个性化实时计算系统及其应用探索
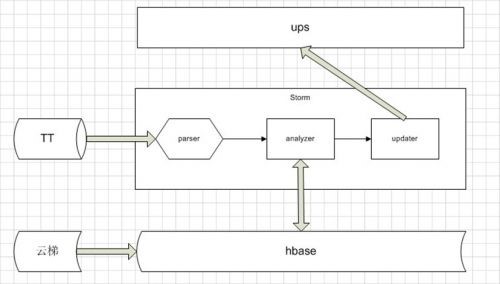
这篇来自阿里技术团队的文章,分享了他们如何应对电商场景下用户兴趣实时变化的挑战。作者从淘宝搜索个性化的实际需求出发,介绍了团队设计的个性化实时计算系统PORA。 PORA是一个基于HBase与Storm的实时流计算系统,其核心在于从日志通道订阅用户行为,并通过三个Storm组件(解析、计算、更新)快速完成数据处理与存储,端到端延迟约300毫秒。这种“离线计算、实时服务”的架构,使得应用方能便捷地获取到用户最新的兴趣偏好。 文章重点阐述了系统在搜索重排序等场景的应用:在商品的相关性排序基础上,融入用户的性别与价格偏好进行个性化调整。实验数据表明,该方案上线后使整体成交金额提升了约2%,其中客单价的提升尤为明显。但作者也客观地指出,由于能获取明确性别画像的用户和Query占比有限,点击率与转化率的提升尚未达到预期。 最后,文章探讨了未来的优化方向,包括深化更多偏好维度的挖掘,以及通过动态调整个性化商品的展现比例与混合排序来提升用户体验。