Redis和Memcached的区别
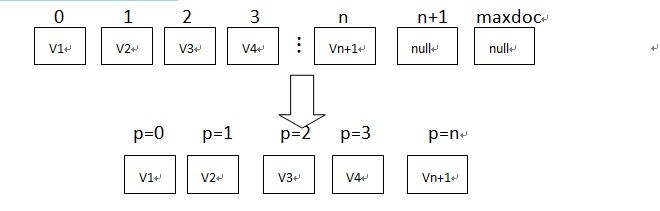
这篇讲的是Redis和Memcached这两种内存数据库的核心区别。文章从Redis作者的一个经典比较出发,清晰梳理了三者关键差异:首先,Redis支持String、Hash、List等更丰富的数据结构,可以在服务器端直接进行复杂操作,避免了Memcached需要将数据取回客户端修改的额外开销。其次,在内存效率上,若采用hash结构存储,Redis的组合压缩机制可能比Memcached更具优势。最后,性能表现各有特点:处理小数据时Redis的单核性能更优,而在100k以上的大数据场景中,Memcached的多核处理能力则略占上风。 文章随后深入剖析了Redis五种数据类型的实现原理,例如Hash内部如何根据成员数量自动转换存储结构,以及Set如何通过HashMap实现快速去重。这些细节不仅解释了差异背后的技术原因,也揭示了各自的设计考量。 总的来说,如果你的应用需要丰富的数据结构和复杂操作,Redis是更强大的选择;而如果是纯粹的、简单的大规模键值缓存,Memcached在内存利用和特定数据量级下的性能或许更合适。文章为技术选型提供了扎实的对比依据。