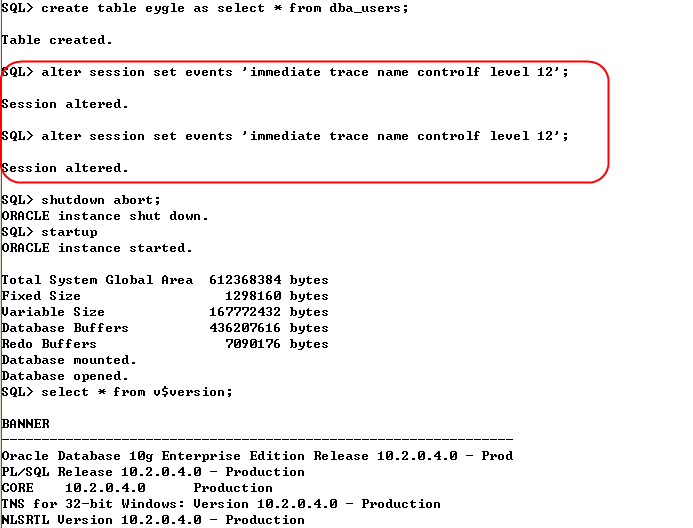
oracle字符集理解
这篇讲的是Oracle数据库中字符集的概念与选择。作者从字符集如何影响数据存储和处理的基本原理出发,深入剖析了不同字符集,比如AL32UTF8与ZHS16GBK,在存储效率、字符支持范围以及兼容性上的关键差异。 文章具体阐释了Unicode字符集(如AL32UTF8)如何统一支持多语言,并在国际化场景中避免乱码问题;同时也对比了传统本地字符集(如ZHS16GBK)在特定环境下的存储空间优势。通过实例说明了字符集转换可能带来的数据截断风险,以及数据库迁移或开发时选错字符集导致的实际故障。 最终,文章给出了明确的选型建议:新系统应优先考虑UTF-8以保障通用性,而对已有中文专用的旧系统,则需谨慎评估迁移成本与收益。这对于正在规划数据库架构或处理遗留系统数据的工程师来说,提供了清晰的技术决策依据。