低级程序员和高级程序员的区别
这篇讲的是程序员能力差异背后的关键分水岭。作者从常见的误解切入:许多人以为高级程序员只是“写代码更快、bug更少”,但实际上,真正的分野在于看待问题的方式。 文章以网络购票系统为例做了生动对比。一个典型的“低级”实现可能99%的时间都运行良好,但它把订单状态简单交付给一个网络请求。高级程序员会立刻想到:网络是不可靠的,请求的每一步都可能中断。正确的做法不是假设TCP协议“绝对可靠”,而是将每一次交互都视为可能失败,并从逻辑上设计补偿机制——比如引入独立的对账进程,通过“重试”和“状态确认”来保证系统最终一致性。 作者指出,高级程序员之所以高级,在于他们深刻认识到bug的必然性,并致力于用严谨的逻辑与系统抽象,构建一个滴水不漏的防御体系。这不仅仅是编码技巧,更是一种面对复杂性的设计哲学。
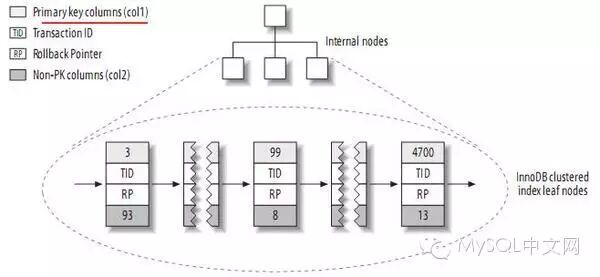
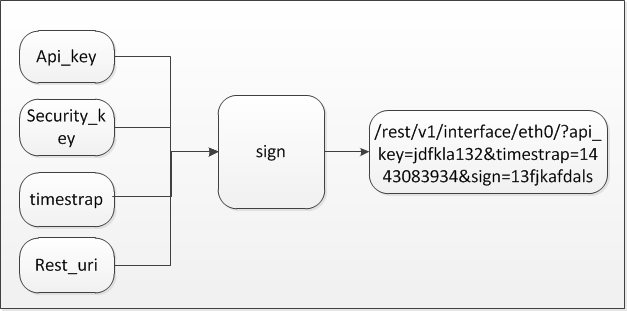
本机暂存