Mysql+sphinx+中文分词简介(ubuntu)
这篇指南聚焦于在Ubuntu系统上搭建一套基于MySQL和Sphinx的高效中文搜索方案。作者从实际项目需求出发,指出原生MySQL在面对中文全文搜索时存在的性能与精度瓶颈,而Sphinx正是解决这一问题的利器。文章的核心方案是将Sphinx作为独立的搜索引擎,与MySQL数据库进行集成,从而对外提供快速、准确的中文检索服务。关键的技术点在于如何正确编译Sphinx并为其配置适合的中文分词插件,以克服中文语义的复杂性。文章会逐步引导读者从配置编译环境开始,完成Sphinx的构建与基础优化,并重点探讨分词工具的选择与集成细节。最终,读者可以掌握搭建这套组合拳的完整流程,理解各组件如何协同工作来满足中文搜索场景下的特定需求。
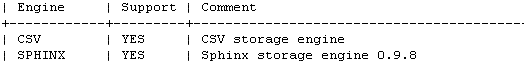
《解剖PetShop》系列之六
这篇文章延续了“解剖PetShop”系列的风格,将焦点对准了经典的PetShop示例程序的表示层设计。作者没有停留在简单的界面展示,而是深入拆解了其背后的架构逻辑,剖析了如何将MVC(模型-视图-控制器)模式具体应用到一个实际的电子商务项目中。 文章核心会讲清楚PetShop如何通过表示层将业务逻辑与用户界面解耦,具体到控制器如何分发请求、视图如何渲染数据,以及模型如何封装业务状态。你将看到,看似简单的页面跳转和数据绑定背后,是一套清晰、分层的协作机制。这种设计不仅使得PetShop的UI部分易于维护和扩展,也为理解大型.NET应用的分层架构提供了一个非常扎实的范本。 对于想学习企业级应用分层思想、或者正在重构自己项目UI逻辑的开发者来说,这篇源码分析提供了一个非常经典且具体的实现参考,能帮助你看清从设计模式到代码落地之间的完整路径。
《解剖PetShop》系列之五
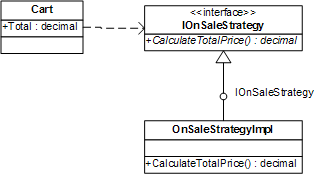
这篇是《解剖PetShop》系列的第五篇,聚焦于经典案例PetShop的业务逻辑层(BLL)设计。作者深入剖析了该层如何作为系统的核心枢纽,协调表示层与数据访问层,处理订单、购物车、产品检索等关键业务流程。 文章的核心在于揭示PetShop BLL的实现思路。它巧妙地运用了“外观模式”来简化复杂业务逻辑的接口,使调用方无需关心底层细节。同时,通过“策略模式”封装了不同业务规则(如不同类别的商品定价策略),使得业务逻辑的扩展与维护变得灵活。更值得一提的是其依赖倒置原则的应用——BLL依赖于数据访问接口而非具体实现,这大幅降低了层间耦合度。 尽管PetShop是一个有一定年代的示例,但它对职责分离、接口设计与模式应用的探讨非常扎实。对于想理解经典分层架构中业务逻辑层应承担何种角色、如何设计才能既清晰又灵活的开发者来说,这篇解析提供了一个极具参考价值的实践蓝图。
《解剖PetShop》系列之四
这篇讲的是作者如何深入拆解经典PetShop项目中的ASP.NET缓存机制。作为系列的第四篇,它聚焦于一个性能优化的核心议题:在典型的电商应用场景下,如何智能地缓存数据与页面,以减轻数据库压力、提升响应速度。 作者并非泛泛而谈缓存概念,而是直接切入PetShop的代码实现。文章会剖析它如何利用`Cache`对象缓存产品列表、订单状态等频繁访问的数据,并探讨了不同缓存策略(如绝对过期与滑动过期)在商品详情页、用户信息等不同场景下的具体应用选择。其中的巧妙之处在于,PetShop展示了如何将缓存作为业务逻辑与数据访问层之间的“润滑剂”,在保证数据基本新鲜度的前提下,最大化复用静态化内容。 对于想理解缓存在真实企业级项目中如何落地、而非停留在理论层面的开发者,这篇文章提供了一个极具参考价值的剖析视角。
《解剖PetShop》系列之三
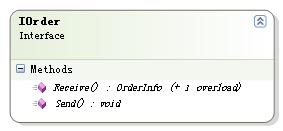
这篇讲的是经典应用PetShop系列解析的第三篇,作者将视角聚焦在数据访问层中一个常被忽视但至关重要的设计——消息处理机制。 文章没有停留在CRUD的常规操作上,而是深入剖析了PetShop如何通过消息队列(很可能是MSMQ)来解耦业务逻辑与数据操作。作者从具体的代码实现出发,解释了在提交订单等关键流程中,系统如何将耗时的数据持久化操作转化为异步的消息发送。这不仅提升了用户界面的响应速度,也增强了系统的整体健壮性。 核心实现思路在于引入一个中间的消息服务层,将“创建数据”的指令与“执行数据操作”的实际过程分离开来。这种设计的巧妙之处在于,它用相对简单的消息传递模式,优雅地解决了一致性、性能和可靠性的平衡问题。即使在高并发场景下,后端数据处理也能按照自己的节奏有序进行。 读完你能理解,一个设计良好的分层架构,其价值不仅在于划分清晰的模块边界,更在于能通过像消息这样的“粘合剂”,在层与层之间实现灵活而高效的通信。这对思考现代微服务架构下的异步通信,依然有非常直接的借鉴意义。
《解剖PetShop》系列之二
这篇讲的是如何从PetShop经典案例中拆解出实用的数据库访问设计思路。作者没有停留在泛泛而谈的分层概念上,而是直接聚焦于数据访问层(DAL)的核心——如何让代码优雅地与不同数据库打交道。 文章细致剖析了PetShop的解决方案:它通过定义统一的IDAL接口来抽象数据库操作,再配合工厂模式,让具体的数据库实现(如SQL Server、Oracle)在运行时被动态加载。这种设计彻底解耦了业务逻辑与底层数据存储,更换数据库时无需修改上层代码。更巧妙的是,配置文件中简单切换一下字符串,系统就能指向完全不同的数据库实例,展现了“依赖倒置”原则的经典应用。 作者还指出了这种模式的权衡之处,比如对于复杂查询可能带来的性能或灵活性挑战。整篇分析从代码结构到配置细节,把一套十几年前的设计如何做到清晰、可扩展讲得非常透彻,对理解当下依然适用的分层与抽象思想很有启发。
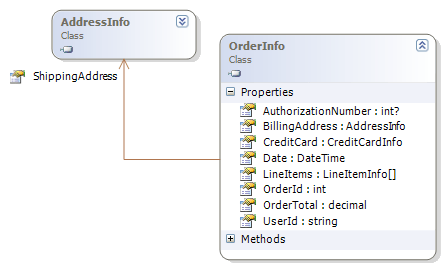
《解剖PetShop》系列之一
这篇讲的是微软经典案例PetShop的系统架构设计——一个常被用来演示.NET技术能力的宠物商店应用。作者没有停留在功能介绍,而是从架构视角深入剖析:面对一个需要处理商品浏览、购物车、订单支付等完整电商流程的系统,如何通过分层架构(UI、业务逻辑、数据访问)实现清晰解耦,以及如何在业务逻辑层组织不同模块(如产品、订单、用户)的交互。文章具体展示了PetShop如何利用ASP.NET处理前端请求,通过业务实体层传递数据,并最终借助ADO.NET和SQL Server完成持久化。 值得注意的巧妙之处在于,它并未追求过度设计,而是用务实的结构解决了电子商务系统的核心关注点:如何让各部分职责明确、易于维护和扩展。对于想理解“如何将一个完整业务系统拆解为可管理模块”的开发者来说,这种从实际案例出发的架构拆解,比抽象理论更直观有用。
通过HttpListener实现轻量级Web服务器[原创]
这篇讲的是作者在研读C#版BT协议实现MonoTorrent的源码时,从其Tracker模块里“挖”出一个实用亮点——基于HttpListener实现轻量级Web服务器。HttpListener是.NET框架自带的类,常被忽略,但它能快速搭建一个无需IIS等重型依赖的HTTP服务端,代码量极少,非常适合在本地服务、临时工具或测试环境里“救急”。 作者没有停留在理论层面,而是单独将这段逻辑提取出来,编写了测试代码并验证了其可用性。这个实践点出了它的核心价值:当你在做P2P通信、本地数据交互等场景,需要快速起一个简单的HTTP接口时,这比部署一个完整的Web服务器要灵活高效得多。文章用亲身经历说明,有时翻阅优秀项目的源码,除了学习架构,也能发现这种直接可用的“瑞士军刀”。
Mysql+sphinx+中文分词简介(ubuntu)
这篇讲的是如何在 Ubuntu 系统上,整合 MySQL 数据库、Sphinx 搜索引擎与中文分词技术,搭建一套完整的中文全文检索方案。作者从实际需求出发,系统性地讲解了这一组合的配置流程。 文章的核心是方案的实施路径。它从编译环境的必要准备讲起,逐步引导读者完成 Sphinx 对 MySQL 的索引创建,这部分是基础。更重要的是,文章深入到了中文处理的关键——如何为 Sphinx 配置合适的中文分词支持,这决定了最终搜索结果的质量与相关性。 具体而言,内容涵盖了从依赖项安装、Sphinx 编译,到索引配置文件的编写细节,以及如何让分词器正确识别中文。这相当于提供了一份从零开始的搭建指南,尤其适合希望为 MySQL 数据库增加快速中文搜索功能的开发者参考。 最终,通过这样的配置,一个基于 MySQL 存储、Sphinx 加速的搜索后端得以成型,能够实现高效、精准的中文全文检索,解决了原生 MySQL 在中文搜索场景下的性能与功能瓶颈问题。