抽奖类活动项目的一些技术Tips
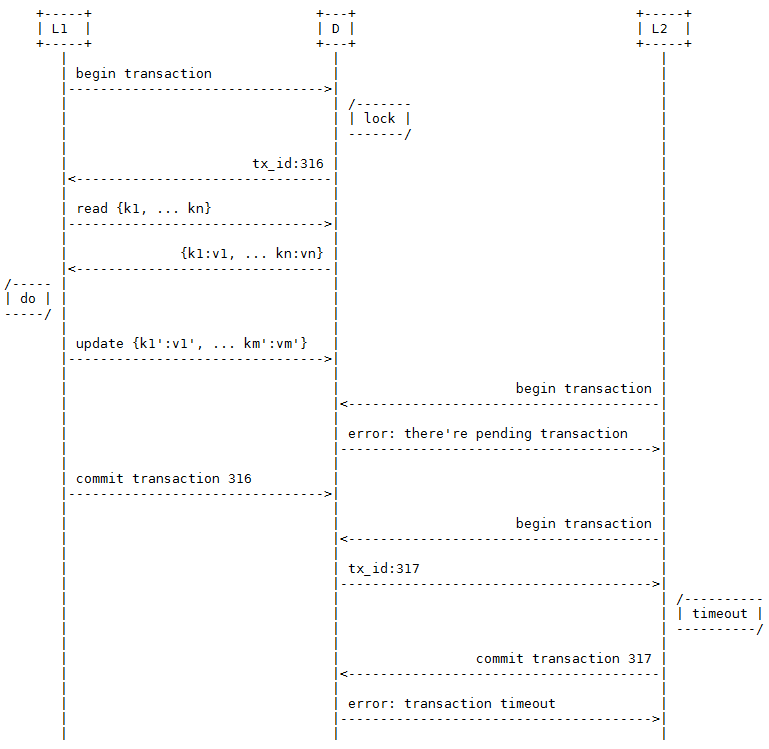
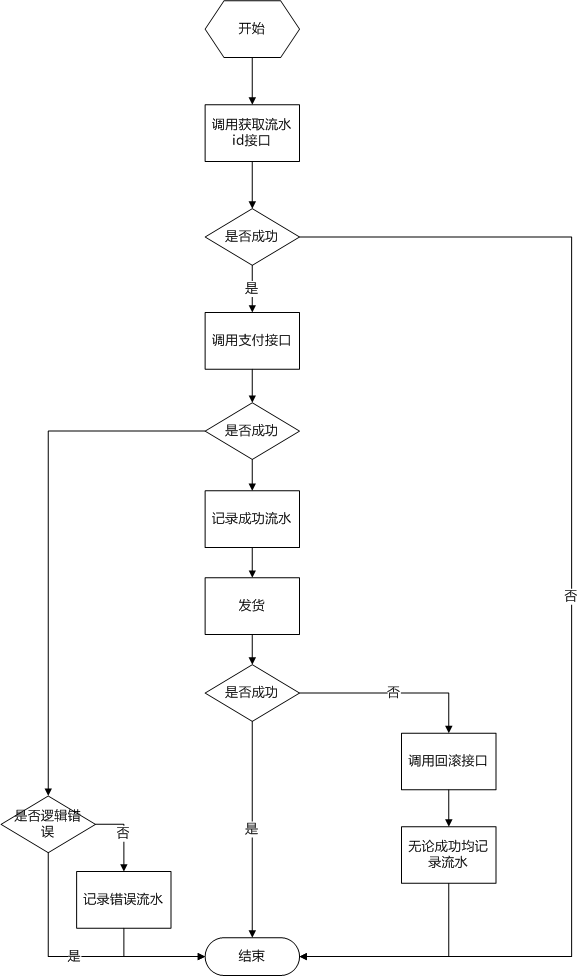
这篇文章分享了设计高并发抽奖活动系统时,如何通过关键技术点来抵御刷奖风险、保障活动稳定性的实战经验。 作者从互联网抽奖活动常面临专业刷奖团伙的真实背景出发,系统性地提出了五层防护建议。核心思路是保持系统简单可靠:接入层用缓存(如Redis)限制IP和用户抽奖频率,避免直接冲击数据库;代码层采用最简单的算法做初筛,将最终发奖逻辑下沉至数据库层;数据层则采用“每日奖池”模式,强调使用有符号整型并利用事务与行锁(如 FOR UPDATE)确保奖品数量扣减的准确与并发安全。 此外,文章还给出了非常务实的运营建议,比如选择白天发放奖品、细化每个时间点的投放量,以及保留充足的活动规则解释空间。整体来看,这套从接入、逻辑、数据到测试的完整实践,对保障线上抽奖类活动的健壮性与公平性具有很高的参考价值,能帮助开发者避免很多“坑”。