管理 Node.js 进程从未如此优雅
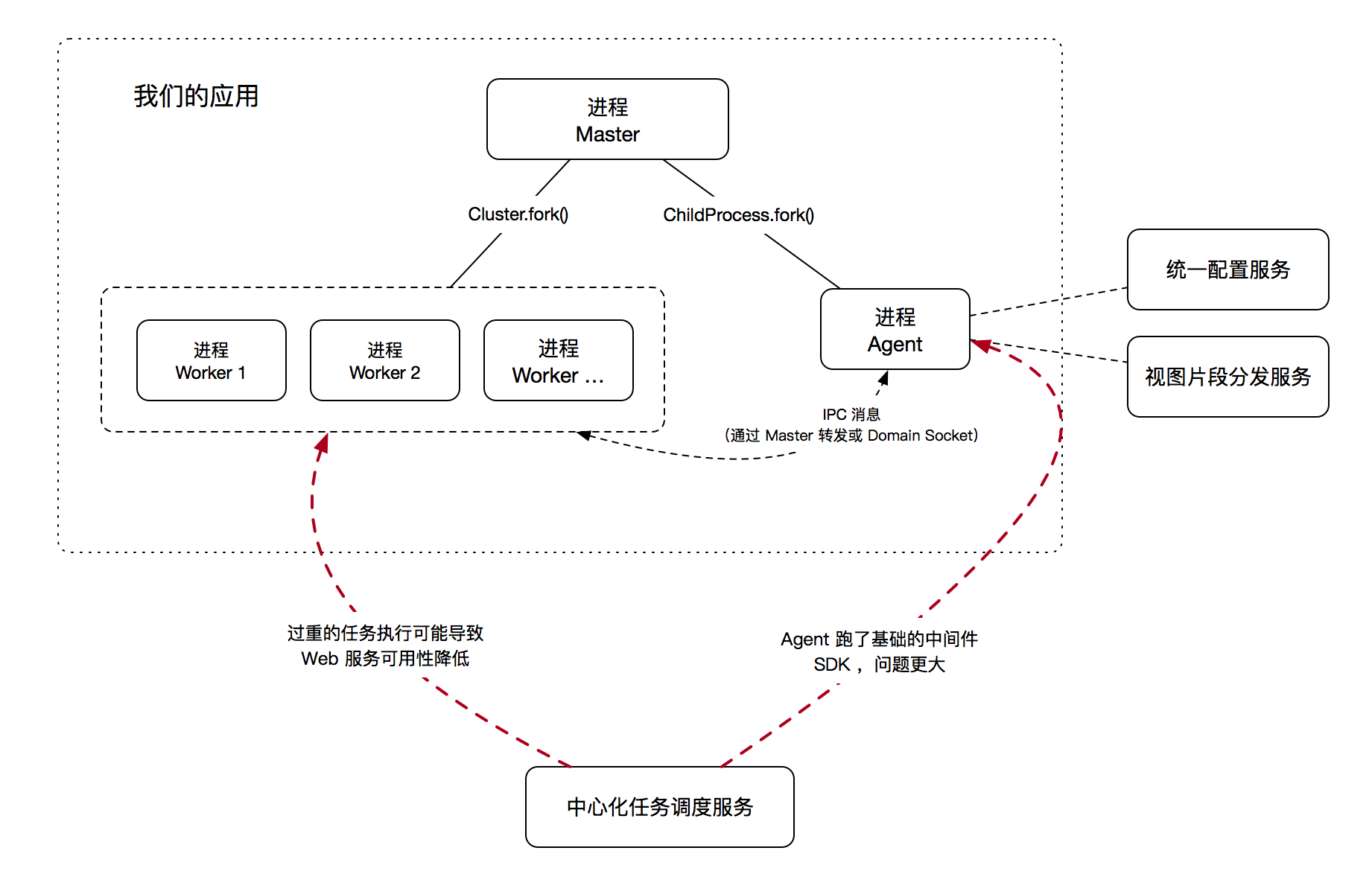
这篇讲的是 Node.js 进程管理长期存在的痛点,以及团队如何通过开发 Pandora.js 来提供一个更优雅的解决方案。 文章从传统 Cluster 或 Master/Worker 模型在实际应用中的局限性说起:增减进程困难、进程间通信复杂、定时任务可能拖垮主服务,更深层的问题是进程模型与框架绑定过深,限制了 Node.js 应用的扩展性(比如难以同时处理 Web 和 RPC 服务)。为了解决这些“修修补补”带来的窘境,团队推出了 Pandora.js。 其核心思路是引入一个名为 `procfile.js` 的进程结构定义文件,通过简单的代码(如 `pandora.fork('processA', './app.js')`)来声明进程,而将底层的创建、通信和伸缩交由框架自动处理。例如,通过 `scale(5)` 这样的属性就能自动完成 Cluster 模式的进程扩展,开发者无需关心具体实现。除了管理进程,Pandora.js 还提供了守护、日志切割、监控指标采集等一整套能力,为构建更健壮、可观测的 Node.js 应用打下了基础。 文章最后提到,这只是介绍 Pandora.js 的开始,后续还将分享其在监控、追踪和可视化 Dashboard 等方面的实践。