聊聊多线程程序的load balance
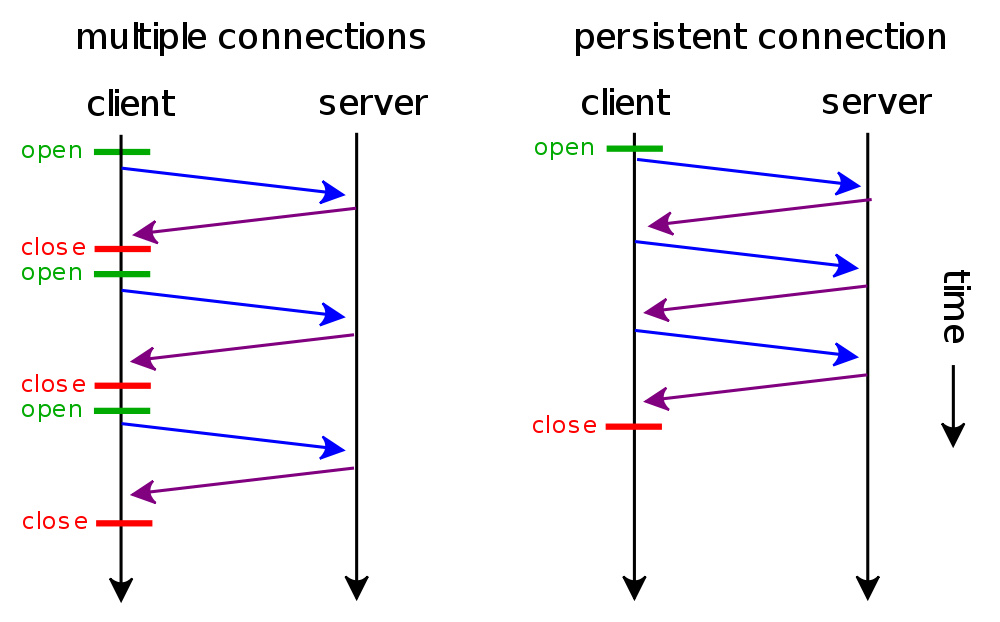
这篇讲的是,如何在一个常见的“接收者-工作线程池”模型中,主动优化负载均衡以提升性能。作者从一个大家熟悉的设计出发:一个 receiver 线程接收请求,放入队列,通过条件变量唤醒任意一个 worker 处理。他敏锐地指出,完全依赖内核的调度和负载均衡可能带来问题。 核心问题有两个:如果 worker 线程远多于 CPU 核心数,唤醒时几乎无法均匀分配到不同 CPU,导致某些核过载而某些核空闲,形成“伪并发”。其次,即使 worker 数量合理,内核的负载均衡也未必能确保将任务分配到不同的物理核心(避免争抢共享缓存和计算资源)。 对此,作者提出了应用层的“微调”方案。一方面,将 worker 线程数控制在接近或略小于 CPU 核心数。另一方面,更关键的是,通过线程绑定(affinity)固定 worker 在特定 CPU 上,并设计一个分级的条件变量唤醒机制。这能确保新任务被优先分配给空闲或低负载物理核心上的 worker,从而主动实现更优的负载分布。 文章通过精心设计的实验验证了结论。例如,将 worker 线程数从 240 降至 24 后,CPU 利用率从 2200% 提升至接近 2400%。启用绑定线程和分级唤醒后,处理 12 个并发任务时性能得到进一步提升。作者也发现,对于依赖内存缓存的任务(如 mmap 读文件),让 worker 集中在相邻 CPU 上反而可能提升性能,这体现了负载均衡策略需具体场景具体分析。 作者通过细致的对比实验表明,这些在应用层主动进行的微调,有时能取得比等待内核调度更优的效果。