从设计到策划的成长之路
这篇讲的是作者如何从一名UI设计师,逐步拓展技能边界,最终成长为一名能独立负责完整项目的产品策划的历程。早期,作者专注于像素级还原和视觉表现,但很快发现,单纯的设计执行无法解决产品中的根本性体验问题。核心的转变在于,他开始主动跳出设计工具的局限,去理解业务逻辑和用户场景。 作者分享了自己在项目中遇到的真实挑战:比如如何说服产品和开发接受一个看似增加成本的设计方案,又或者如何在资源有限时定义功能的优先级。他意识到,设计是“如何解决问题”,而策划更侧重于“定义什么问题值得解决”。为了跨越这道坎,他系统地学习了产品方法论,并刻意在每次设计评审中,从单纯阐述“为什么这样好看”转向论证“为什么这样有效”。 这段经历的核心启发在于,职业成长往往不是线性的技能堆叠,而是认知框架的扩展。从设计到策划,关键的一步是建立全局视角,学会用商业和用户价值的语言来包装自己的设计思考。对于许多在专业领域遇到瓶颈的技术或设计人员而言,这种主动打破岗位边界、理解上下游逻辑的思维,或许比掌握某个具体工具更为重要。
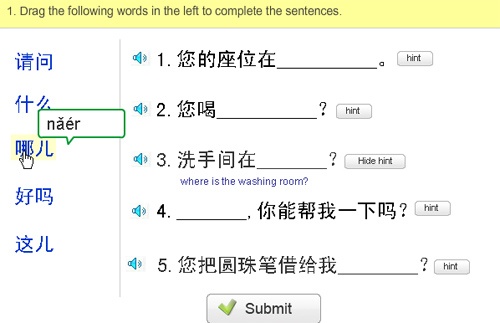
本机暂存