Android 性能优化必知必会
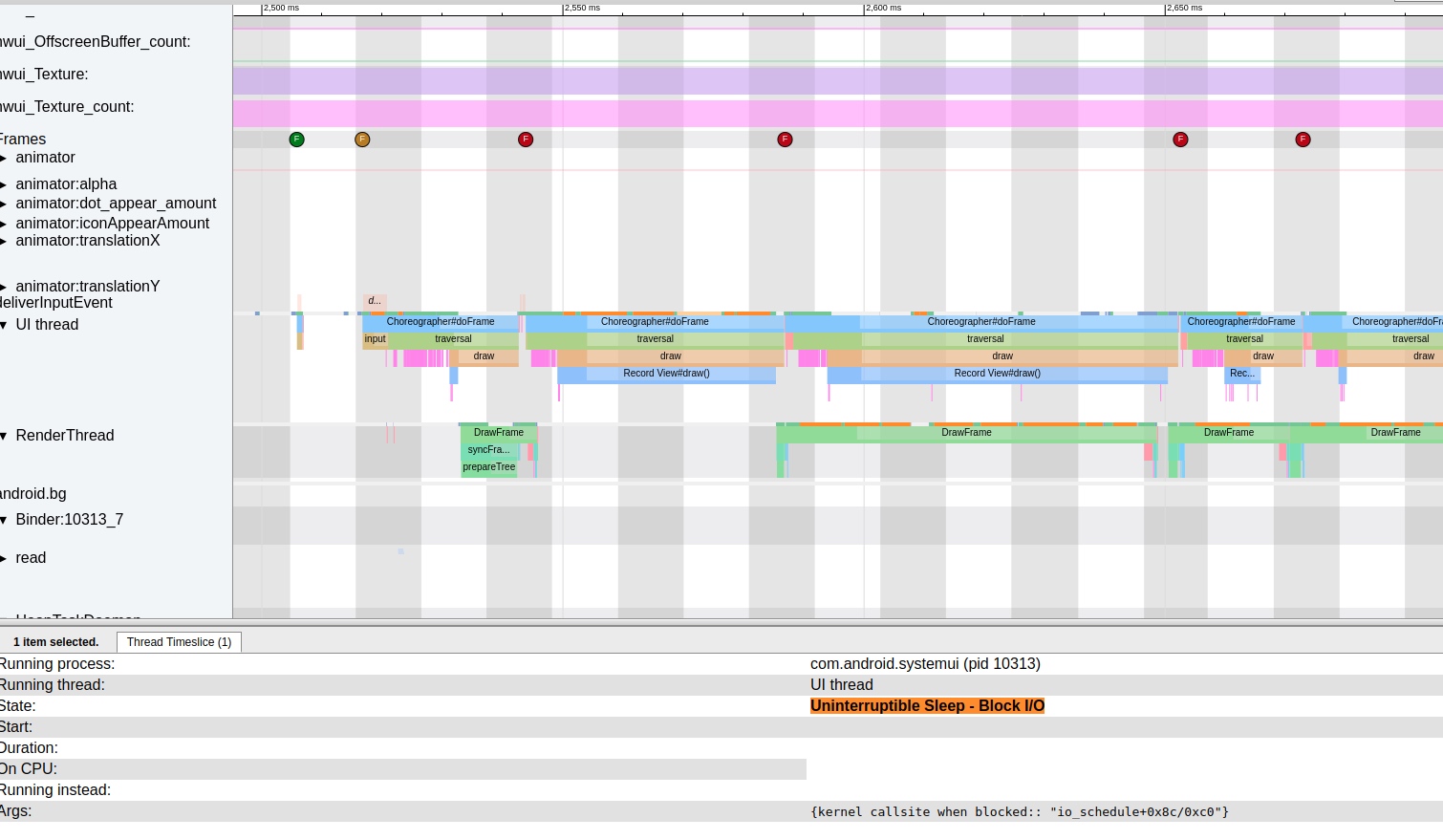
这篇讲的是Android性能优化的全面知识体系与资源导航。作者基于多年一线经验,坦言性能优化牵涉面广、挑战巨大,因此将自己积累的大量优质技术文章和文档汇总成文,旨在帮助新人快速入门,也作为个人知识的梳理与更新。 文章内容扎实,从“优化心得和经验”到“响应速度”等多个维度,系统性地整理了开发者必知的知识点。其中不仅包含Google官方的性能模式课程与开发指南,更汇集了美团、手机淘宝、微信、支付宝等一线大厂的实战复盘,如手淘全链路性能优化、微信内存优化、支付宝启动优化中的垃圾回收处理等深度实践。 此外,文章还提供了诸如Matrix TraceCanary卡顿监控、I/O质量检测、以及基于二进制文件重排的启动优化等具体技术方案的入口。整个资源库持续更新,为从事系统开发与优化的工程师提供了一份清晰的学习地图和问题解决参考。