跨域访问和防盗链基本原理(一)
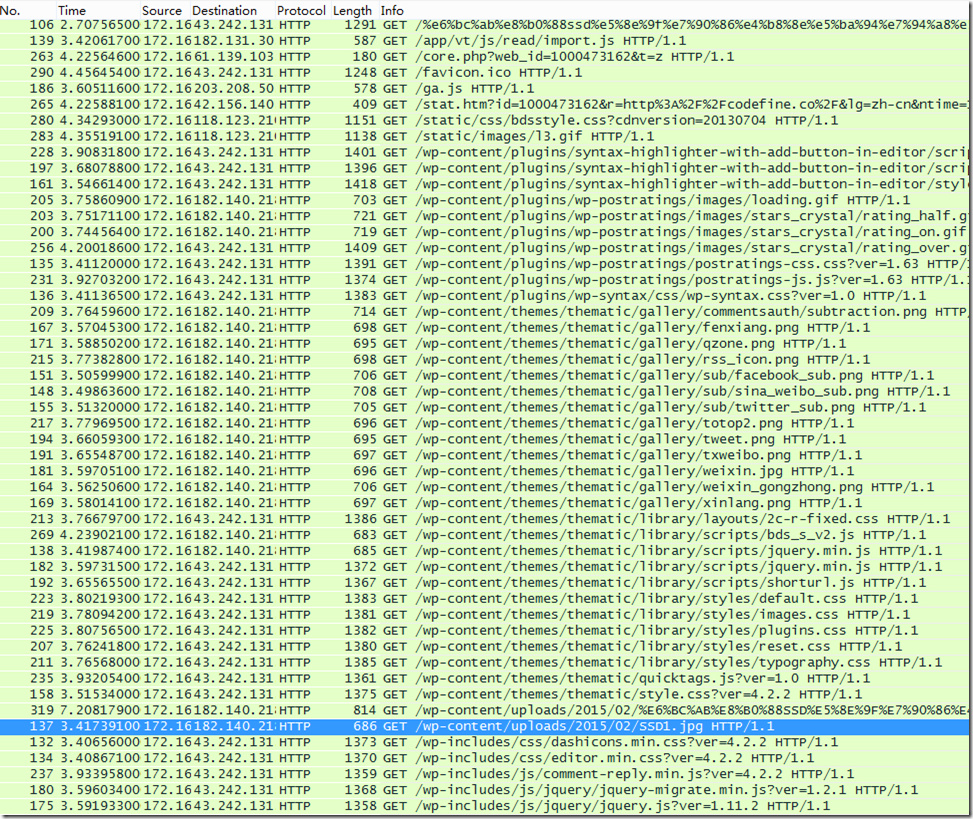
这篇讲的是防盗链的基本原理。作者从网页资源的加载过程切入,指出浏览器呈现一个完整页面需要发起大量GET请求,其中既包括本站资源,也可能包含非本站托管的外部资源。当网站A未经允许直接引用网站B的图片等资源,并从中获益时,就构成了“盗链”,这会消耗B站的流量。 文章核心对比了两种请求情况:直接访问页面时不会携带来源信息,而浏览器加载页面内的外部资源时,会自动在HTTP请求中加入`Referer`头,明确标示出请求的来源页面。资源服务器正是通过检查这个头域,来判断请求是否为本站或允许的来源。 对于非授权来源的请求,服务器可以拒绝提供资源,返回错误图片或提示信息,从而有效防止盗链。文章通过抓包截图直观展示了请求过程,清晰阐述了如何利用`Referer`机制实现基础防护,并为后续讨论跨域访问问题做了铺垫。