一些队列理论 吞吐量、延迟和带宽
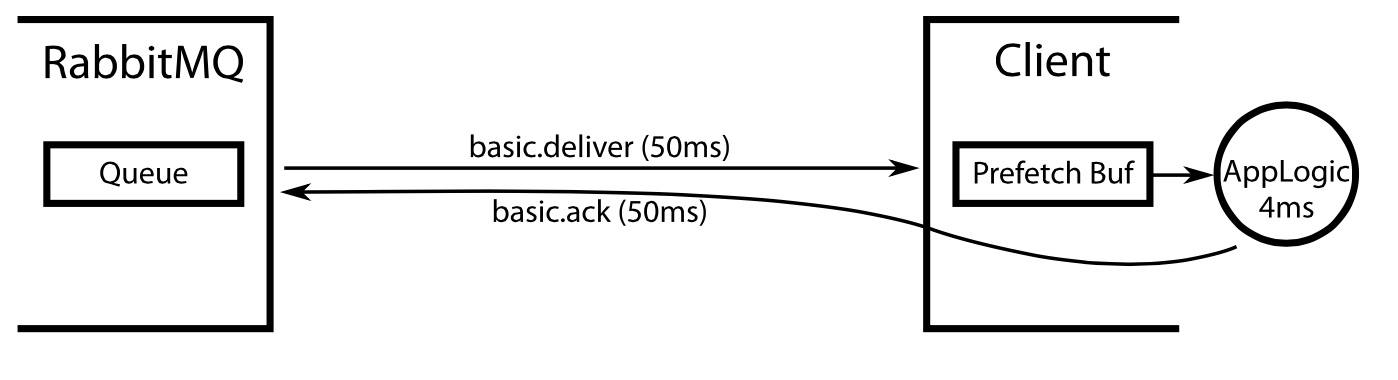
这篇讲的是消息队列(以RabbitMQ为例)中一个看似微小却影响深远的配置——消费者的QoS预取缓冲区大小。作者从一个实际问题出发:不加限制的预取消息会填满客户端内存,导致新消费者无法获取任务,但设置多大才算合适? 文章的核心在于用简单的队列理论来计算最优值。作者举了一个具体例子:网络往返104ms,客户端处理一条消息需4ms,那么预取26条消息刚好能让客户端持续忙碌,同时最小化消息在客户端的等待时间。但这只是理想情况。 真正的挑战在于网络延迟或客户端处理速度的波动。如果预取值太小,网络稍慢客户端就空闲;如果为保险起见把预取值加倍,又会在网络正常时引入大量无谓的排队延迟,甚至可能让消息在客户端滞留近2秒,严重影响实时性。 于是,文章引出了一个更聪明的方案:采用可变缓冲区的主动队列管理算法,如“延迟控制”(CoDel)。作者分享了自己在Java AMQP客户端上的实验性实现,它通过监控消息在客户端缓冲区中的等待时间,动态地将“滞留”过久的消息重新放回队列。这使得系统能在客户端处理速度下降时自动分流压力,而在网络正常时保持低延迟。 不过,作者也坦言这种方案在AMQP中并非完美,因为重新入队消息本身有开销。设置合理的参数以确保仅在异常时干预,是当前使用的关键。