修复 MySQL 编码问题
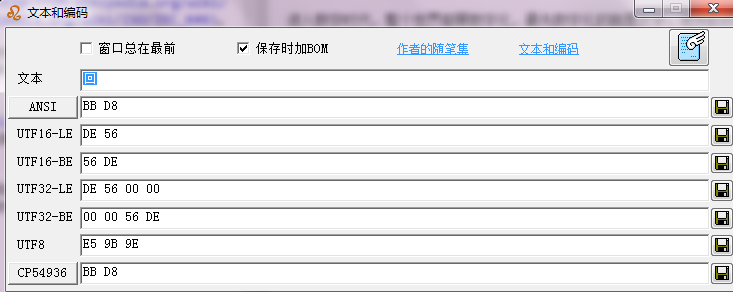
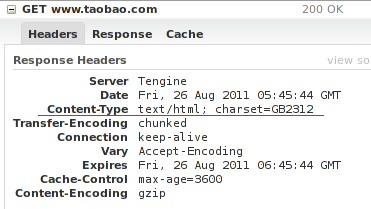
这篇文章讲的是一个技术人在升级MySQL后遭遇的乱码危机。作者发现自己的博客内容全都变成了乱码,查看建表语句后发现问题根源:数据表以latin1字符集存储了UTF-8编码的内容。 传统的ALTER TABLE转换方案效果不佳,于是作者转向了更灵活的mysqldump与重新导入策略。他先用 `mysqldump --default-character-set=latin1` 将数据按原貌导出,避免二次错误编码;接着通过sed命令将导出文件中的字符集声明从latin1批量替换为utf8;最后删除SET NAMES latin1语句,用utf8编码重新导入。这套组合拳成功将数据“救”了回来,避免了更糟糕的情况(如使用zfs回滚)。 整个过程清晰展示了面对编码“坑”时,如何通过理解底层原理(字符集与连接设置)来设计修复方案,而不仅仅是依赖单一命令。对于同样遭遇字符集问题的开发者,这份具体可复现的操作记录提供了直接的解决思路。