Java程序员应该知道的10个eclipse调试技巧
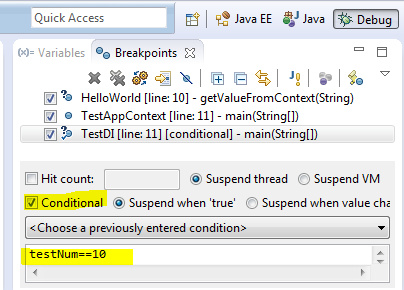
这是一篇面向Java开发者的Eclipse调试技巧系统性梳理。文章开篇就给出了三个高优先级建议:放弃System.out.println,转而启用并分析组件日志。核心内容则围绕十个具体、可操作的调试功能展开。 作者从基础的条件断点、异常断点讲起,逐步深入到监视点、变量值修改等高级操作。特别值得一提的是对“Drop to Frame”(返回堆栈帧)功能的讲解,它能让程序状态“回档”以便重复调试,但作者也提醒了其可能带来的副作用。最后,文章对F5、F6、F7、F8这四个最核心的调试快捷键进行了清晰归类,是入门和巩固的必备知识。 整篇文章的实用性很强,不仅罗列了“是什么”,更通过具体场景说明了“怎么用”以及“注意什么”,旨在帮助开发者更高效、精准地定位代码问题。