关于一次导入数据提示的MySQL server has gone away
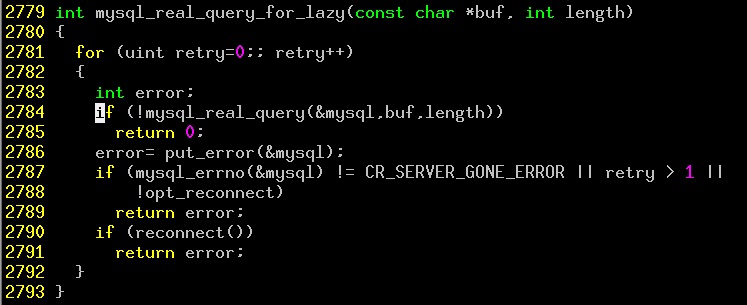
这篇讲的是一个看似平常的数据导入操作,如何引出对 MySQL 一个模糊报错的深度追查。作者从同事遇到的“MySQL server has gone away”问题出发,起初通过调大 `max_allowed_packet` 参数解决了表象。但作者敏锐地抓住了这个错误提示的“不友好”之处:并非所有包过大的情况都会报此错误,有时会有更明确的提示。 为了定位这类模糊报错的原因,作者没有停留在“突然想到”,而是设计了复现场景并深入到 MySQL 源码。分析发现,当 SQL 文件过大导致客户端发送网络包失败时,由于重连逻辑中的一处硬编码(`reconnect` 标志为0),MySQL 客户端库直接返回了 `CR_SERVER_GONE_ERROR`,从而掩盖了真正的错误——“发送通信包失败”。作者还展示了如何使用 GDB 调试获取被隐藏的真实错误码,为类似问题提供了系统的排查思路。 文章的核心在于揭示:一个不友好的错误提示背后,可能隐藏着完全不同的故障链路。与其猜测,不如顺着客户端的连接逻辑和错误处理流程去追溯,这才是定位复杂问题的可靠方法。