亿日元(约合1亿人民币)采购服务器,到2008年1月正式推出百度日本站点,初期投入不可谓不大。然而,文章通过复盘指出,百度日本随后陷入了“四面
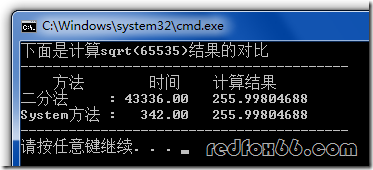
一个Sqrt函数引发的血案
这篇讲的是一个常见数学函数背后的性能奥秘。作者从“我们平时如何计算sqrt”这个朴素问题出发,带读者一路探索了三种实现方案的性能差异,堪称一部微型算法演进史。 文章先从最直观的二分法讲起,虽然结果正确,但性能与系统函数相差几百倍。接着引入牛顿迭代法,性能大幅提升,但仍与系统实现有差距。真正的高潮来自那个被称为“Fast Inverse Square Root”的神奇函数——它利用了浮点数的二进制表示与整数的位运算,仅用几行位操作和一次牛顿迭代,就实现了比系统函数更快的倒数平方根计算。 这个诞生于《雷神之锤3》引擎的算法,其核心魔力在于一个神秘的魔法数字(0x5f3759df),背后涉及对浮点数结构的深刻洞察。文章不仅解析了其精巧的实现,还追溯了它从游戏代码到学术论文的传奇故事,揭示了理论数学与工程实践在极致优化需求下的美妙碰撞。
谷歌(Google)2011年校园招聘笔试题
这篇整理了谷歌2011年校园招聘笔试的典型题目,涵盖算法、数据结构和系统设计等多个方面。不同于普通习题集,它特别剖析了每道题考察的核心能力:比如用“数字游戏”题测试抽象建模思维,用“海量数据处理”题考察分布式计算思路,以及如何用简洁代码实现高效算法。文中不仅给出了标准解法,还对比了不同解题路径的时间与空间复杂度,点明哪些思路更符合谷歌对工程效率的偏好。对于准备技术面试的读者,它提供了一个窗口去理解顶级科技公司如何通过笔试题筛选出兼具理论基础和工程思维的人才。