Linux内核代码中的脏话统计
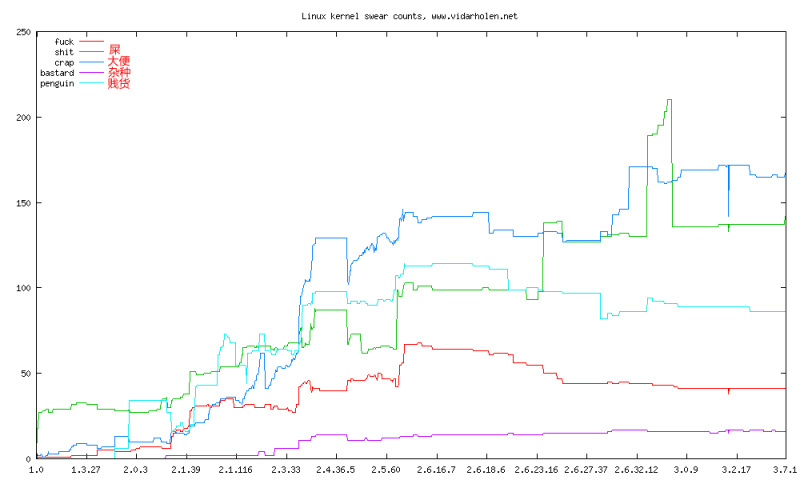
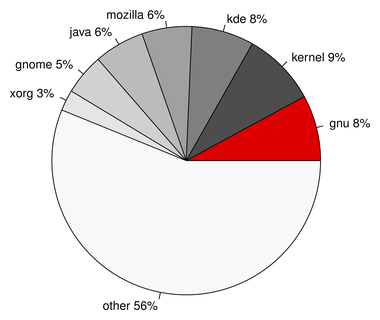
这篇讲的是作者从一个已停更的“the linux kernel fuck count”项目获得灵感,对Linux内核的C、H及汇编源代码进行了一次系统的脏话统计分析。作者按版本号,分别从脏话的绝对数量和代码行的脏话密度两个维度绘制了图表。 数据呈现了一个有趣的趋势:从2.4版本开始,脏话的绝对数量显著攀升。然而,考虑到同期内核代码总量也在激增,折算下来,平均每行代码的“脏话密度”反而是在下降的。文章坦诚地分享了统计方法的局限,比如会将词中包含的词也计入,以及受FreeBSD正则引擎内存泄漏的影响未能优化。 作者最终开源了统计脚本,但也自嘲其代码质量混乱。这本质上是一次用独特视角审视开源社区文化的趣味实践,既看到了开发者情绪的外露,也反映了代码库膨胀带来的稀释效应。