逻辑回归算法学习与思考
这篇讲的是逻辑回归算法的原理与实现。作者从算法的“分类边界拟合”核心思想切入,细致拆解了预测函数h(sigmoid)与损失函数J(θ)的设计逻辑。文章不仅推导了梯度下降优化θ的数学过程,还将其向量化,并对照《机器学习实战》中的Python代码进行解读,让公式与实现一一对应。在实际应用部分,作者以sklearn库为例展示了模型调用流程,并特别结合网络安全场景进行了预测分析。整体上,文章完成了一条从数学推导到代码实现,再到领域应用的学习路径,适合想扎实掌握逻辑回归的读者。
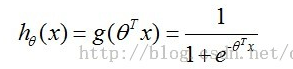
共 3 篇相关文章
这篇讲的是逻辑回归算法的原理与实现。作者从算法的“分类边界拟合”核心思想切入,细致拆解了预测函数h(sigmoid)与损失函数J(θ)的设计逻辑。文章不仅推导了梯度下降优化θ的数学过程,还将其向量化,并对照《机器学习实战》中的Python代码进行解读,让公式与实现一一对应。在实际应用部分,作者以sklearn库为例展示了模型调用流程,并特别结合网络安全场景进行了预测分析。整体上,文章完成了一条从数学推导到代码实现,再到领域应用的学习路径,适合想扎实掌握逻辑回归的读者。
这篇讲的是在信息爆炸的当下,如何应对搜索结果泛滥导致的“选择困难症”。作者指出,单纯的海量结果已不再是优势,真正的挑战在于信息过载时,用户如何能更精准、更高效地定位所需。 文章将焦点落在了“框计算”的垂直搜索领域,并特别聚焦于“统计”这一核心手段。它探讨了如何通过对搜索行为、结果分布及内容特征进行系统性统计分析,来构建更智能的分类与排序机制。这不仅关乎算法优化,更是一种理解用户意图与信息结构的思路。 具体来说,作者可能从日志分析、查询聚类或结果评分等角度,阐述统计模型如何被用来过滤噪音、提炼关键信号,从而让搜索引擎提供的不再是杂乱无章的列表,而是经过初步梳理、富有脉络的“答案”。这种基于统计的深度加工,旨在将浩瀚信息转化为结构化知识,直接缓解用户的茫然感。
这篇讲的是互联网信息组织的两种基础方式——分类与标签。文章以一幅生动的“Web 2.0地图”图片为引子,指出标签已经成为网络2.0时代用户参与和内容多元化的象征。 作者从互联网信息爆炸的背景出发,解释了分类系统(如传统的网站目录)是一种预设的、层级化的信息归档方式,它由管理员定义,结构清晰但相对僵化。而标签则是由用户自由添加的、扁平化的元数据,它更灵活、能反映多元视角,体现了从“权威定义”到“大众协作”的Web 2.0核心思想转变。文章进一步分析,分类擅长构建稳定的知识框架,而标签则擅长发现内容之间的非正式、跨领域关联。 通过对比,作者揭示了二者在信息发现、内容管理与社区构建上的不同作用,帮助我们理解从门户时代到社交时代,信息组织逻辑是如何演变的。