面试题 – 为什么我的朋友圈不见了?
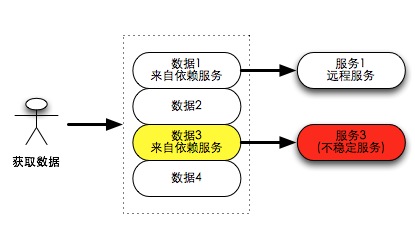
这篇文章从一个常见但棘手的分布式系统问题切入:当一个数据聚合服务需要从多个远程服务获取数据,而其中一个服务不可用时,架构师应该如何选择容错策略? 作者详细剖析了三种典型方案。方案一是直接忽略失败的部分数据(优雅降级),虽然损失最小,但可能导致用户体验不确定。方案二是遇到任何失败就返回整体错误(503),完全依赖调用方的缓存与容错能力,否则用户会看到白屏。方案三则是自定义返回格式,显式告知哪些数据加载成功、哪些失败,但这大大增加了前后端的复杂度。 文章并未止步于此,而是进一步引入了“未读数”这一常见功能,将问题场景变得更复杂:即使主数据列表因服务不稳定而缺损,如果能单独提供一个准确的未读数,用户体验和系统效率会如何变化?这使得对三种方案的权衡更加微妙。 整篇文章的核心价值,不在于给出唯一答案,而是系统性地呈现了架构师在“数据完整性”、“用户体验”、“系统复杂度”和“服务可靠性”之间必须进行的现实权衡。它启发我们思考,在微服务架构下,如何设计既健壮又不过度复杂的容错机制。