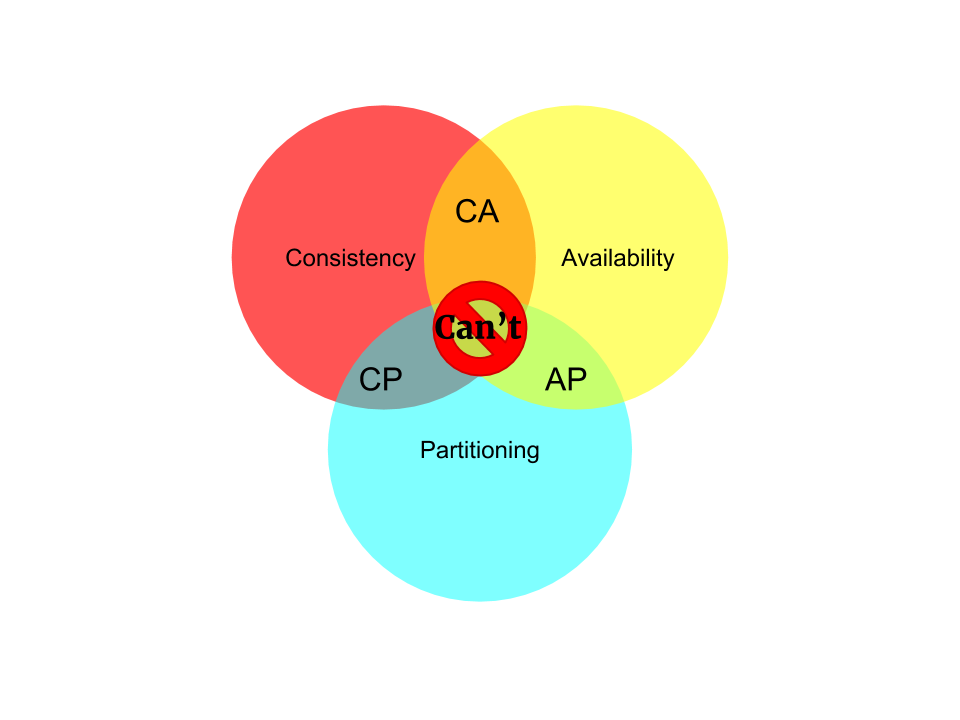
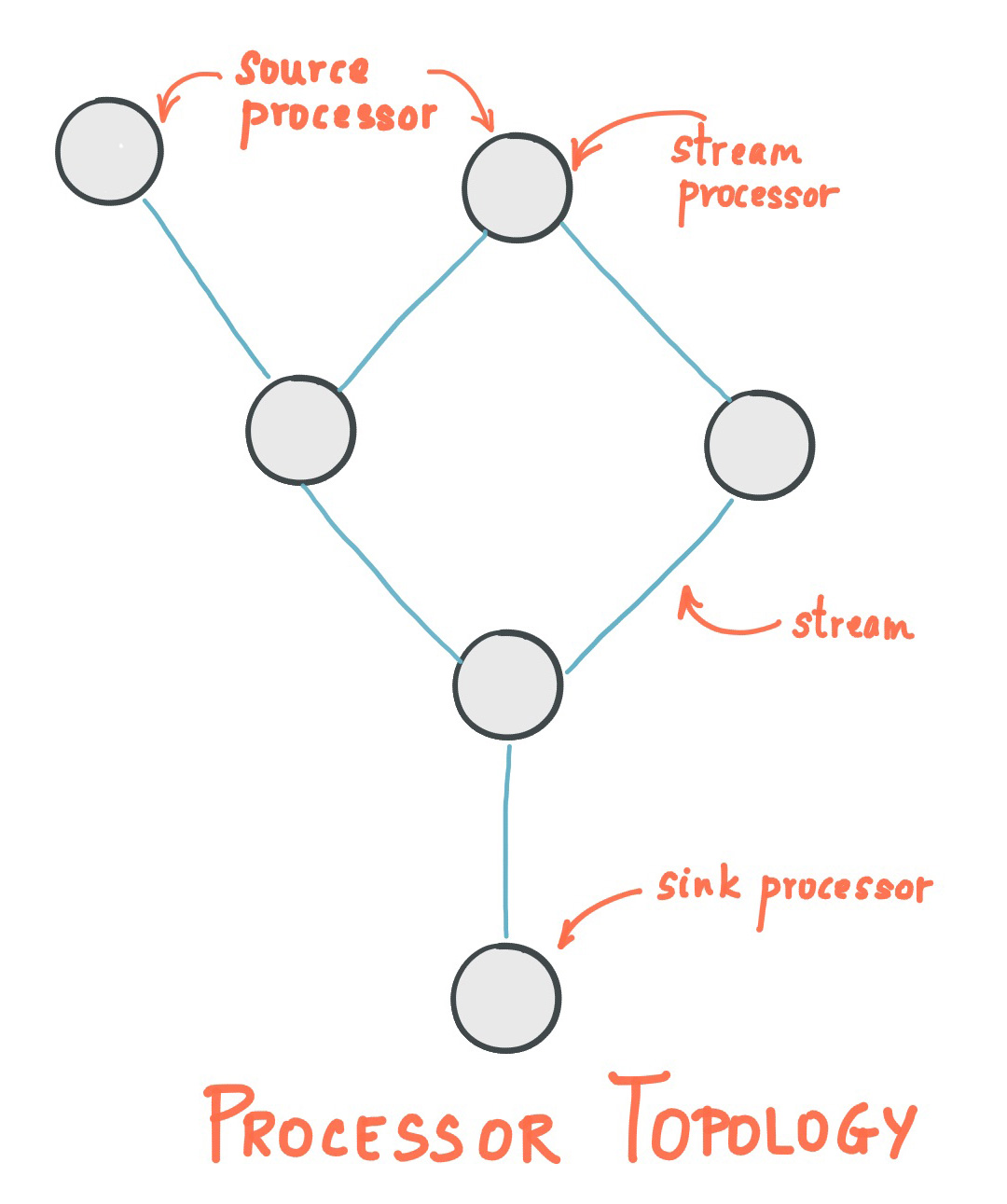
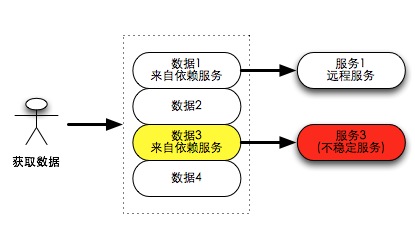
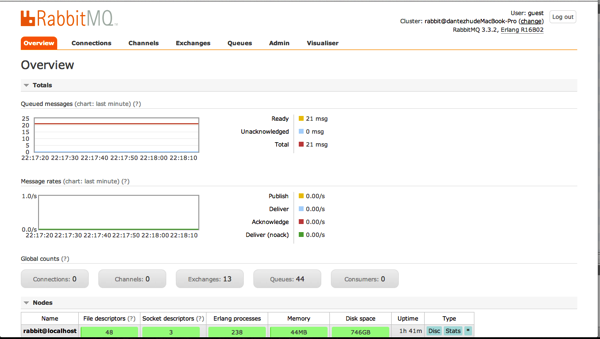
科技爱好者周刊(第 402 期):我在智念 AI 的日子(小说)
小说'我在智念 AI 的日子'通过虚构叙事,刻画了科技公司高度依赖AI的日常场景:员工使用编程代理如Claude自动生成代码与文档,Token消耗成为生产力指标,但代码审查缺失导致生产环境错误频发。故事中,开发者老张同时运行六个AI代理处理前后端任务,却无法解释幻灯片内容,会议沦为形式;代码合并链条涉及产品经理、开发者和代理,无人审查引发通知服务故障。周四主角尝试独立思考却感到困难,突显AI依赖对认知能力的侵蚀。科技动态部分提及AI生成虚假种子图片和特斯拉限制AI支出,反映AI应用的广泛性与成本挑战。文章列表涵盖设计模式、API设计等,显示开发者在效率与质量间寻求平衡。周刊以故事结合资讯,警示过度AI化可能带来效率假象与质量问题,强调在开发流程中需保持人类监督与批判性思维。