怎样用core文件调试你的linux程序?
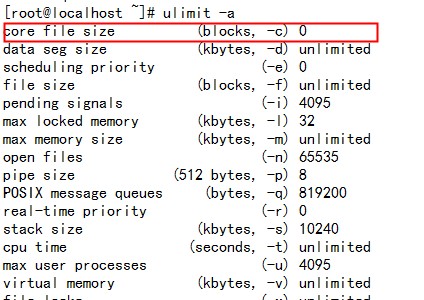
这篇讲的是如何配置Linux系统,让它能在程序异常崩溃时自动生成核心转储(core dump)文件,从而方便你找出程序崩溃的具体原因。 作者从默认Linux禁止生成core文件这个常见限制出发,一步步演示了解锁方法。核心是使用`ulimit -c unlimited`命令,但文章也特别指出了它的临时性——设置仅对当前会话有效,重启或重登就会失效。如果想要更持久的配置,可以修改`/etc/profile`,不过作者也留下了思考:为什么不推荐这样做呢? 更深入的配置在于控制core文件“生在哪里”和“叫什么名字”。文章详细讲解了通过编辑`/etc/sysctl.conf`文件,设置`kernel.core_pattern`参数来实现。例如,将核心文件统一生成到`/tmp`目录,并使用包含程序名、进程ID、信号值等信息的规则来命名,这对于同时调试多个程序非常方便。 最后,文章点明了核心文件的归宿:使用强大的gdb调试器载入这个文件,就能回溯程序崩溃现场,定位问题代码。整个流程非常实用,是每个Linux开发者都应该掌握的调试技巧。