美团海报生成 AIGC 技术创新与实践
美团平台数百万商家面临海报设计资源匮乏、交付时效苛刻、内容同质化及批量质量失控等困境。AIGC技术为创意平权带来可能,但生成商业可用海报需克服精准文字渲染、和谐版式布局、统一美学风格、多任务场景支持及质量可量化评估等挑战。美团智能创作团队构建了PosterCraft、PosterOmni和PosterReward三大系统形成技术闭环。PosterCraft采用端到端优化,通过四阶段级联训练(包括大规模文字渲染优化、高质量海报微调、美学强化学习及视觉反馈精炼)显著提升文字渲染准确率,接近闭源商业系统水平。PosterOmni针对多任务设计需求,将扩图、补全、比例调整等六类任务统一于单一模型,通过专家训练、任务蒸馏及统一奖励模型进行强化学习,缓解任务冲突并提升编辑与创作能力。PosterReward作为首个海报质量评估奖励模型,构建自动化偏好数据集并通过四阶段级联训练,在专项基准上达到86%准确率,为生成模型提供优化信号并承担线上质检。三项工作全部开源,并在美团外卖套餐图生成、品牌IP设计等业务中落地,有效提升海报生产效率和质量。
从月球漫步到赛博都市,WBench 测出了世界模型的边界
WBench由美团LongCat团队开发,是首个针对交互式视频世界模型的系统性多轮评测基准。该基准包含289个测试案例和1058个交互轮次,覆盖多种世界定义和指令集,如未来城市和油画场景,支持第一人称和第三人称视角。通过测试Kling 3.0、HY-World 1.5等20个前沿模型,发现无全能模型:文本驱动模型擅长场景理解,专用世界模型在交互控制上突出。导航能力与视频画质等其他维度相关性低,依赖独立的空间状态表示;多轮交互中导航能力平均分下降33点,表明位姿误差累积是结构性缺陷。开源模型如HY-World 1.5在导航能力上表现优异。WBench基于世界定义、指令集、统一交互接口和评测套件四大要素构建,实现从被动生成到主动交互的范式转移,其自动评分与人类偏好高度一致,Spearman相关系数达0.94,验证了可靠性。评测维度包括视频质量、设定遵循度等,为世界模型研究提供标准化工具。
美团 BI 在指标平台和分析引擎上的探索和实践
美团BI平台构建了以指标平台为核心的新一代架构,解决传统BI中数据口径混乱、查询性能差等问题。核心能力包括自动语义和增强计算。自动语义实现“定义即研发”,将业务语言解析为结构化逻辑表达,通过主外键关联数仓模型自动形成星型、雪花模型,扩展复杂指标,并贯穿指标定义、模型关联、指标高亮、路由选表及查询语义构建全流程。增强计算通过智能查询服务支持多引擎模型和查询降级策略,以及智能物化自动构建宽表和汇总表,平衡运营监控秒级响应与灵活分析的大数据处理需求。平台还探索增量计算引擎,利用存算分离、弹性伸缩等特性提升性能与稳定性。目前该平台已支持百余业务线,查询量达百万级,成功率超99.9%,并在新引擎评测中验证性能优势。未来将继续深化自动语义和增强计算,推动数据分析智能化。
ACL 2026美团论文精选:从能力评测到推理优化,构建生成新范式
本文精选了ACL 2026会议中6篇与大语言模型相关的论文,聚焦能力评测与推理优化新范式。CoreCodeBench提出细粒度代码智能评测框架,通过仓库级任务解耦评估模型编程能力,覆盖开发、修复等场景,有效性达78.55%。SOP-Maze基于真实业务数据构建复杂标准操作流程评估,分类为侧根和主根系统,揭示模型在深度逻辑推理中的不足,易犯路线盲区和对话脆弱性错误。AMO-Bench设计50道高难度数学竞赛题,确保原创性和奥数级别,评测显示最强模型准确率仅52.4%,凸显推理提升空间。研究过度思考现象,分析推理动态并提出推理完成点检测器,减少冗余生成token。MASPO针对强化学习优化,引入软高斯门控、质量自适应限制器等方法,提升训练稳定性和样本效率。FLR将隐式推理分解为多因子注意力模块,优化生成式推荐性能。这些工作共同推动了大模型在复杂任务中的评测与优化,为未来研究提供关键方向。
用Agent评测思路管理AI Coding —— 31万行代码AI重构的实践
本文分享了一个团队在90%代码由AI生成、系统代码量膨胀至31万行的背景下,如何通过实践管理AI Coding并完成大规模重构的实战经验。文章指出,若无统一规范约束,AI Coding会加速代码腐化。团队提出了三个核心经验:一是借鉴Agent评测的“人人对齐→人机对齐”理念管理AI Coding,先通过规范拉齐团队共识,再将共识转化为AI可执行的约束;二是AI正在重新定义“经验”价值,从依赖人力“看全”代码转向借助AI快速识别问题并由人判断优先级;三是技术债可像业务需求一样,通过拆解到日常迭代中渐进式消化。重构执行路径包括:利用AI辅助定向梳理技术债、制定AI友好研发规范(如工程分层规约)并落地为AI Rule、通过SOP指导AI完成工程解耦、借业务需求平滑升级数据模型,以及建立Pre-PR机制和AI辅助测试用例生成规范以保证质量。整个过程强调规范是AI Coding时代阻止系统腐化的基础设施,为类似场景提供了可复用的方法。
美团发布原生多模态 LongCat-Next:当视觉和语音成为AI的母语
美团开源的LongCat-Next探索了物理世界AI的统一建模路径,旨在让AI像处理语言一样原生处理图像、语音和文本。核心创新在于DiNA(离散原生自回归架构),将所有模态映射为同源的离散Token,并通过下一个Token预测范式进行统一建模,打破了传统多模态模型的拼凑式架构,实现理解与生成的对称优化。dNaViT视觉分词器支持任意分辨率图像编码,利用8层残差向量量化实现28倍像素压缩,同时保持细节保真。语义对齐完备编码器通过大规模视觉-语言监督学习高信息密度表征,结合多级RVQ减少离散化损失,确保离散Token的语义完整性。实验表明,LongCat-Next在细粒度视觉理解、图像生成和音频任务上达到或超越专用模型,如OmniDocBench和MathVista基准上表现优异,同时保持语言能力,在工具调用和代码生成上也有提升。模型开源促进社区发展,推动原生多模态智能走向更远。
突破零样本 TTS 音色克隆上限:LongCat-AudioDiT 的声音克隆艺术
LongCat-AudioDiT 是美团 LongCat 团队推出的端到端文本转语音模型,专注于零样本语音克隆。传统 TTS 系统依赖梅尔频谱等中间表征,导致信息损失和误差累积。该模型创新性地在波形潜空间直接生成,使用 Wav-VAE 将波形压缩为 64 维隐向量,帧率 11.7Hz,通过多级 Oobleck 块和非参数捷径实现高效下采样与稳定训练,优化目标融合多分辨率 STFT 损失等对抗损失。扩散 Transformer(DiT)在隐空间学习条件流匹配,文本编码采用 UMT5 并结合第一层和最后一层隐藏状态以增强语义对齐,同时引入 ConvNeXt V2 模块细化表征。推理机制有双重突破:强制重置提示区域隐变量解决训练-推理不匹配问题,自适应投影引导(APG)替代传统无分类器引导,通过分解引导信号避免音质过饱和。实验表明,在 Seed 基准测试中,LongCat-AudioDiT 取得当前最优的说话人相似度,例如 Seed-ZH 测试集达 0.818,同时保持高可懂度,错误率低。模型以纯波形建模证明绕过中间表征的可行性,并开源促进技术发展。
从高拟真到真可用,LongCat-Video-Avatar 1.5 正式开源
美团开源LongCat-Video-Avatar 1.5,这是一个商业级数字人视频生成模型,在唇形同步、长视频稳定性、多人互动和推理效率上实现全面升级。模型通过将音频编码器从Wav2Vec2升级为Whisper-large,提升音素捕捉精度,使唇部运动更精准平滑,全身动作协调性增强,减少长视频中的抖动和身份漂移。数据体系采用多阶段处理,包括离线标注和在线验证,并构建多人、静默和情绪数据增强,提升模型在复杂场景中的泛化能力。推理优化引入DMD蒸馏技术,将生成步骤从50步压缩至8步,效率提升约15倍,并使用LoRA适配器降低显存开销。逐帧级GRPO偏好对齐进一步优化手部稳定性和动作连续性。性能评测基于EvalTalker基准,由770名评估者参与,结果显示模型在物理合理性、时间稳定性、身份一致性和音视频协调性上领先闭源系统,单人场景得分3.336,多人场景得分2.730,主体变形问题率23.1%,跳帧问题率0.8%。开源旨在促进社区共建,推动数字人视频技术从实验室走向真实应用。
美团 LongCat 开源 General 365:树立推理评测新标尺
美团LongCat团队开源General 365,这是一个针对大语言模型通用推理能力的创新基准。当前大模型在学科推理任务如数学和编程中表现优异,但面对日常逻辑问题时却常缺乏常识,暴露了评测体系的缺陷:过度依赖专业知识记忆,而非真实逻辑推演能力。现有基准如BBH面临模板化和性能饱和问题。General 365通过365道人工原创题目及1095个扩展变体,系统覆盖复杂约束、分支枚举、时空推理等八大挑战类型,知识范围严格限定在K-12水平,以解耦推理与知识检索,纯粹评估模型的逻辑能力。基准设计强调高多样性、高挑战性,并经过严格人工质检和混合评分确保可靠性。实测26款主流模型显示,Gemini 3 Pro以62.8%准确率领先,但仅2款模型及格,揭示了模型在语义干扰和最优策略维度上的普遍短板。跨基准对比表明,模型在该基准上准确率显著下降,输出长度增加,证实其难度源于深层逻辑链条。该项目旨在树立推理评测新标尺,推动大模型向具备通用推理能力的智能体演进,填补了现有评测空白。
LARYBench 发布:定义具身动作表征 ImageNet,首次度量从人类视频学习的泛化表征
具身智能领域面临带动作标注数据稀缺的挑战,机器人泛化能力受限。LARYBench 作为首个系统化评测基准,针对隐式动作表征进行量化评估,旨在从大规模人类视频中学习通用动作语义。该基准通过多粒度动作定义,包括本体动作、原子语义动作和复合语义动作,覆盖超过100万段视频、151种动作类型和11种机器人形态,构建了多样化数据集。评测采用浅层探测头验证表征质量,涵盖动作回归和分类任务。实验对比了隐式动作模型、通用视觉编码器等四类范式,结果表明通用视觉模型如 DINOv3 在动作泛化和控制精度上显著优于专门模型,揭示了动作表征可从海量视觉预训练中涌现。这一发现验证了人类视频数据在驱动规模化学习中的潜力,为具身智能突破数据瓶颈、走向数据驱动范式提供路径。LARYBench 开源了数据集和代码,促进社区协作,加速动作表征研究迭代。
LongCat-Flash-Prover:AI 攻克数学定理证明,不仅要“算得对”,更要“证得严”
LongCat-Flash-Prover是专为数学定理证明设计的大语言模型,旨在从“猜答案”转向“严谨证明”。它采用形式化语言Lean4,将证明过程拆解为自动形式化、草稿生成和证明生成三大原子能力。通过混合专家迭代框架,模型在冷启动和迭代阶段训练不同专家,并结合工具集成推理(TIR)来优化证明质量。在数据合成中,采用课程学习模式,从简单完整证明过渡到复杂引理式草稿证明,提高推理效率。模型还引入多个验证工具,如Lean4 Server、语义一致性检查和Theorem一致性,确保生成证明的语法正确性和语义一致性,防止作弊行为。实验结果表明,LongCat-Flash-Prover在MiniF2F-Test上以72次预算达到97.1%通过率,超越现有开源模型;在MathOlympiad-Bench等竞赛级任务上也取得显著进步。该模型已全面开源,不仅受到AI研究者关注,还引起了数学界的兴趣,有望成为数学研究和教育的基础设施,促进形式化数学的范式创新。
AIOps在美团的探索与实践——故障发现篇
这篇讲的是美团如何将AIOps(智能运维)落地到故障发现环节。文章从自动化运维的瓶颈说起,指出传统基于固定规则的监控在海量、多变的指标面前力不从心,而AIOps通过机器学习从数据中自动学习规则,是更进一步的解决方案。 美团规划了一条从单点能力到流程化、免干预的AIOps演进路径,并强调了SRE、开发与算法三类团队的紧密协作。他们首先聚焦于故障管理体系中的“故障发现”,因为它直接影响告警的准确性和效率。 核心实践在于解决海量时序指标的自动分类问题。团队发现,不同形态的指标(如周期型、平稳型)需要不同的告警策略。通过探索,他们最终采用卷积神经网络(CNN)对指标进行自动分类,准确率超过95%,从而能为指标智能匹配合适的异常检测算法。这不仅降低了人工配置成本,也提升了告警信噪比,为后续的告警收敛、故障定位等环节奠定了智能化基础。
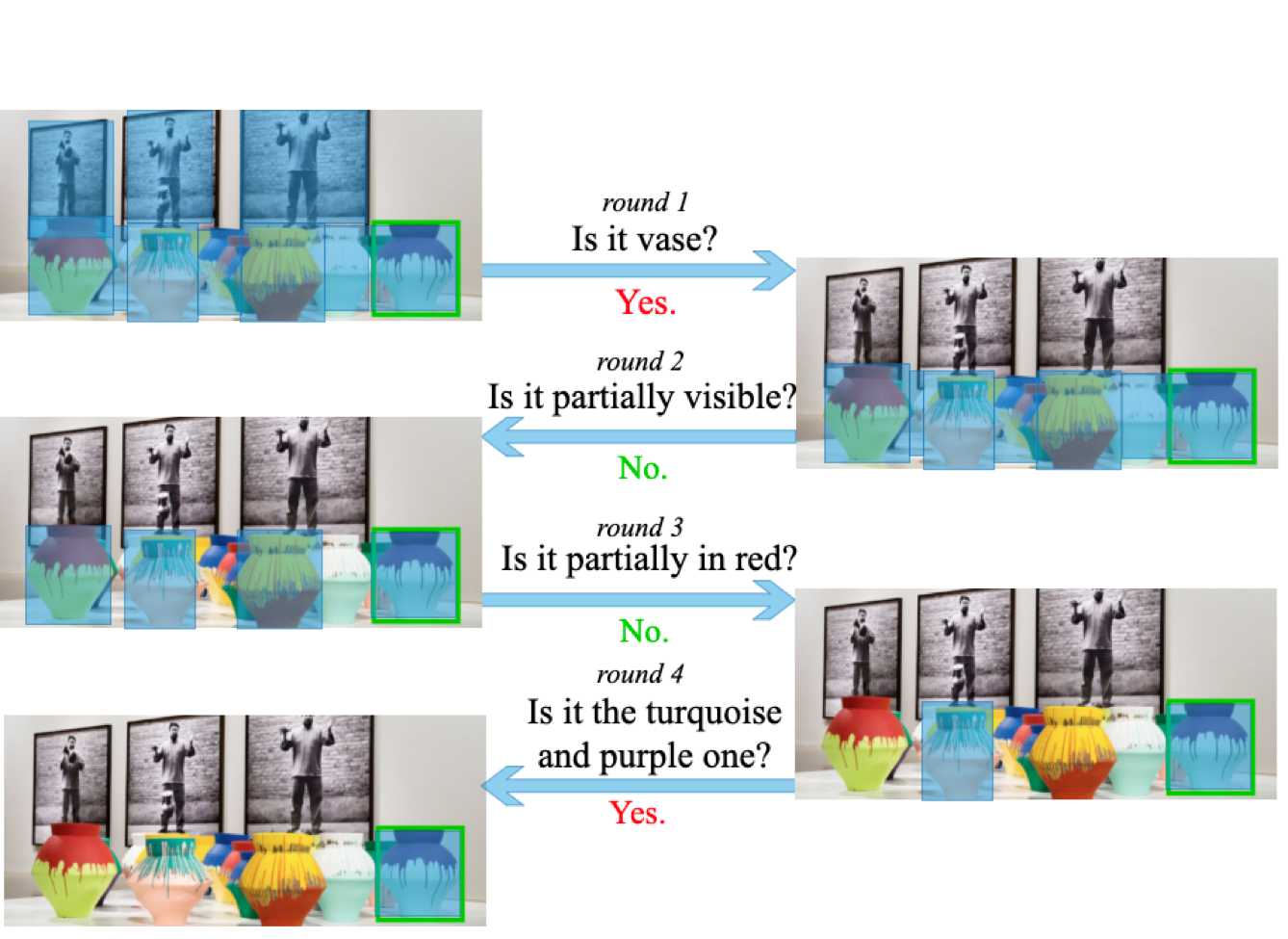
对话任务中的“语言-视觉”信息融合研究
这篇讲的是如何让AI在视觉对话中更“会看眼色”。研究者们针对“目标导向的视觉对话”任务发现,现有模型有个明显短板:对话中的回答(比如“是”或“不是”)对视觉注意力的引导作用太弱。当回答改变时,AI的目光焦点本该相应转移,但旧方法往往只是简单地拼接语言和图像特征,没能突出这种动态调整。 为此,北京邮电大学与美团AI团队合作提出了一个“响应驱动的视觉状态估计器”(ADVSE)。这个模型的核心在于两个新机制:一个是“答案驱动的注意力更新”,它能根据当前回答是肯定还是否定,来决定是聚焦当前物体还是转移目光搜索新目标;另一个是“条件视觉信息融合”,可以自适应地混合图像的全局信息和差异信息。这使得模型能像人一样,根据对话进展灵活调整“看图”的策略。 在国际通用的GuessWhat?!数据集上,这个ADVSE模型在问题生成和回答任务上都取得了当时的最佳成绩。它让机器在需要通过多轮对话寻找目标物体(比如从一堆物品里找出某个)时,对话策略更有效率,也为智能助手或交互机器人等应用提供了更扎实的技术基础。