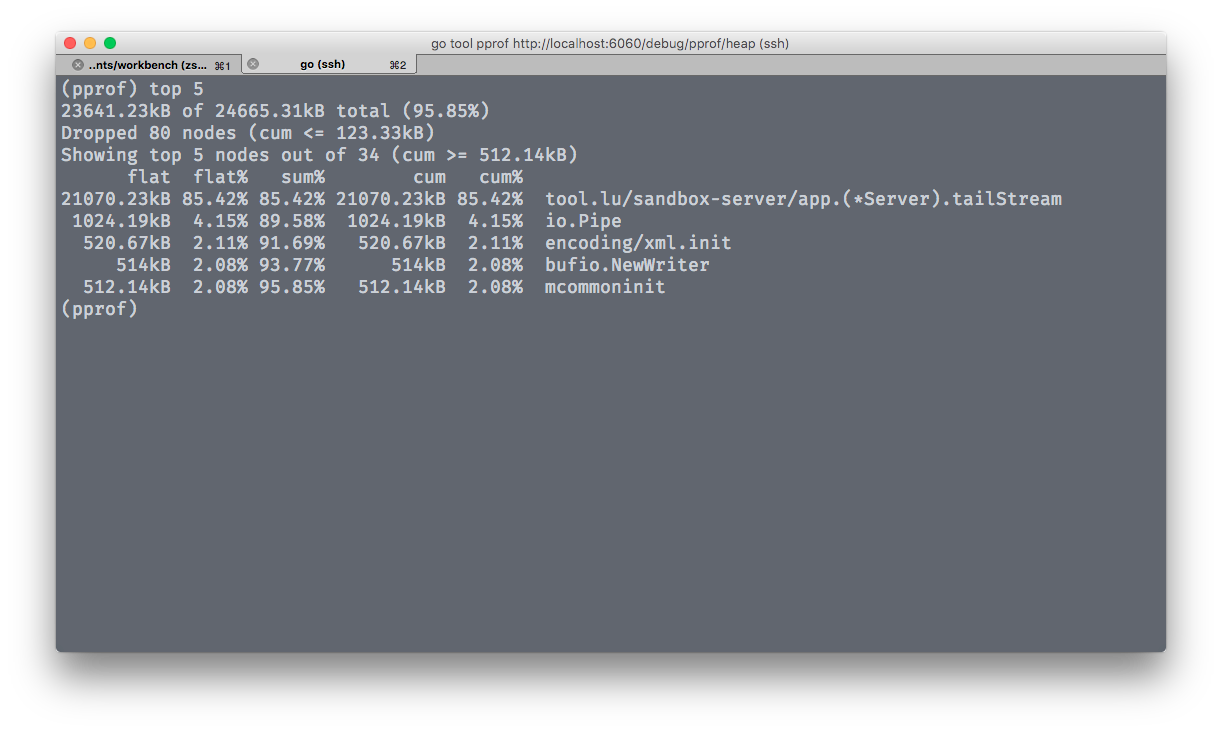
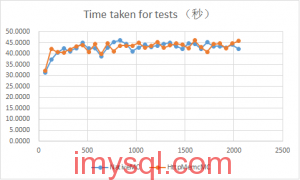
TPS及计算方法
这篇围绕TPS(每秒事务数)及其计算方法展开。文章首先明确了TPS的基本定义,并通过一个简单示例说明了如何基于事务数量和响应时间(节拍)来计算。 接着,文章引入了经典的利特尔法则,并详细解释了其在生产环境中的应用逻辑。作者通过两个生动的示例——一个是关于并发服务器容量规划,另一个是排队问题——展示了如何利用该法则推导系统行为,指出提升性能的关键在于增加并发处理量或缩短处理时间。 更进一步,文章探讨了在负载模型中影响TPS的两个关键因子:响应时间和节拍。通过具体示例对比了当节拍为零与不为零时,TPS受谁主导,进而推导出负载模型中利特尔法则的扩展公式:系统内平均用户数 = (平均响应时间 + 思考时间)× 吞吐量。最后给出了一个具体的计算实例,清晰地呈现了各参数之间的关系。 掌握这些概念,对于准确进行性能评估与容量规划至关重要。